python之模块_随手记录的模块
目录
1、StringIO
(1)使用
from io import stringio
StringIO模块主要用于在内存缓冲区中读写数据。


1、read 用法: s.read([n]):参数n用于限定读取的长度,类型为int,默认为从当前位置读取对象s中所有的数据。读取结束后,位置被移动。 2、readline 用法: s.readline([length]):length用于限定读取的结束位置,类型为int,缺省为None,即从当前位置读取至下一个以'\n'为结束符的当前行。读位置被移动。 3、readlines 用法: s.readlines():读取所有行 4、write 用法: s.write(s):从读写位置将参数s写入到对象s。参数为str或unicode类型,读写位置被移动。 5、writeline 用法: s.writeline(s):从读写位置将list写入给对象s。参数list为一个列表,列表的成员为str或unicode类型。读写位置被移动 6、getvalue 用法: s.getvalue():返回对象s中的所有数据 7、truncate 用法: s.truncate([size]):从读写位置起切断数据,参数size限定裁剪长度,默认为None 8、tell 用法: s.tell() #返回当前读写位置 9、seek 用法: s.seek(pos[,mode]):移动当前读写位置至pos处,可选参数mode为0时将读写位置移动到pos处,为1时将读写位置从当前位置移动pos个长度,为2时读写位置置于末尾处再向后移动pos个长度。默认为0 10、close 用法: s.close():释放缓冲区,执行此函数后,数据将被释放,也不可再进行操作。 11、isatty 用法: s.isatty():此函数总是返回0。不论StringIO对象是否已被close。 12、flush 用法: s.flush():刷新缓冲区。
from io import StringIO # StringIO还有一个对应的c语言版的实现,它有更好的性能,但是稍有一点点的区别: # cStringIO没有len和pos属性。(还有,cStringIO不支持Unicode编码) # 如果实例化一个带有默认数据的cStringIO.StringIO类。那么该实例是read-only的; # 无默认参数的是cStringIO.StringO,它是可读写的。cs = cStringIO.StringO() # StringIO模块主要用于在内存缓冲区中读写数据。模块是用类编写的,只有一个StringIO类, # 所以它的可用方法都在类中。此类中的大部分函数都与对文件的操作方法类似。 s = StringIO() s.write("www.baidu.com\n") s.write("news.realsil.com.cn") # getvalue() 方法用于获取写入后的str print(s.getvalue()) # 也可以像读取文件一样读取StringIO中的数据 s.seek(0) while True: strBuf = s.readline() if strBuf == "": break print(strBuf.strip()) s.close() # 可以用一个str初始化StringIO ss = StringIO("Hello!\nGoodBay!") print(ss.read()) ss.close() # StringIO 模块中的函数: # s.read([n]) # 参数n限定读取长度,int类型;缺省状态为从当前读写位置读取对象s中存储的所有数据。读取结束后,读写位置被移动。 # # ---------------------- # s.readline([length]) # 参数length限定读取的结束位置,int类型,缺省状态为None:从当前读写位置读取至下一个以“\n”为结束符的当前行。读写位置被移动。 # # ---------------------- # # s.readlines([sizehint]) # 参数sizehint为int类型,缺省状态为读取所有行并作为列表返回,除此之外从当前读写位置读取至下一个以“\n”为结束符的当前行。读写位置被移动。 # # ---------------------- # s.write(s) # 从读写位置将参数s写入给对象s。参数s为str或unicode类型。读写位置被移动。 # # ---------------------- # s.writelines(list) # 从读写位置将list写入给对象s。参数list为一个列表,列表的成员为str或unicode类型。读写位置被移动。 # # ---------------------- # s.getvalue() # 此函数没有参数,返回对象s中的所有数据。 # # ---------------------- # s.truncate([size]) # 从读写位置起切断数据,参数size限定裁剪长度,缺省值为None。 # # ---------------------- # s.tell() # 返回当前读写位置。 # # ---------------------- # s.seek(pos[,mode]) # 移动当前读写位置至pos处,可选参数mode为0时将读写位置移动至pos处,为1时将读写位置从当前位置起向后移动pos个长度, # 为2时将读写位置置于末尾处再向后移动pos个长度;默认为0。 # # ---------------------- # s.close() # 释放缓冲区,执行此函数后,数据将被释放,也不可再进行操作。 # # ---------------------- # s.isatty() # 此函数总是返回0。不论StringIO对象是否已被close()。 # # ---------------------- # s.flush() # 刷新内部缓冲区。 from io import BytesIO # StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。 b = BytesIO() b.write("hello".encode("utf-8")) print(b.getvalue()) b.close()
2、string
(1)使用
import string
1 """A collection of string operations (most are no longer used). 2 3 Warning: most of the code you see here isn't normally used nowadays. 4 Beginning with Python 1.6, many of these functions are implemented as 5 methods on the standard string object. They used to be implemented by 6 a built-in module called strop, but strop is now obsolete itself. 