re模块
目录
re模块说明
常用匹配字符
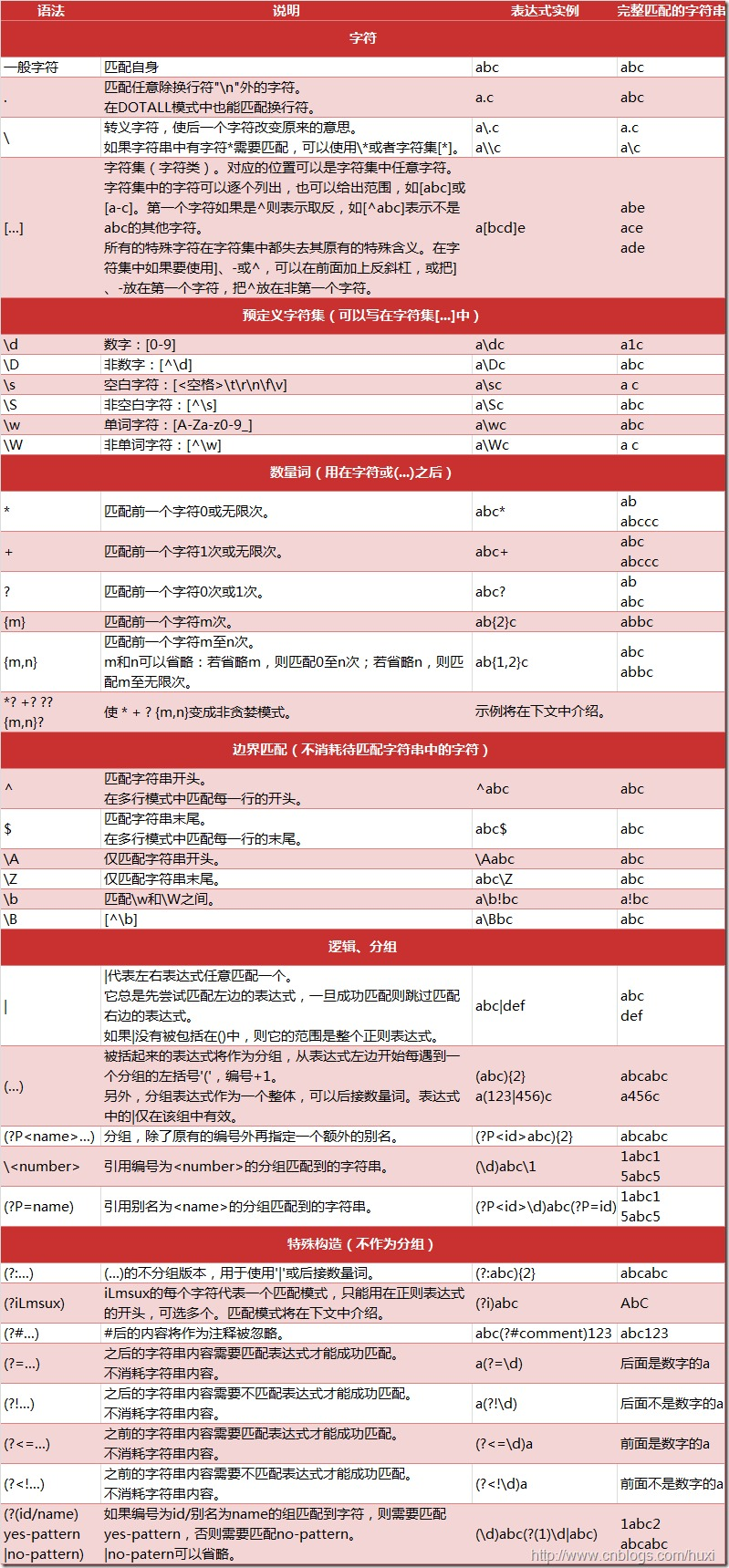
常用函数
########### 常用函数 ########### re.compile(pattern,flags=0) # 编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。) re.match(pattern, string, flags=0) # "决定RE是否在字符串刚开始的位置匹配。注:这个方法并不是完全匹配。当pattern结束时若string还有剩余字符,仍然视为成功。想要完全匹配,可以在表达式末尾加上边界匹配符'$'" re.search(pattern, string, flags=0) # re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。 """ 注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法: group() 返回被 RE 匹配的字符串 start() 返回匹配开始的位置 end() 返回匹配结束的位置 span() 返回一个元组包含匹配 (开始,结束) 的位置 group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。 1.group()返回re整体匹配的字符串, 2.group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常 3.groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组。 """ re.findall(pattern, string, flags=0) # re.findall遍历匹配,可以获取字符串中所有匹配的字符串,返回一个列表。 re.finditer(pattern, string, flags=0) # 搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。找到 RE 匹配的所有子串,并把它们作为一个迭代器返回。 re.split(pattern, string[, maxsplit]) # "按照能够匹配的子串将string分割后返回列表。可以使用re.split来分割字符串,如:re.split(r'\s+', text);将字符串按空格分割成一个单词列表。" re.sub(pattern, repl, string, count) # 使用re替换string中每一个匹配的子串后返回替换后的字符串。 re.subn(pattern, repl, string, count=0, flags=0) # 返回替换次数
########### flag位,匹配模式 ########### re.S(DOTALL) # 使.匹配包括换行在内的所有字符 re.I(IGNORECASE) # 忽略大小写 re.L(LOCALE) # 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定 re.M(MULTILINE) # 多行匹配,影响^和$ re.X(VERBOSE) # 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。 re.U # 使预定字符类 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
注意事项
compile用法
re模块中compile用于生成pattern的对象,再通过调用pattern实例的match方法处理文本最终获得match实例;通过使用match获得信息;
import re # 将正则表达式编译成Pattern对象 pattern = re.compile(r'rlovep') # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None m = pattern.match('rlovep.com') s = pattern.search('rlovep.com') f = pattern.findall('rlovep.com') if m: # 使用Match获得分组信息 print(m.group()) ### 输出 ### # rlovep if s: # 使用Search获得分组信息 print(s.group()) ### 输出 ### # rlovep print(f) # ['rlovep']
re.match与re.search与re.findall的区别
re.match:只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None。
re.search:匹配整个字符串,直到找到一个匹配,返回该字符串。
re.findall:匹配整个字符串,返回列表。
a=re.search('[\d]',"abc33").group() print(a) p=re.match('[\d]',"abc33") print(p) b=re.findall('[\d]',"abc33") print(b) 执行结果: None ['3', '3']
贪婪匹配与非贪婪匹配
*?,+?,??,{m,n}? 前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
