

k8s中的网络
一、网络前提条件-网络模型
- k8s组网要求
- 所有的Pods之间可以在不使用NAT网络地址转换的情况下相互通信
- 所有的Nodes之间可以在不使用NAT网络地址转换的情况下相互通信
- 每个Pod自己看到的自己的ip和其他Pod看到的一致。换句话讲,所有Pod对象都处于同一平面网络中,而且使可以使用Pod自身的地址直接通信。
- k8s网络模型设计原则
- 每个Pod都拥有一个独立的 IP地址,而且 假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中
- 不管它们是否运行在同 一 个 Node (宿主机)中,都要求它们可以直接通过对方的 IP 进行访问
- 设计这个原则的原因 是,用户不需要额外考虑如何建立 Pod 之间的连接,也不需要考虑将容器端口映射到主机端口等问题
Kubernetes使用的网络插件必须能为Pod提供满足以上要求的网络,它需要为每个Pod配置至少一个特定的地址,即Pod IP。Pod IP地址实际存在于某个网卡(可以是虚拟设备)上,而service的地址却是一个虚拟IP地址,没有任何网络接口配置此地址,它由kube-proxy借助iptables规则或者IPVS规则重新定向到本地端口,在将其调度至后端Pod对象。Service的IP地址是集群提供服务的接口,也称为ClusterIP
Pod网络及其IP由kubernetes的网络插件负责配置和管理,具体使用的网络地址可在管理配置网络插件时指定,如10.244.0.0/16网络。而Cluster网络和IP则是由kubernetes集群负责管理和配置,如10.96.0.0/12网络
总结起来,kubernetes集群至少应该包含三个网络
1、各个主机之间的通信,如master与各node之间的通信,此地址配置与kunernetes集群构建之前,他不能由kubernetes管理,管理员需要于集群构建之前自行确定其地址配置及管理
2、kubernetes集群上专用于Pod资源对象的网络,他是一个虚拟网络,用于为各Pod对象设定IP地址等网络参数,其地址配置于Pod中容器的网络接口上,Pod网络需要借助kubernet插件或者CNI插件实现,该插件可独立不属于Kubernetes集群之外,亦可托管于Kubernetes之上,他需要在构建Kubernetes集群时由管理员定义,而后创建Pod对象时由其自动完成网络参数的动态配置。
3、专用语Service资源的对象的网络,它也是一个虚拟网络,用于Kubernetes集群之中的Service配置IP地址,但此地址并不配置于任何主机或容器的网络接口之上,而是通过Node之上的kube-proxy配置为iptables或ipvs规则,从而将发往此地址的所有流量调度至其后端的各个Pod对象之上。Service网络在Kubernetes集群创建时予以指定,而各Service的地址则在用户创建Service时予以动态配置。

二、需要解决的网络问题
根据以上的一些要求,需要解决的问题
- Docker容器和Docker容器之间的网络
- Pod与Pod之间的网络
- Pod与Service之间的网络
- Internet与Service之间的网络
1.容器和容器之间的网络
pod有多个容器,它们之间怎么通信?