7 8 Public module variables: 9 10 whitespace -- a string containing all characters considered whitespace 11 lowercase -- a string containing all characters considered lowercase letters 12 uppercase -- a string containing all characters considered uppercase letters 13 letters -- a string containing all characters considered letters 14 digits -- a string containing all characters considered decimal digits 15 hexdigits -- a string containing all characters considered hexadecimal digits 16 octdigits -- a string containing all characters considered octal digits 17 punctuation -- a string containing all characters considered punctuation 18 printable -- a string containing all characters considered printable 19 20 """ 21 22 # Some strings for ctype-style character classification 23 whitespace = ' \t\n\r\v\f' 24 lowercase = 'abcdefghijklmnopqrstuvwxyz' 25 uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' 26 letters = lowercase + uppercase 27 ascii_lowercase = lowercase 28 ascii_uppercase = uppercase 29 ascii_letters = ascii_lowercase + ascii_uppercase 30 digits = '0123456789' 31 hexdigits = digits + 'abcdef' + 'ABCDEF' 32 octdigits = '01234567' 33 punctuation = """!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~""" 34 printable = digits + letters + punctuation + whitespace 35 36 # Case conversion helpers 37 # Use str to convert Unicode literal in case of -U 38 l = map(chr, xrange(256)) 39 _idmap = str('').join(l) 40 del l 41 42 # Functions which aren't available as string methods. 43 44 # Capitalize the words in a string, e.g. " aBc dEf " -> "Abc Def". 45 def capwords(s, sep=None): 46 """capwords(s [,sep]) -> string 47 48 Split the argument into words using split, capitalize each 49 word using capitalize, and join the capitalized words using 50 join. If the optional second argument sep is absent or None, 51 runs of whitespace characters are replaced by a single space 52 and leading and trailing whitespace are removed, otherwise 53 sep is used to split and join the words. 54 55 """ 56 return (sep or ' ').join(x.capitalize() for x in s.split(sep)) 57 58 59 # Construct a translation string 60 _idmapL = None 61 def maketrans(fromstr, tostr): 62 """maketrans(frm, to) -> string 63 64 Return a translation table (a string of 256 bytes long) 65 suitable for use in string.translate. The strings frm and to 66 must be of the same length. 67 68 """ 69 if len(fromstr) != len(tostr): 70 raise ValueError, "maketrans arguments must have same length" 71 global _idmapL 72 if not _idmapL: 73 _idmapL = list(_idmap) 74 L = _idmapL[:] 75 fromstr = map(ord, fromstr) 76 for i in range(len(fromstr)): 77 L[fromstr[i]] = tostr[i] 78 return ''.join(L) 79 80 81 82 #################################################################### 83 import re as _re 84 85 class _multimap: 86 """Helper class for combining multiple mappings. 87 88 Used by .{safe_,}substitute() to combine the mapping and keyword 89 arguments. 90 """ 91 def __init__(self, primary, secondary): 92 self._primary = primary 93 self._secondary = secondary 94 95 def __getitem__(self, key): 96 try: 97 return self._primary[key] 98 except KeyError: 99 return self._secondary[key] 100 101 102 class _TemplateMetaclass(type): 103 pattern = r""" 104 %(delim)s(?: 105 (?P<escaped>%(delim)s) | # Escape sequence of two delimiters 106 (?P<named>%(id)s) | # delimiter and a Python identifier 107 {(?P<braced>%(id)s)} | # delimiter and a braced identifier 108 (?P<invalid>) # Other ill-formed delimiter exprs 109 ) 110 """ 111 112 def __init__(cls, name, bases, dct): 113 super(_TemplateMetaclass, cls).__init__(name, bases, dct) 114 if 'pattern' in dct: 115 pattern = cls.pattern 116 else: 117 pattern = _TemplateMetaclass.pattern % { 118 'delim' : _re.escape(cls.delimiter), 119 'id' : cls.idpattern, 120 } 121 cls.pattern = _re.compile(pattern, _re.IGNORECASE | _re.VERBOSE) 122 123 124 class Template: 125 """A string class for supporting $-substitutions.""" 