a = re.findall(r"a(\d+?)",'a23b') # 非贪婪匹配 print(a) b = re.findall(r"a(\d+)",'a23b') print(b) 执行结果: ['2'] ['23'] a = re.match('<(.*)>','<H1>title<H1>').group() print(a) b = re.match('<(.*?)>','<H1>title<H1>').group() print(b) 执行结果: <H1>title<H1> <H1>
flags时的小坑
print(re.split('a','1A1a2A3',re.I))#输出结果并未能区分大小写 这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。如果想让这里的re.I起作用,写成flags=re.I即可。
示例


# =================================匹配模式================================= #一对一的匹配 # 'hello'.replace(old,new) # 'hello'.find('pattern') #正则匹配 import re #\w与\W print(re.findall('\w','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] print(re.findall('\W','hello egon 123')) #[' ', ' '] #\s与\S print(re.findall('\s','hello egon 123')) #[' ', ' ', ' ', ' '] print(re.findall('\S','hello egon 123')) #['h', 'e', 'l', 'l', 'o', 'e', 'g', 'o', 'n', '1', '2', '3'] #\n \t都是空,都可以被\s匹配 print(re.findall('\s','hello \n egon \t 123')) #[' ', '\n', ' ', ' ', '\t', ' '] #\n与\t print(re.findall(r'\n','hello egon \n123')) #['\n'] print(re.findall(r'\t','hello egon\t123')) #['\t'] #\d与\D print(re.findall('\d','hello egon 123')) #['1', '2', '3'] print(re.findall('\D','hello egon 123')) #['h', 'e', 'l', 'l', 'o', ' ', 'e', 'g', 'o', 'n', ' '] #\A与\Z print(re.findall('\Ahe','hello egon 123')) #['he'],\A==>^ print(re.findall('123\Z','hello egon 123')) #['he'],\Z==>$ #^与$ print(re.findall('^h','hello egon 123')) #['h'] print(re.findall('3$','hello egon 123')) #['3'] # 重复匹配:| . | * | ? | .* | .*? | + | {n,m} | #. print(re.findall('a.b','a1b')) #['a1b'] print(re.findall('a.b','a1b a*b a b aaab')) #['a1b', 'a*b', 'a b', 'aab'] print(re.findall('a.b','a\nb')) #[] print(re.findall('a.b','a\nb',re.S)) #['a\nb'] print(re.findall('a.b','a\nb',re.DOTALL)) #['a\nb']同上一条意思一样 #* print(re.findall('ab*','bbbbbbb')) #[] print(re.findall('ab*','a')) #['a'] print(re.findall('ab*','abbbb')) #['abbbb'] #? print(re.findall('ab?','a')) #['a'] print(re.findall('ab?','abbb')) #['ab'] #匹配所有包含小数在内的数字 print(re.findall('\d+\.?\d*',"asdfasdf123as1.13dfa12adsf1asdf3")) #['123', '1.13', '12', '1', '3'] #.*默认为贪婪匹配 print(re.findall('a.*b','a1b22222222b')) #['a1b22222222b'] #.*?为非贪婪匹配:推荐使用 print(re.findall('a.*?b','a1b22222222b')) #['a1b'] #+ print(re.findall('ab+','a')) #[] print(re.findall('ab+','abbb')) #['abbb'] #{n,m} print(re.findall('ab{2}','abbb')) #['abb'] print(re.findall('ab{2,4}','abbb')) #['abbb'] print(re.findall('ab{1,}','abbb')) #'ab{1,}' ===> 'ab+' ['abbb'] print(re.findall('ab{0,}','abbb')) #'ab{0,}' ===> 'ab*' ['abbb'] #[] print(re.findall('a[1*-]b','a1b a*b a-b')) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾 ['a1b', 