

ES中Refresh和Flush的区别
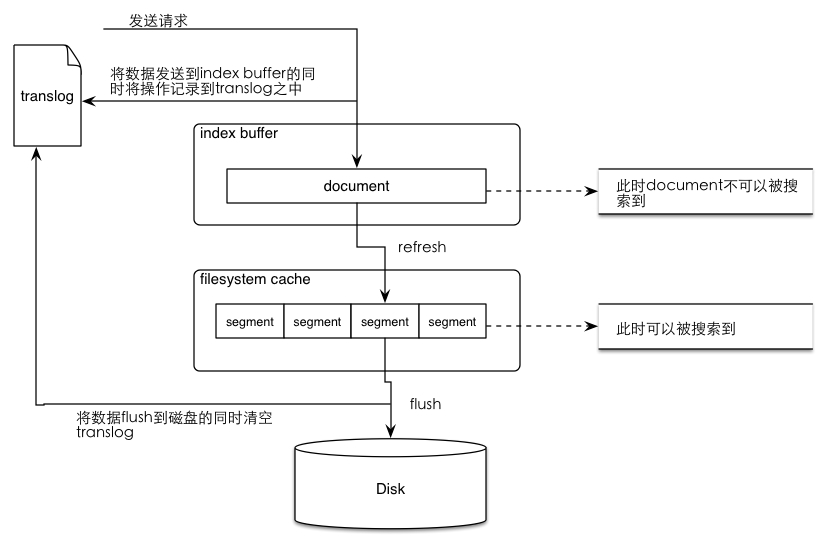
整体流程:
- 数据写入buffer缓冲和translog日志文件中。
当你写一条数据document的时候,一方面写入到mem buffer缓冲中,一方面同时写入到translog日志文件中。 - buffer满了或者每隔1秒(可配),refresh将mem buffer中的数据生成index segment文件并写入os cache,此时index segment可被打开以供search查询读取,这样文档就可以被搜索到了(注意,此时文档还没有写到磁盘上);然后清空mem buffer供后续使用。可见,refresh实现的是文档从内存移到文件系统缓存的过程。
- 重复上两个步骤,新的segment不断添加到os cache,mem buffer不断被清空,而translog的数据不断增加,随着时间的推移,translog文件会越来越大。
- 当translog长度达到一定程度的时候,会触发flush操作,否则默认每隔30分钟也会定时flush,其主要过程:
4.1. 执行refresh操作将mem buffer中的数据写入到新的segment并写入os cache,然后打开本segment以供search使用,最后再次清空mem buffer。
4.2. 一个commit point被写入磁盘,这个commit point中标明所有的index segment。
4.3. filesystem cache(os cache)中缓存的所有的index segment文件被fsync强制刷到磁盘os disk,当index segment被fsync强制刷到磁盘上以后,就会被打开,供查询使用。
4.4. translog被清空和删除,创建一个新的translog。
refresh
最原始的ES版本里,必须等待fsync将segment刷入磁盘,才能将segment打开供search使用,这样的话,从一个document写入到它可以被搜索,可能会超过一分钟,主要瓶颈是在fsync实际发生磁盘IO写数据进磁盘,是很耗时的,这就不是近实时的搜索了。为此,引入refresh操作的目的是提高ES的实时性,使添加文档尽可能快的被搜索到,同时又避免频繁fsync带来性能开销,依靠的原理就是文件系统缓存OS cache里缓存的文件可以被打开(open/reopen)和读取,而这个os cache实际是一块内存区域,而非磁盘,所以操作是很快的。
写入流程改进:
1)数据写入到内存buffer队列中
2)每隔一定时间,buffer中的数据被写入segment文件,然后先写入os cache
3)只要segment数据写入os cache,那就直接打开segment供search使用,而不必调用fsync将segment刷新到磁盘
将缓存数据生成segment后刷入os cache,并被打开供搜索的过程就叫做refresh,默认每隔1秒。也就是说,每隔1秒就会将buffer中的数据写入一个新的index segment file,先写入os cache中。所以,es是近实时的,输入写入到os cache中可以被搜索,默认是1秒,所以从数据插入到被搜索到,最长是1秒(可配)。
flush操作与translog
但是,需要注意, index segment刷入到os cache后就可以打开供查询,这个操作是有潜在风险的,因为os cache中的数据有可能在意外的故障中丢失,而此时数据必备并未刷入到os disk,此时数据丢失将是不可逆的,这个时候就需要一种机制,可以将对es的操作记录下来,来确保当出现故障的时候,已经落地到磁盘的数据不会丢失,并在重启的时候可以从操作记录中将数据恢复过来。elasticsearch提供了translog来记录这些操作,结合os cached segments数据定时落盘来实现数据可靠性保证(flush)。
当向elasticsearch发送创建document文档添加请求的时候,document数据会先进入到buffer,与此同时会将操作记录在translog之中,当发生refresh时(数据从index buffer中进入filesystem cache的过程)translog中的操作记录并不会被清除,而当数据从os cache中被写入磁盘之后才会将translog中清空。这个将os cache的索引文件(segment file)持久化到磁盘的过程就是flush,flush之后,这段translog的使命就完成了,因为segment已经写入磁盘,就算故障也可以从磁盘的segment文件中恢复。flush的时机可能是1.定时flush;2.translog大小达到阈值;3.一些重要操作;4.指令触发。