126 __metaclass__ = _TemplateMetaclass 127 128 delimiter = '$' 129 idpattern = r'[_a-z][_a-z0-9]*' 130 131 def __init__(self, template): 132 self.template = template 133 134 # Search for $$, $identifier, ${identifier}, and any bare $'s 135 136 def _invalid(self, mo): 137 i = mo.start('invalid') 138 lines = self.template[:i].splitlines(True) 139 if not lines: 140 colno = 1 141 lineno = 1 142 else: 143 colno = i - len(''.join(lines[:-1])) 144 lineno = len(lines) 145 raise ValueError('Invalid placeholder in string: line %d, col %d' % 146 (lineno, colno)) 147 148 def substitute(*args, **kws): 149 if not args: 150 raise TypeError("descriptor 'substitute' of 'Template' object " 151 "needs an argument") 152 self, args = args[0], args[1:] # allow the "self" keyword be passed 153 if len(args) > 1: 154 raise TypeError('Too many positional arguments') 155 if not args: 156 mapping = kws 157 elif kws: 158 mapping = _multimap(kws, args[0]) 159 else: 160 mapping = args[0] 161 # Helper function for .sub() 162 def convert(mo): 163 # Check the most common path first. 164 named = mo.group('named') or mo.group('braced') 165 if named is not None: 166 val = mapping[named] 167 # We use this idiom instead of str() because the latter will 168 # fail if val is a Unicode containing non-ASCII characters. 169 return '%s' % (val,) 170 if mo.group('escaped') is not None: 171 return self.delimiter 172 if mo.group('invalid') is not None: 173 self._invalid(mo) 174 raise ValueError('Unrecognized named group in pattern', 175 self.pattern) 176 return self.pattern.sub(convert, self.template) 177 178 def safe_substitute(*args, **kws): 179 if not args: 180 raise TypeError("descriptor 'safe_substitute' of 'Template' object " 181 "needs an argument") 182 self, args = args[0], args[1:] # allow the "self" keyword be passed 183 if len(args) > 1: 184 raise TypeError('Too many positional arguments') 185 if not args: 186 mapping = kws 187 elif kws: 188 mapping = _multimap(kws, args[0]) 189 else: 190 mapping = args[0] 191 # Helper function for .sub() 192 def convert(mo): 193 named = mo.group('named') or mo.group('braced') 194 if named is not None: 195 try: 196 # We use this idiom instead of str() because the latter 197 # will fail if val is a Unicode containing non-ASCII 198 return '%s' % (mapping[named],) 199 except KeyError: 200 return mo.group() 201 if mo.group('escaped') is not None: 202 return self.delimiter 203 if mo.group('invalid') is not None: 204 return mo.group() 205 raise ValueError('Unrecognized named group in pattern', 206 self.pattern) 207 return self.pattern.sub(convert, self.template) 208 209 210 211 #################################################################### 212 # NOTE: Everything below here is deprecated. Use string methods instead. 213 # This stuff will go away in Python 3.0. 214 215 # Backward compatible names for exceptions 216 index_error = ValueError 217 atoi_error = ValueError 218 atof_error = ValueError 219 atol_error = ValueError 220 221 # convert UPPER CASE letters to lower case 222 def lower(s): 223 """lower(s) -> string 224 225 Return a copy of the string s converted to lowercase. 226 227 """ 228 return s.lower() 229 230 # Convert lower case letters to UPPER CASE 231 def upper(s): 232 """upper(s) -> string 233 234 Return a copy of the string s converted to uppercase. 235 236 """ 237 return s.upper() 238 239 # Swap lower case letters and UPPER CASE 240 def swapcase(s): 241 """swapcase(s) -> string 242 243 Return a copy of the string s with upper case characters 244 converted to lowercase and vice versa. 245 246 """ 247 return s.swapcase() 248 249 # Strip leading and trailing tabs and spaces 250 def strip(s, chars=None): 251 """strip(s [,chars]) -> string 252 253 Return a copy of the string s with leading and trailing 254 whitespace removed. 