'a*b', 'a-b'] print(re.findall('a[^1*-]b','a1b a*b a-b a=b')) #[]内的^代表的意思是取反,所以结果为['a=b'] print(re.findall('a[0-9]b','a1b a*b a-b a=b')) #结果为['a1b'] print(re.findall('a[a-z]b','a1b a*b a-b a=b aeb')) #结果为['aeb'] print(re.findall('a[a-zA-Z]b','a1b a*b a-b a=b aeb aEb')) #结果为['aeb', 'aEb'] #\# print(re.findall('a\\c','a\c')) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常 print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义['a\\c'] print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c'] #():分组 print(re.findall('ab+','ababab123')) #['ab', 'ab', 'ab'] print(re.findall('(ab)+123','ababab123')) #['ab'],匹配到末尾的ab123中的ab print(re.findall('(?:ab)+123','ababab123')) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容['ababab123'] print(re.findall('href="(.*?)"','<a href="http://www.baidu.com">点击</a>'))#['http://www.baidu.com'] print(re.findall('href="(?:.*?)"','<a href="http://www.baidu.com">点击</a>'))#['href="http://www.baidu.com"'] print(re.findall(r'-?\d+\.?\d*',"1-12*(60+(-40.35/5)-(-4*3))")) #找出所有数字['1', '-12', '60', '-40.35', '5', '-4', '3'] #使用|,先匹配的先生效,|左边是匹配小数,而findall最终结果是查看分组,所有即使匹配成功小数也不会存入结果 #而不是小数时,就去匹配(-?\d+),匹配到的自然就是,非小数的数,在此处即整数 print(re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")) #找出所有整数['1', '-2', '60', '', '5', '-4', '3'] #| print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company')) # ['companies', 'company'] # ?P<name> print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) #['h1'] print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) #<h1>hello</h1> print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").groupdict()) #<h1>hello</h1> print(re.search(r"<(\w+)>\w+</(\w+)>","<h1>hello</h1>").group()) print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group())
# ===========================re模块提供的方法介绍=========================== import re #1 print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里 #2 print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match #4 print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割 #5 print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有 print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love print('===>',re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)(.*?)$',r'\5\2\3\4\1','alex make love')) #===> love make alex print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数 #6 obj=re.compile('\d{2}') print(obj.search('abc123eeee').group()) #12 print(obj.findall('abc123eeee')) #['12'],重用了obj
import re # re.S 使.