translog记录的是已经在内存生成(segments)并存储到os cache但是还没写到磁盘的那些索引操作(注意,有一种解释说,添加到buffer中但是没有被存入segment中的数据没有被记录到translog中,这依赖于写translog的时机,不同版本可能有变化,不影响理解),此时这些新写入的数据可以被搜索到,但是当节点挂掉后这些未来得及落入磁盘的数据就会丢失,可以通过trangslog恢复。
当然translog本身也是磁盘文件,频繁的写入磁盘会带来巨大的IO开销,因此对translog的追加写入操作的同样操作的是os cache,因此也需要定时落盘(fsync)。translog落盘的时间间隔直接决定了ES的可靠性,因为宕机可能导致这个时间间隔内所有的ES操作既没有生成segment磁盘文件,又没有记录到Translog磁盘文件中,导致这期间的所有操作都丢失且无法恢复。
translog的fsync是ES在后台自动执行的,默认是每5秒钟主动进行一次translog fsync,或者当translog文件大小大于512MB主动进行一次fsync,对应的配置是index.translog.flush_threshold_period 和 index.translog.flush_threshold_size。还需指出的是, 从ES2.0开始,每次index、bulk、delete、update完成的时候也会触发translog flush,当flush到磁盘成功后才给请求端返回 200 OK。这个改变提高了数据安全性,但是会对写入的性能造成不小的影响,因此在可靠性要求不十分严格且写入效率优先的情况下,可以在 index template 里设置如下参数:"index.translog.durability":"async",这相当于关闭了index、bulk等操作的同步flush translog操作,仅使用默认的定时刷新、文件大小阈值刷新的机制,同时可以调高 "index.translog.sync_interval":30s (默认是5s)和index.translog.flush_threshold_size配置选项。
总结一下translog的功能:
- 保证在filesystem cache中的数据不会因为elasticsearch重启或是发生意外故障的时候丢失。
- 当系统重启时会从translog中恢复之前记录的操作。
- 当对elasticsearch进行CRUD操作的时候,会先到translog之中进行查找,因为tranlog之中保存的是最新的数据。
- translog的清除时间时进行flush操作之后(将数据从filesystem cache刷入disk之中)。
总结一下flush操作的时间点:
- es的各个shard会每个30分钟进行一次flush操作。
- 当translog的数据达到某个上限的时候会进行一次flush操作。
有关于translog和flush的一些配置项:
- index.translog.flush_threshold_ops:当发生多少次操作时进行一次flush。默认是 unlimited。
- index.translog.flush_threshold_size:当translog的大小达到此值时会进行一次flush操作。默认是512mb。
- index.translog.flush_threshold_period:在指定的时间间隔内如果没有进行flush操作,会进行一次强制flush操作。默认是30m。
- index.translog.interval:多少时间间隔内会检查一次translog,来进行一次flush操作。es会随机的在这个值到这个值的2倍大小之间进行一次操作,默认是5s。
转载自:https://www.jianshu.com/p/15837be98ffd


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!