255 If chars is given and not None, remove characters in chars instead. 256 If chars is unicode, S will be converted to unicode before stripping. 257 258 """ 259 return s.strip(chars) 260 261 # Strip leading tabs and spaces 262 def lstrip(s, chars=None): 263 """lstrip(s [,chars]) -> string 264 265 Return a copy of the string s with leading whitespace removed. 266 If chars is given and not None, remove characters in chars instead. 267 268 """ 269 return s.lstrip(chars) 270 271 # Strip trailing tabs and spaces 272 def rstrip(s, chars=None): 273 """rstrip(s [,chars]) -> string 274 275 Return a copy of the string s with trailing whitespace removed. 276 If chars is given and not None, remove characters in chars instead. 277 278 """ 279 return s.rstrip(chars) 280 281 282 # Split a string into a list of space/tab-separated words 283 def split(s, sep=None, maxsplit=-1): 284 """split(s [,sep [,maxsplit]]) -> list of strings 285 286 Return a list of the words in the string s, using sep as the 287 delimiter string. If maxsplit is given, splits at no more than 288 maxsplit places (resulting in at most maxsplit+1 words). If sep 289 is not specified or is None, any whitespace string is a separator. 290 291 (split and splitfields are synonymous) 292 293 """ 294 return s.split(sep, maxsplit) 295 splitfields = split 296 297 # Split a string into a list of space/tab-separated words 298 def rsplit(s, sep=None, maxsplit=-1): 299 """rsplit(s [,sep [,maxsplit]]) -> list of strings 300 301 Return a list of the words in the string s, using sep as the 302 delimiter string, starting at the end of the string and working 303 to the front. If maxsplit is given, at most maxsplit splits are 304 done. If sep is not specified or is None, any whitespace string 305 is a separator. 306 """ 307 return s.rsplit(sep, maxsplit) 308 309 # Join fields with optional separator 310 def join(words, sep = ' '): 311 """join(list [,sep]) -> string 312 313 Return a string composed of the words in list, with 314 intervening occurrences of sep. The default separator is a 315 single space. 316 317 (joinfields and join are synonymous) 318 319 """ 320 return sep.join(words) 321 joinfields = join 322 323 # Find substring, raise exception if not found 324 def index(s, *args): 325 """index(s, sub [,start [,end]]) -> int 326 327 Like find but raises ValueError when the substring is not found. 328 329 """ 330 return s.index(*args) 331 332 # Find last substring, raise exception if not found 333 def rindex(s, *args): 334 """rindex(s, sub [,start [,end]]) -> int 335 336 Like rfind but raises ValueError when the substring is not found. 337 338 """ 339 return s.rindex(*args) 340 341 # Count non-overlapping occurrences of substring 342 def count(s, *args): 343 """count(s, sub[, start[,end]]) -> int 344 345 Return the number of occurrences of substring sub in string 346 s[start:end]. Optional arguments start and end are 347 interpreted as in slice notation. 348 349 """ 350 return s.count(*args) 351 352 # Find substring, return -1 if not found 353 def find(s, *args): 354 """find(s, sub [,start [,end]]) -> in 355 356 Return the lowest index in s where substring sub is found, 357 such that sub is contained within s[start,end]. Optional 358 arguments start and end are interpreted as in slice notation. 359 360 Return -1 on failure. 361 362 """ 363 return s.find(*args) 364 365 # Find last substring, return -1 if not found 366 def rfind(s, *args): 367 """rfind(s, sub [,start [,end]]) -> int 368 369 Return the highest index in s where substring sub is found, 370 such that sub is contained within s[start,end]. Optional 371 arguments start and end are interpreted as in slice notation. 