pod中每个docker容器和pod在一个网络命名空间内,所以ip和端口等等网络配置,都和pod一样,主要通过一种机制就是,docker的一种网络模式,container,新创建的Docker容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等
2.pod与pod之间的网络
pod与pod之间的网络:首先pod自身拥有一个IP地址,不同pod之间直接使用IP地址进行通信即可
同一台node节点上pod和pod通信
疑问:那么不同pod之间,也就是不同网络命名空间之间如何进行通信(现在还是,同一台node节点上)
解决:
简单说veth对就是一个成对的端口,所有从这对端口一端进入的数据包,都将从另一端出来。
为了让多个Pod的网络命名空间链接起来,我们可以让veth对的一端链接到root网络命名空间(宿主机的),另一端链接到Pod的网络命名空间。
嗯,那么继续。
还需要用到一个Linux以太网桥,它是一个虚拟的二层网络设备,目的就是把多个以太网段连接起来,它维护一个转发表,通过查看每个设备mac地址决定转发,还是丢弃数据
- pod1-->pod2(同一台node上),pod1通过自身eth0网卡发送数据,eth0连接着veth0,网桥把veth0和veth1组成了一个以太网,然后数据到达veth0之后,网桥通过转发表,发送给veth1,veth1直接把数据传给pod2的eth0。
不同node节点上pod和pod通信
CIDR的介绍:
CIDR(Classless Inter-Domain Routing,无类域间路由选择)它消除了传统的A类、B类和C类地址以及划分子网的概念,因而可以更加有效地分配IPv4的地址空间。它可以将好几个IP网络结合在一起,使用一种无类别的域际路由选择算法,使它们合并成一条路由从而较少路由表中的路由条目减轻Internet路由器的负担。
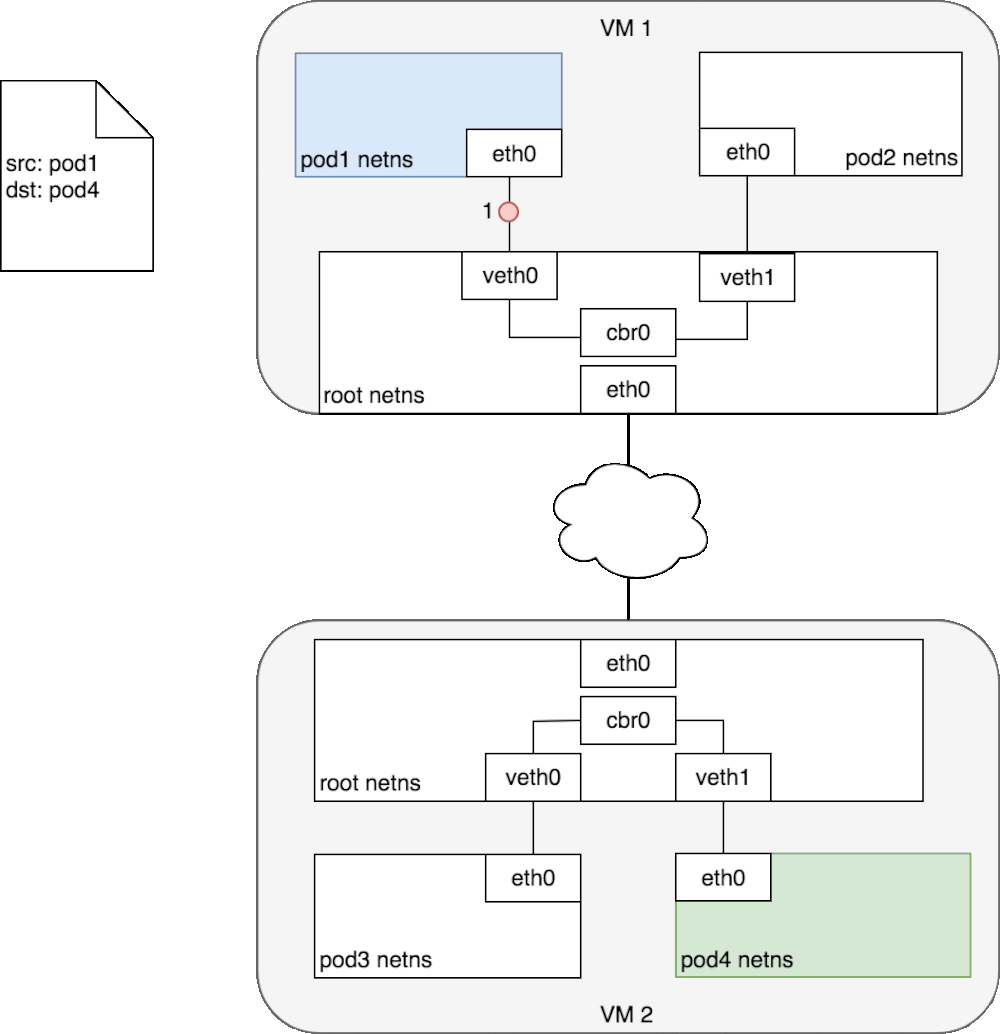
看图,接着往下捋。
k8s集群中,每个node节点都会被分配一个CIDR块,(把网络前缀都相同的连续地址组成的地址组称为CIDR地址块)用来给node上的pod分配IP地址,另外还需要把pod的ip和所在nodeip进行关联
- 比如node1上pod1和node2上的pod4进行通信
- 首先pod1上网卡eth0将数据发送给已经管理到root命名空间的veth0上,被虚拟网桥收到,查看自己转发表之后,并没有pod4的mac地址。
