

ES索引生命周期管理二
如果你要处理时间序列数据,则不想将所有内容连续转储到单个索引中。 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵。 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低的硬件上,并减少分片和副本的数量。
要在索引的生命周期内自动移动索引,可以创建策略来定义随着索引的老化对索引执行的操作。 索引生命周期策略在与 Beats 数据发件人一起使用时特别有用,Beats 数据发件人不断将运营数据(例如指标和日志)发送到 Elasticsearch。 当现有索引达到指定的大小或期限时,你可以自动滚动到新索引。 这样可以确保所有索引具有相似的大小,而不是每日索引,其大小可以根 beats 数和发送的事件数而有所不同。
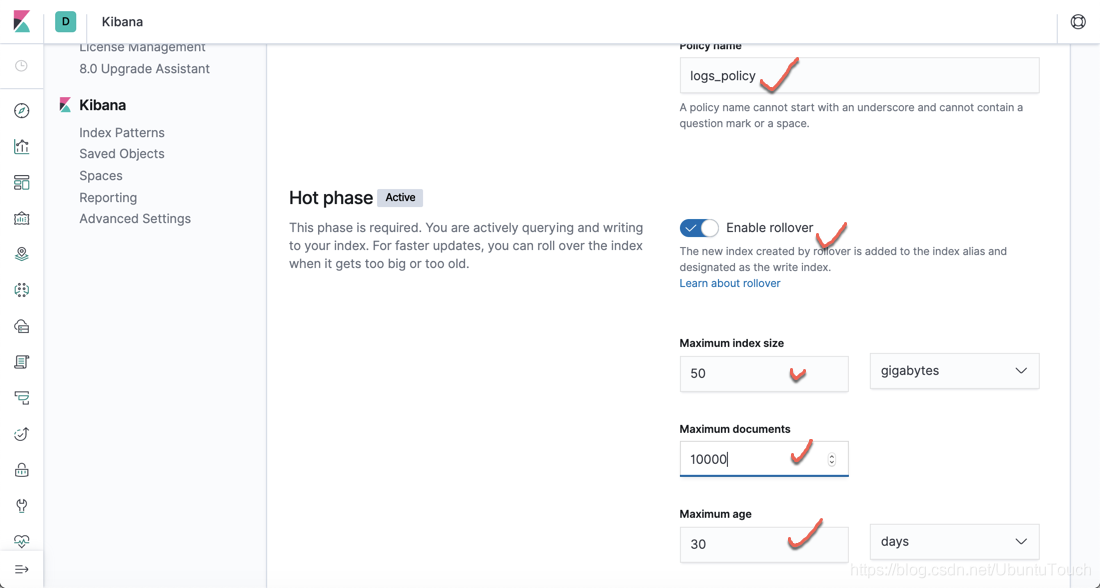
让我们通过动手操作场景跳入索引生命周期管理(Index cycle management: ILM)。 本文章将利用您可能不熟悉的ILM独有的许多新概念。 我们先用一个示例来展示。本示例的目标是建立一组索引,这些索引将封装来自时间序列数据源的数据。 我们可以想象有一个像Filebeat这样的系统,可以将文档连续索引到我们的书写索引中。 我们希望在索引达到50 GB,或文档的数量超过10000,或已在30天前创建索引后对其进行 rollover,然后在90天后删除该索引。
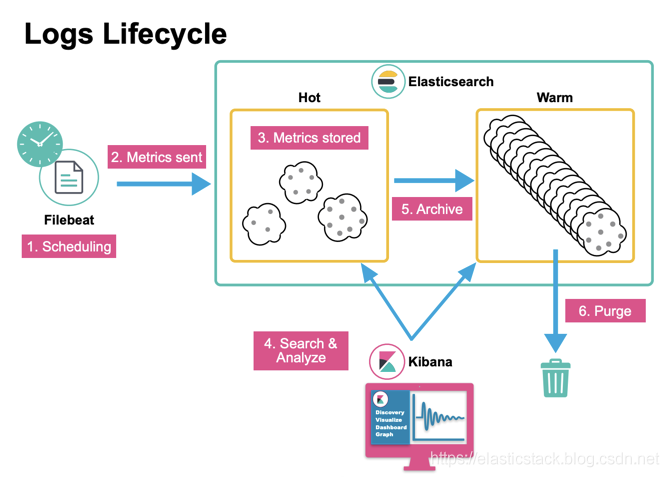
上图显示一个 Log 文档在 Elasticsearch 中生命周期。
针对一个超大规模的集群:

运行两个 node 的 Elasticsearch 集群
我们可以参考文章 “Elasticsearch:运用shard filtering来控制索引分配给哪个节点” 运行起来两个 node 的 cluster。其实非常简单,当我们安装好 Elasticsearch 后,打开一个 terminal,并运行如下的命令:
./bin/elasticsearch -E node.name=node1 -E node.attr.data=hot -Enode.max_local_storage_nodes=2
它将运行起来一个叫做 node1 的节点。同时在另外 terminal 中运行如下的命令:
./bin/elasticsearch -E node.name=node2 -E node.attr.data=warm -Enode.max_local_storage_nodes=2
它运行另外一个叫做 node2 的节点。我们可以通过如下的命令来进行查看:
GET _cat/nodes?v
显示两个节点:

我们可以用如下的命令来检查这两个 node 的属性:
GET _cat/nodeattrs?v&s=name

显然其中的一个 node 是 hot,另外一个是 warm。
准备数据

我们分别点击上面的1和2处:
点击上面的 “Add data”。这样我们就可以把我们的 kibana_sample_data_logs 索引加载到 Elasticsearch 中。我们可以通过如下的命令进行查看:
GET _cat/indices/kibana_sample_data_logs
命令显示结果为:
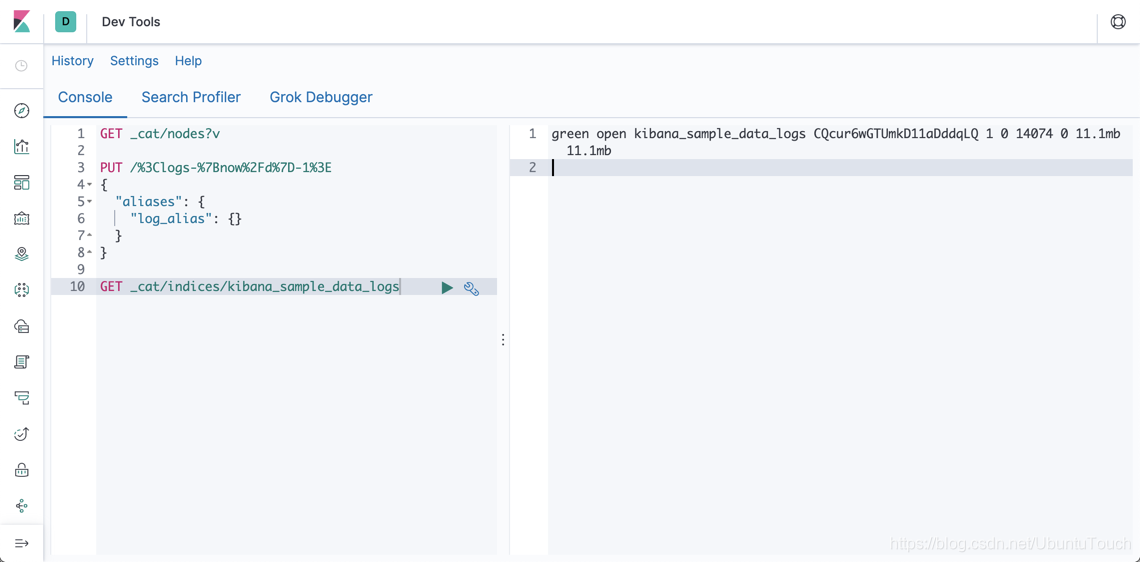
它显示 kibana_sample_data_logs 具有11.1M的数据,并且它有 14074 个文档。
建立 ILM policy
我们可以通过如下的方法来建立一个 ILM 的 policy.

PUT _ilm/policy/logs_policy { "policy": { "phases": { "hot": { "min_age": "0ms", "actions": { "rollover": { "max_size": "50gb", "max_age": "30d", "max_docs": 10000 }, "set_priority": { "priority": 100 } } }, "delete": { "min_age": "90d", "actions": { "delete": {} } } } } }
这里定义的一个 policy 意思是:
- 如果一个 index 的大小超过 50GB,那么自动 rollover
- 如果一个 index 日期已在30天前创建索引后,那么自动 rollover
- 如果一个 index 的文档数超过10000,那么也会自动 rollover
- 当一个 index 创建的时间超过90天,那么也自动删除
其实这个我们也可以通过 Kibana 帮我们来实现。请按照如下的步骤:
紧接着点击“Index Lifecycle Policies”:

再点击“Create Policy”:
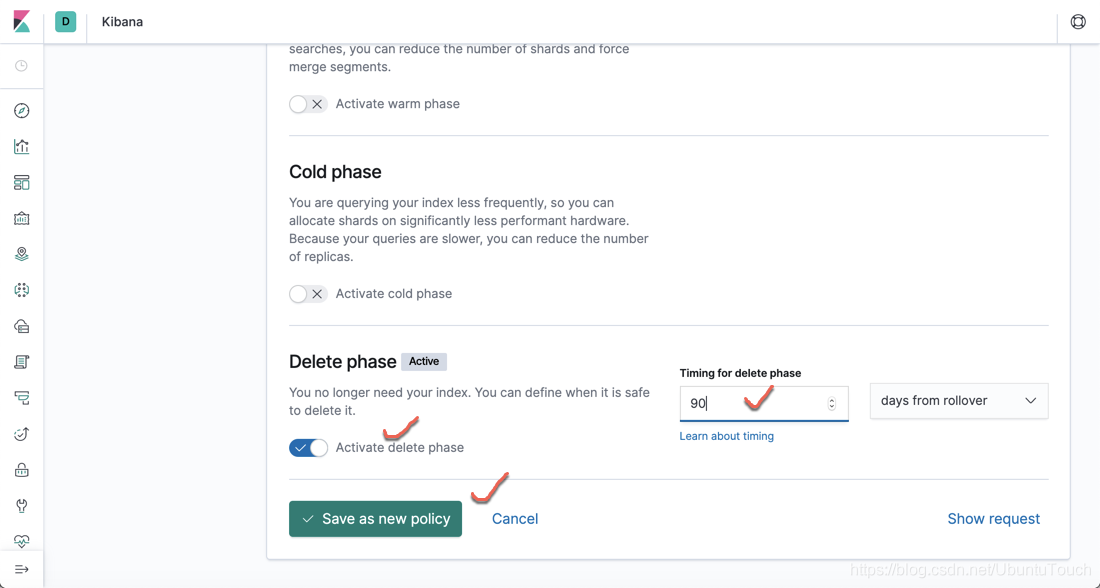
最后点“Save as new Policy”及可以在我们的Kibana中同过如下的命令可以查看到:
GET _ilm/policy/logs_policy显示结果:

设置 Index template
我们可以通过如下的方法来建立 template:
PUT _template/datastream_template { "index_patterns": ["logs*"], "settings": { "number_of_shards": 1, "number_of_replicas": 1, "index.lifecycle.name": "logs_policy", "index.routing.allocation.require.data": "hot", "index.lifecycle.rollover_alias": "logs" } }
这里的意思是所有以 logs 开头的 index 都需要遵循这个规律。这里定义了 rollover 的 alias 为 “logs”。这在我们下面来定义。同时也需要注意的是 "index.routing.allocation.require.data": "hot"。这个定义了我们需要 indexing 的 node 的属性是 hot。请看一下我们上面的 policy 里定义的有一个叫做 phases 里的,它定义的是 "hot"。在这里我们把所有的 logs* 索引都置于 hot 属性的 node 里。在实际的使用中,hot 属性的 index 一般用作 indexing。我们其实还可以定义一些其它 phase,比如 warm,这样可以把我们的用作搜索的 index 置于 warm 的节点中。这里就不一一描述了。
定义 Index alias
PUT logs-000001 { "aliases": { "logs": { "is_write_index": true } } }
在这里定义了一个叫做 logs 的 alias,它指向 logs-00001 索引。注意这里的 is_write_index 为 true。如果有 rollover 发生时,这个alias会自动指向最新 rollover 的 index。
生产数据
在这里,我们使用之前我们已经导入的测试数据 kibana_sample_data_logs,我们可以通过如下的方法来写入数据:
POST _reindex?requests_per_second=500 { "source": { "index": "kibana_sample_data_logs" }, "dest": { "index": "logs" } }
上面的意思是每秒按照500个文档从 kibana_sample_data_logs 索引 reindex 文档到 logs 别名所指向的 index。我们运行后,通过如下的命令来查看最后的结果:
GET logs*/_count显示如下:
我们可以看到 logs-000002 已经生产,并且所有的索引都在 node1 上面。我们可以通过如下的命令:
GET _cat/indices/logs?v
我们可以看到 logs-000001 索引中有10000个文档,而 logs-000002 中含有4074个文档。
由于我们已经设定了policy,那么所有的这些logs*索引的生命周期只有90天。90天过后(从索引被创建时算起),索引会自动被删除掉。
转载自:https://elasticstack.blog.csdn.net/article/details/102728987


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!