372 373 Return -1 on failure. 374 375 """ 376 return s.rfind(*args) 377 378 # for a bit of speed 379 _float = float 380 _int = int 381 _long = long 382 383 # Convert string to float 384 def atof(s): 385 """atof(s) -> float 386 387 Return the floating point number represented by the string s. 388 389 """ 390 return _float(s) 391 392 393 # Convert string to integer 394 def atoi(s , base=10): 395 """atoi(s [,base]) -> int 396 397 Return the integer represented by the string s in the given 398 base, which defaults to 10. The string s must consist of one 399 or more digits, possibly preceded by a sign. If base is 0, it 400 is chosen from the leading characters of s, 0 for octal, 0x or 401 0X for hexadecimal. If base is 16, a preceding 0x or 0X is 402 accepted. 403 404 """ 405 return _int(s, base) 406 407 408 # Convert string to long integer 409 def atol(s, base=10): 410 """atol(s [,base]) -> long 411 412 Return the long integer represented by the string s in the 413 given base, which defaults to 10. The string s must consist 414 of one or more digits, possibly preceded by a sign. If base 415 is 0, it is chosen from the leading characters of s, 0 for 416 octal, 0x or 0X for hexadecimal. If base is 16, a preceding 417 0x or 0X is accepted. A trailing L or l is not accepted, 418 unless base is 0. 419 420 """ 421 return _long(s, base) 422 423 424 # Left-justify a string 425 def ljust(s, width, *args): 426 """ljust(s, width[, fillchar]) -> string 427 428 Return a left-justified version of s, in a field of the 429 specified width, padded with spaces as needed. The string is 430 never truncated. If specified the fillchar is used instead of spaces. 431 432 """ 433 return s.ljust(width, *args) 434 435 # Right-justify a string 436 def rjust(s, width, *args): 437 """rjust(s, width[, fillchar]) -> string 438 439 Return a right-justified version of s, in a field of the 440 specified width, padded with spaces as needed. The string is 441 never truncated. If specified the fillchar is used instead of spaces. 442 443 """ 444 return s.rjust(width, *args) 445 446 # Center a string 447 def center(s, width, *args): 448 """center(s, width[, fillchar]) -> string 449 450 Return a center version of s, in a field of the specified 451 width. padded with spaces as needed. The string is never 452 truncated. If specified the fillchar is used instead of spaces. 453 454 """ 455 return s.center(width, *args) 456 457 # Zero-fill a number, e.g., (12, 3) --> '012' and (-3, 3) --> '-03' 458 # Decadent feature: the argument may be a string or a number 459 # (Use of this is deprecated; it should be a string as with ljust c.s.) 460 def zfill(x, width): 461 """zfill(x, width) -> string 462 463 Pad a numeric string x with zeros on the left, to fill a field 464 of the specified width. The string x is never truncated. 465 466 """ 467 if not isinstance(x, basestring): 468 x = repr(x) 469 return x.zfill(width) 470 471 # Expand tabs in a string. 472 # Doesn't take non-printing chars into account, but does understand \n. 473 def expandtabs(s, tabsize=8): 474 """expandtabs(s [,tabsize]) -> string 475 476 Return a copy of the string s with all tab characters replaced 477 by the appropriate number of spaces, depending on the current 478 column, and the tabsize (default 8). 479 480 """ 481 return s.expandtabs(tabsize) 482 483 # Character translation through look-up table. 