能匹配换行符 content='''Hello 123456 World_This is a Regex Demo ''' res=re.match('He.*?(\d+).*?Demo$',content) print(res) #输出None res=re.match('He.*?(\d+).*?Demo$',content,re.S) #re.S让.可以匹配换行符 print(res) # <_sre.SRE_Match object; span=(0, 39), match='Hello 123456 World_This\nis a Regex Demo'> print(res.group(1)) # 123456 # re.I 忽略大小写 content="""Hello World""" print(re.findall("hello world",content)) # [] print(re.findall("hello world",content,flags=re.I)) # ['Hello World'] print(re.findall("HELLO WORLD",content,flags=re.I)) # ['Hello World'] # 使用多个flags,在flag之间使用| content="""Hello World I am the KING""" print(re.findall("hel.*ing",content)) # [] print(re.findall("hel.*ing",content,flags=re.I)) # [] print(re.findall("hel.*ing",content,flags=re.S)) # [] print(re.findall("hel.*ing",content,flags=re.S|re.I)) # ['Hello World\nI am the KING'] # re.M 把字符串视为多行,从而^匹配每一行的行首,$匹配每一行的行尾 content = '''i am boy you are girl he is man''' print(re.findall(r"\w+$",content)) # ['man'] print(re.findall(r"\w+$",content,flags=re.M)) # ['boy', 'girl', 'man'] # re.X 正则表达式可为多行,忽略空格,可加备注 content = '''i am boy 123123123 he is man''' print(re.findall("""[a-z\s]+ # 这个是什么 [\d\s]+ # 匹配第二行的数字 [a-z\s]+ # 这个是什么 """,content,flags=re.X)) # ['i am boy\n123123123\nhe is man']
常用正则表达式
一、校验数字的表达式 1 数字:^[0-9]*$ 2 n位的数字:^\d{n}$ 3 至少n位的数字:^\d{n,}$ 4 m-n位的数字:^\d{m,n}$ 5 零和非零开头的数字:^(0|[1-9][0-9]*)$ 6 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$ 7 带1-2位小数的正数或负数:^(-)?\d+(.\d{1,2})?$ 8 正数、负数、和小数:^(-|+)?\d+(.\d+)?$ 9 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$ 10 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$ 11 非零的正整数:^[1-9]\d$ 或 ^([1-9][0-9]){1,3}$ 或 ^+?[1-9][0-9]*$ 12 非零的负整数:^-[1-9][]0-9"$ 或 ^-[1-9]\d$ 13 非负整数:^\d+$ 或 ^[1-9]\d*|0$ 14 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$ 15 非负浮点数:^\d+(.\d+)?$ 或 ^[1-9]\d.\d|0.\d[1-9]\d|0?.0+|0$ 16 非正浮点数:^((-\d+(.\d+)?)|(0+(.0+)?))$ 或 ^(-([1-9]\d.\d|0.\d[1-9]\d))|0?.0+|0$ 17 正浮点数:^[1-9]\d.\d|0.\d[1-9]\d$ 或 ^(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9]))$ 18 负浮点数:^-([1-9]\d.\d|0.\d[1-9]\d)$ 或 ^(-(([0-9]+.[0-9][1-9][0-9])|([0-9][1-9][0-9].[0-9]+)|([0-9][1-9][0-9])))$ 19 浮点数:^(-?\d+)(.\d+)?$ 或 ^-?([1-9]\d.\d|0.\d[1-9]\d|0?.0+|0)$ 二、校验字符的表达式 1 汉字:^[\u4e00-\u9fa5]{0,}$ 2 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$ 3 长度为3-20的所有字符:^.