- 就会把包转发到默认路由,(root命名空间的eth0上,也就是已经到了node节点的往卡上)通过eth0,发送到网络中。
- 寻址转发后包来到了node2,首先被root命名空间的eth0设备接受,查看目标地址是发往pod4的,交给虚拟网桥路由到veth1,最终传给pod4的eth0上。
3.pod与service之间的网络
pod的ip地址是不持久的,当集群中pod的规模缩减或者pod故障或者node故障重启后,新的pod的ip就可能与之前的不一样的。所以k8s中衍生出来Service来解决这个问题。
Service管理了多个Pods,每个Service有一个虚拟的ip,要访问service管理的Pod上的服务只需要访问你这个虚拟ip就可以了,这个虚拟ip是固定的,当service下的pod规模改变、故障重启、node重启时候,对使用service的用户来说是无感知的,因为他们使用的service的ip没有变。
当数据包到达Service虚拟ip后,数据包会被通过k8s给该servcie自动创建的负载均衡器路由到背后的pod容器。
- 在k8s里,iptables规则是由kube-proxy配置,kube-proxy监视APIserver的更改,因为集群中所有service(iptables)更改都会发送到APIserver上,所以每台kubelet-proxy监视APIserver,当对service或pod虚拟IP进行修改时,kube-proxy就会在本地更新,以便正确发送给后端pod
- pod到service包的流转:

数据包从pod1所在eth0离开,通过veth对的另一端veth0传给网桥cbr0,网桥找不到service的ip对应的mac,交给了默认路由,到达了root命名空间的eth0
root命名空间的eth0接受数据包之前会经过iptables进行过滤,iptables接受数据包后使用kube-proxy在node上配置的规则响应service,然后数据包的目的ip重写为service后端指定的pod的ip了
- service到pod包的流转
收到包的pod会回应数据包到源pod,源ip是发送方ip,目标IP是接收方,数据包进行回复时经过iptables,iptables使用内核机制conntrack记住它之前做的选择,又将数据包源ip重新为service的ip,目标ip不变,然后原路返回至pod1的eth0
4.Internet与service之间的网络
将k8s集群服务暴露给互联网上用户使用,有两个问题;(1)从k8s的service访问Internet,以及(2)从Internet访问k8s的service.