484 def translate(s, table, deletions=""): 485 """translate(s,table [,deletions]) -> string 486 487 Return a copy of the string s, where all characters occurring 488 in the optional argument deletions are removed, and the 489 remaining characters have been mapped through the given 490 translation table, which must be a string of length 256. The 491 deletions argument is not allowed for Unicode strings. 492 493 """ 494 if deletions or table is None: 495 return s.translate(table, deletions) 496 else: 497 # Add s[:0] so that if s is Unicode and table is an 8-bit string, 498 # table is converted to Unicode. This means that table *cannot* 499 # be a dictionary -- for that feature, use u.translate() directly. 500 return s.translate(table + s[:0]) 501 502 # Capitalize a string, e.g. "aBc dEf" -> "Abc def". 503 def capitalize(s): 504 """capitalize(s) -> string 505 506 Return a copy of the string s with only its first character 507 capitalized. 508 509 """ 510 return s.capitalize() 511 512 # Substring replacement (global) 513 def replace(s, old, new, maxreplace=-1): 514 """replace (str, old, new[, maxreplace]) -> string 515 516 Return a copy of string str with all occurrences of substring 517 old replaced by new. If the optional argument maxreplace is 518 given, only the first maxreplace occurrences are replaced. 519 520 """ 521 return s.replace(old, new, maxreplace) 522 523 524 # Try importing optional built-in module "strop" -- if it exists, 525 # it redefines some string operations that are 100-1000 times faster. 526 # It also defines values for whitespace, lowercase and uppercase 527 # that match <ctype.h>'s definitions. 528 529 try: 530 from strop import maketrans, lowercase, uppercase, whitespace 531 letters = lowercase + uppercase 532 except ImportError: 533 pass # Use the original versions 534 535 ######################################################################## 536 # the Formatter class 537 # see PEP 3101 for details and purpose of this class 538 539 # The hard parts are reused from the C implementation. They're exposed as "_" 540 # prefixed methods of str and unicode. 541 542 # The overall parser is implemented in str._formatter_parser. 543 # The field name parser is implemented in str._formatter_field_name_split 544 545 class Formatter(object): 546 def format(*args, **kwargs): 547 if not args: 548 raise TypeError("descriptor 'format' of 'Formatter' object " 549 "needs an argument") 550 self, args = args[0], args[1:] # allow the "self" keyword be passed 551 try: 552 format_string, args = args[0], args[1:] # allow the "format_string" keyword be passed 553 except IndexError: 554 if 'format_string' in kwargs: 555 format_string = kwargs.pop('format_string') 556 else: 557 raise TypeError("format() missing 1 required positional " 558 "argument: 'format_string'") 559 return self.vformat(format_string, args, kwargs) 560 561 def vformat(self, format_string, args, kwargs): 562 used_args = set() 563 result = self._vformat(format_string, args, kwargs, used_args, 2) 564 self.check_unused_args(used_args, args, kwargs) 565 return result 566 567 def _vformat(self, format_string, args, kwargs, used_args, recursion_depth): 568 if recursion_depth < 0: 569 raise ValueError('Max string recursion exceeded') 570 result = [] 571 for literal_text, field_name, format_spec, conversion in \ 572 self.parse(format_string): 573 574 # output the literal text 575 if literal_text: 576 result.append(literal_text) 577 578 # if there's a field, output it 579 if field_name is not None: 580 # this is some markup, find the object and do 581 # the formatting 582 583 # given the field_name, find the object it references 584 # and the argument it came from 585 obj, arg_used = self.get_field(field_name, args, kwargs) 586 used_args.add(arg_used) 587 588 # do any