{3,20}$ 4 由26个英文字母组成的字符串:^[A-Za-z]+$ 5 由26个大写英文字母组成的字符串:^[A-Z]+$ 6 由26个小写英文字母组成的字符串:^[a-z]+$ 7 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$ 8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$ 9 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$ 10 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$ 11 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+ 12 禁止输入含有~的字符:[^~\x22]+ 三、特殊需求表达式 1 Email地址:^\w+([-+.]\w+)@\w+([-.]\w+).\w+([-.]\w+)*$ 2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? 3 InternetURL:[a-zA-z]+://[^\s] 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=])?$ 4 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ 5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^((\d{3,4}-)|\d{3.4}-)?\d{7,8}$ 6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7} 7 身份证号(15位、18位数字):^\d{15}|\d{18}$ 8 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$ 9 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$ 10 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$ 11 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.\d)(?=.[a-z])(?=.*[A-Z]).{8,10}$ 12 日期格式:^\d{4}-\d{1,2}-\d{1,2} 13 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$ 14 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$ 15 钱的输入格式: 16 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$ 17 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$ 18 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$ 19 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$ 20 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$ 21 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$ 22 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$ 23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$ 24 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里 25 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\.[x|X][m|M][l|L]$ 26 中文字符的正则表达式:[\u4e00-\u9fa5] 27 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)) 28 空白行的正则表达式:\n\s*\r (可以用来删除空白行) 29 HTML标记的正则表达式:<(\S?)[^>]>.?</\1>|<.? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力) 30 首尾空白字符的正则表达式:^\s|\s$或(^\s)|(\s$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式) 31 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始) 32 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字) 33 IP地址:\d+.\d+.\d+.\d+ (提取IP地址时有用) 34 IP地址:((?:(?:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d))