根据参考文章,通过Internet网关,node可以将流量路由到Internet,但是pod具有自己的IP地址,Internet王冠上的NAT转换并不适用。参考方案:就是node主机通过iptables的nat来解决
- node到internet包的流转
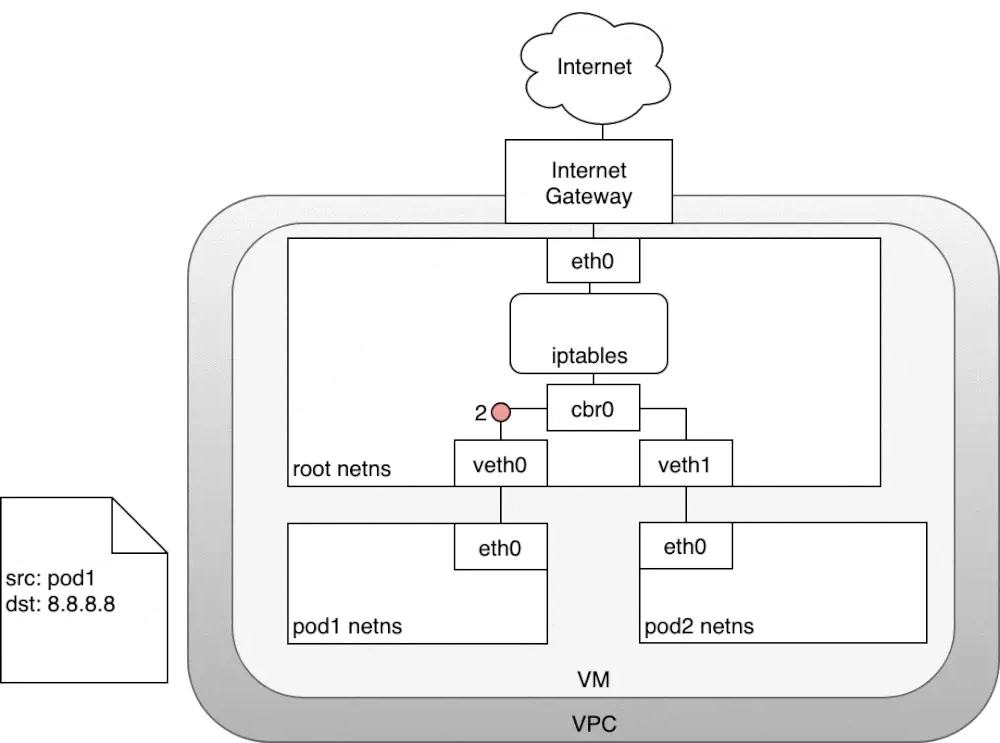
数据包源自pod1网络命名空间,通过veth对连接到root网络命名空间,紧接着,转发表里没有IP对应的mac,会发送到默认路由,到达root网络命名空间的eth0
那么在到达root网络明明空间之前,iptables会修改数据包,现在数据包源ip是pod1的,继续传输会被Internet网关拒绝掉,因为网关NAT仅转发node的ip,解决方案:使iptables执行源NAT更改数据包源ip,让数据包看起来是来自于node而不是pod
iptables修改完源ip之后,数据包离开node,根据转发规则发给Internet网关,Internet网关执行另一个NAT,内网ip转为公网ip,在Internet上传输。
数据包回应时,也是按照:Internet网关需要将公网IP转换为私有ip,到达目标node节点,再通过iptables修改目标ip并且最终传送到pod的eth0虚拟网桥。
Internet到k8s的流量
让Internet流量进入k8s集群,这特定于配置的网络,可以在网络堆栈的不同层来实现:
(1) NodePort
(2)Service LoadBalancer
(3)Ingress控制器。
这里只介绍第三种,如果想看详细的,文章开始有一个链接
- 第七层流量入口:Ingress Controller
通过一个公开的ip地址来公开多个服务,第7层网络流量入口是在网络堆栈的HTTP / HTTPS协议范围内运行,并建立在service之上。
工作:客户端现针对www.1234.com执行dns解析,DNS服务器返回ingress控制器的ip,客户端拿到ip后,向ingress控制器发送http的get请求,将域名加在host头部发送。控制器接收到请求后,从host头部就知道了该访问哪一个服务,通过与该service关联的endpoint对象查询podIP地址,将请求进行转发
第7层负载均衡器的一个好处是它们具有HTTP感知能力,因此它们了解URL和路径。 这允许您按URL路径细分服务流量。 它们通常还在HTTP请求的X-Forwarded-For标头中提供原始客户端的IP地址。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2020-06-04 logstash的mutate插件
2020-06-04 logstash中date的时间处理方式总结
2020-06-04 logstash更新gem源
2020-06-04 logstash的Multiline插件