conversion on the resulting object 589 obj = self.convert_field(obj, conversion) 590 591 # expand the format spec, if needed 592 format_spec = self._vformat(format_spec, args, kwargs, 593 used_args, recursion_depth-1) 594 595 # format the object and append to the result 596 result.append(self.format_field(obj, format_spec)) 597 598 return ''.join(result) 599 600 601 def get_value(self, key, args, kwargs): 602 if isinstance(key, (int, long)): 603 return args[key] 604 else: 605 return kwargs[key] 606 607 608 def check_unused_args(self, used_args, args, kwargs): 609 pass 610 611 612 def format_field(self, value, format_spec): 613 return format(value, format_spec) 614 615 616 def convert_field(self, value, conversion): 617 # do any conversion on the resulting object 618 if conversion is None: 619 return value 620 elif conversion == 's': 621 return str(value) 622 elif conversion == 'r': 623 return repr(value) 624 raise ValueError("Unknown conversion specifier {0!s}".format(conversion)) 625 626 627 # returns an iterable that contains tuples of the form: 628 # (literal_text, field_name, format_spec, conversion) 629 # literal_text can be zero length 630 # field_name can be None, in which case there's no 631 # object to format and output 632 # if field_name is not None, it is looked up, formatted 633 # with format_spec and conversion and then used 634 def parse(self, format_string): 635 return format_string._formatter_parser() 636 637 638 # given a field_name, find the object it references. 639 # field_name: the field being looked up, e.g. "0.name" 640 # or "lookup[3]" 641 # used_args: a set of which args have been used 642 # args, kwargs: as passed in to vformat 643 def get_field(self, field_name, args, kwargs): 644 first, rest = field_name._formatter_field_name_split() 645 646 obj = self.get_value(first, args, kwargs) 647 648 # loop through the rest of the field_name, doing 649 # getattr or getitem as needed 650 for is_attr, i in rest: 651 if is_attr: 652 obj = getattr(obj, i) 653 else: 654 obj = obj[i] 655 656 return obj, first
string.whitespace # ' \t\n\r\v\f' string.ascii_lowercase # 'abcdefghijklmnopqrstuvwxyz' string.ascii_uppercase # 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' string.ascii_letters # 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ' string.digits # '0123456789' string.hexdigits # '0123456789abcdefABCDEF' string.octdigits # '01234567' string.punctuation # """!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~""" string.printable # '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c' # string.printable = digits + letters + punctuation + whitespace
3、pprint
(1)使用( pretty printer )
import pprint
- pprint(object, stream=None, indent=1, width=80, depth=None, *, compact=False)
1.class pprint.PrettyPrinter(indent=1,width=80,depth=None, stream=None) 创建一个PrettyPrinter对象 indent --- 缩进,width --- 一行最大宽度, depth --- 打印的深度,这个主要是针对一些可递归的对象,如果超出指定depth,其余的用"..."代替。 eg: a=[1,2,[3,4,],5] a的深度就是2; b=[1,2,[3,4,[5,6]],7,8] b的深度就是3 stream ---指输出流对象,如果stream=None,那么输出流对象默认是sys.stdout 2.pprint.pformat(object,indent=1,width=80, depth=None) 返回格式化的对象字符串 3.pprint.pprint(object,stream=None,indent=1, width=80, depth=None) 输出格式的对象字符串到指定的stream,最后以换行符结束。 4.pprint.isreadable(object) 判断对象object的字符串对象是否可读 5.pprint.isrecursive(object) 判断对象是否需要递归的表示 eg: pprint.isrecursive(a) --->False pprint.isrecursive([1,2,3])-->True 6.pprint.saferepr(object) 返回一个对象字符串,对象中的子对象如果是可递归的,都被替换成<Recursionontypename withid=number>.这种形式。