1 . 校验密码强度 密码的强度必须是包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间。 ^(?=.*\\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$ 2. 校验中文 字符串仅能是中文。 ^[\\u4e00-\\u9fa5]{0,}$ 3. 由数字、26个英文字母或下划线组成的字符串 ^\\w+$ 4. 校验E-Mail 地址 同密码一样,下面是E-mail地址合规性的正则检查语句。 [\\w!#$%&'*+/=?^_`{|}~-]+(?:\\.[\\w!#$%&'*+/=?^_`{|}~-]+)*@(?:[\\w](?:[\\w-]*[\\w])?\\.)+[\\w](?:[\\w-]*[\\w])? 5. 校验身份证号码 下面是身份证号码的正则校验。15 或 18位。 15位: ^[1-9]\\d{7}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}$ 18位: ^[1-9]\\d{5}[1-9]\\d{3}((0\\d)|(1[0-2]))(([0|1|2]\\d)|3[0-1])\\d{3}([0-9]|X)$ 6. 校验日期 “yyyy-mm-dd“ 格式的日期校验,已考虑平闰年。 ^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$ 7. 校验金额 金额校验,精确到2位小数。 ^[0-9]+(.[0-9]{2})?$ 8. 校验手机号 下面是国内 13、15、18开头的手机号正则表达式。(可根据目前国内收集号扩展前两位开头号码) ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\\d{8}$ 9. 判断IE的版本 IE目前还没被完全取代,很多页面还是需要做版本兼容,下面是IE版本检查的表达式。 ^.*MSIE [5-8](?:\\.[0-9]+)?(?!.*Trident\\/[5-9]\\.0).*$ 10. 校验IP-v4地址 IP4 正则语句。 \\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\b 11. 校验IP-v6地址 IP6 正则语句。 (([0-9a-fA-F]{1,4}:){7,7}[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,7}:|([0-9a-fA-F]{1,4}:){1,6}:[0-9a-fA-F]{1,4}|([0-9a-fA-F]{1,4}:){1,5}(:[0-9a-fA-F]{1,4}){1,2}|([0-9a-fA-F]{1,4}:){1,4}(:[0-9a-fA-F]{1,4}){1,3}|([0-9a-fA-F]{1,4}:){1,3}(:[0-9a-fA-F]{1,4}){1,4}|([0-9a-fA-F]{1,4}:){1,2}(:[0-9a-fA-F]{1,4}){1,5}|[0-9a-fA-F]{1,4}:((:[0-9a-fA-F]{1,4}){1,6})|:((:[0-9a-fA-F]{1,4}){1,7}|:)|fe80:(:[0-9a-fA-F]{0,4}){0,4}%[0-9a-zA-Z]{1,}|::(ffff(:0{1,4}){0,1}:){0,1}((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])|([0-9a-fA-F]{1,4}:){1,4}:((25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])\\.){3,3}(25[0-5]|(2[0-4]|1{0,1}[0-9]){0,1}[0-9])) 12. 检查URL的前缀 应用开发中很多时候需要区分请求是HTTPS还是HTTP,通过下面的表达式可以取出一个url的前缀然后再逻辑判断。 if (!s.match(/^[a-zA-Z]+:\\/\\//)) { s = 'http://' + s; } 13. 提取URL链接 下面的这个表达式可以筛选出一段文本中的URL。 ^(f|ht){1}(tp|tps):\\/\\/([\\w-]+\\.)+[\\w-]+(\\/[\\w- ./?%&=]*)? 14. 文件路径及扩展名校验 验证windows下文件路径和扩展名(下面的例子中为.txt文件) ^([a-zA-Z]\\:|\\\\)\\\\([^\\\\]+\\\\)*[^\\/:*?"<>|]+\\.txt(l)?$ 15. 提取Color Hex Codes 有时需要抽取网页中的颜色代码,可以使用下面的表达式。 ^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$ 16. 提取网页图片 假若你想提取网页中所有图片信息,可以利用下面的表达式。 \\< *[img][^\\\\>]*[src] *= *[\\"\\']{0,1}([^\\"\\'\\ >]*) 17. 提取页面超链接 提取html中的超链接。 (<a\\s*(?!.*\\brel=)[^>]*)(href="https?:\\/\\/)((?!(?:(?:www\\.)?'.implode('|(?:www\\.)?', $follow_list).'))[^"]+)"((?!.*\\brel=)[^>]*)(?:[^>]*)> 18. 查找CSS属性 通过下面的表达式,可以搜索到相匹配的CSS属性。 ^\\s*[a-zA-Z\\-]+\\s*[:]{1}\\s[a-zA-Z0-9\\s.#]+[;]{1} 19. 抽取注释 如果你需要移除HMTL中的注释,可以使用如下的表达式。 <!--(.*?)--> 20. 匹配HTML标签 通过下面的表达式可以匹配出HTML中的标签属性。 <\\/?\\w+((\\s+\\w+(\\s*=\\s*(?:".*?"|'.*?'|[\\^'">\\s]+))?)+\\s*|\\s*)\\/?>
参考or转发
https://www.cnblogs.com/tina-python/p/5508402.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号