import pprint data = ( "this is a string", [1, 2, 3, 4], ("more tuples", 1.0, 2.3, 4.5), "this is yet another string" ) pprint.pprint(data) ''' ('this is a string', [1, 2, 3, 4], ('more tuples', 1.0, 2.3, 4.5), 'this is yet another string') ''' print(data) # ('this is a string', [1, 2, 3, 4], ('more tuples', 1.0, 2.3, 4.5), 'this is yet another string')
(2)参考
https://blog.csdn.net/hxpjava1/article/details/73379642
4、struct模块
(1)使用
该模块可以把一个类型,如数字,转成固定长度的bytes
>>> struct.pack('i',1111111111111)
。。。。。。。。。
struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
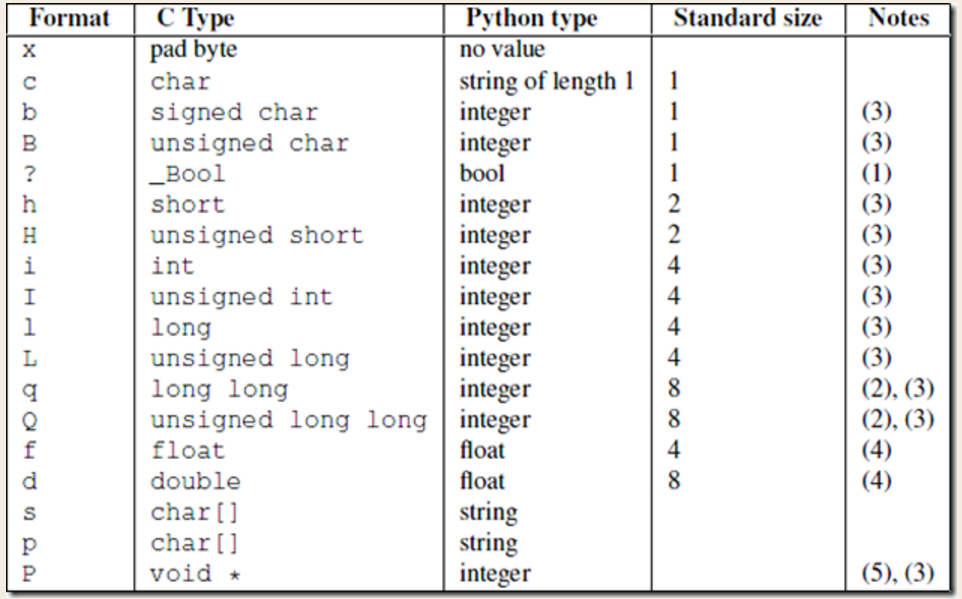
import json,struct #假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头 header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式 header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)
#_*_coding:utf-8_*_ import struct import binascii import ctypes values1 = (1, 'abc'.encode('utf-8'), 2.7) values2 = ('defg'.encode('utf-8'),101) s1 = struct.Struct('I3sf') s2 = struct.Struct('4sI') print(s1.size,s2.size) prebuffer=ctypes.create_string_buffer(s1.size+s2.size) print('Before : ',binascii.hexlify(prebuffer)) # t=binascii.hexlify('asdfaf'.encode('utf-8')) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct('ii') s3.pack_into(prebuffer,0,123,123) print('After pack',binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0))
(2)参考
http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html
5、uuid
(1)使用
import uuid
(2)实例
>>> import uuid # make a UUID based on the host ID and current time >>> uuid.uuid1() # doctest: +SKIP UUID('a8098c1a-f86e-11da-bd1a-00112444be1e') # make a UUID using an MD5 hash of a namespace UUID and a name >>> uuid.uuid3(uuid.NAMESPACE_DNS, 'python.org') UUID('6fa459ea-ee8a-3ca4-894e-db77e160355e') # make a random UUID >>> uuid.uuid4() # doctest: +SKIP UUID('16fd2706-8baf-433b-82eb-8c7fada847da') # make a UUID using a SHA-1 hash of a namespace UUID and a name >>> uuid.uuid5(uuid.NAMESPACE_DNS, 'python.org') UUID('886313e1-3b8a-5372-9b90-0c9aee199e5d') # make a UUID from a string of hex digits (braces and hyphens ignored) >>> x = uuid.UUID('{00010203-0405-0607-0809-0a0b0c0d0e0f}') # convert a UUID to a string of hex digits in standard form >>> str(x) '00010203-0405-0607-0809-0a0b0c0d0e0f' # get the raw 16 bytes of the UUID >>> x.bytes b'\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f' # make a UUID from a 16-byte string >>> uuid.UUID(bytes=x.bytes) UUID('00010203-0405-0607-0809-0a0b0c0d0e0f')
6、itertools
(1)使用
import itertools
(2)实例
""" itertools.product(*iterables[, repeat]) # 笛卡尔积 itertools.permutations(iterable[, r]) # 排列 itertools.combinations(iterable, r) # 组合 itertools.combinations_with_replacement(iterable, r) # 组合(包含自身重复) """ import itertools l = [1,2,3,4,5] iproduct = list(itertools.product(l, repeat = 3)) ipermutations = list(itertools.permutations(l,3)) icombinations = list(itertools.combinations(l,3)) icombinations_r = list(itertools.combinations_with_replacement(l,3)) print(iproduct) print(len(iproduct)) print(ipermutations) print(len(ipermutations)) print(icombinations) print(len(icombinations)) print(icombinations_r) print(len(icombinations_r))
7、prettytable
(1)使用
pip install prettytable
(2)实例
from prettytable import PrettyTable x = PrettyTable(["name","password", "age", "gender", ]) x.align["name"] = "l" # 以name字段左对齐 x.padding_width = 1 # 填充宽度 x.add_row(["tom","123",18, "M",]) x.add_row(["zhangwuji","123",500, "M",]) x.add_row(["messi","123",18, "M",]) print(x) ''' +-----------+----------+-----+--------+ | name | password | age | gender | +-----------+----------+-----+--------+ | tom | 123 | 18 | M | | zhangwuji | 123 | 500 | M | | messi | 123 | 18 | M | +-----------+----------+-----+--------+ '''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号