

Elastic:在 Grok 中运用 custom pattern 来定义 pattern
我们先来看一下如下的一个日志:
157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing
在上面的日志中,我们可以看到一个日期信息:2019 09 29 00:39:02.912。它是被空格字符串所分开,如果没有正确的 Grok pattern 来帮我们提取的话,我们将会很难提取到一个完整的日期。我们的日志信息符合如下的一个数据结构:
ip timestamp server Process process_id action
首先,我们打开 Kibana:
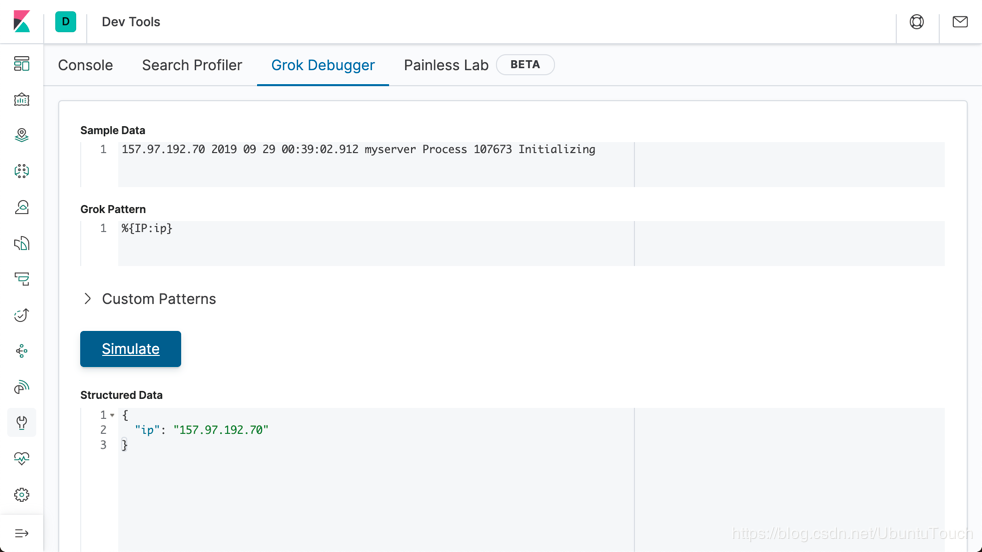
我们可以先提取 IP:
之后的,就是年,月,日,及时间。我们可以通过如下的方式来进行提取:
- 运用 YEAY 来提取年份
- 运用 MONTHNUM 来提取月份
- 运用 MONTHDAY 来提取日期
- 运用 TIME 来提取时间
- 运用 WORD 来提取一个单词
- 运用 NUMBER 来提取一个数值
- 对于 Process 来说,我们就不提取了,忽略它
这样,我们可以使用如下的 Grok pattern:
%{IP:ip} %{YEAR:year} %{MONTHNUM:month} %{MONTHDAY:day} %{TIME:time} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}
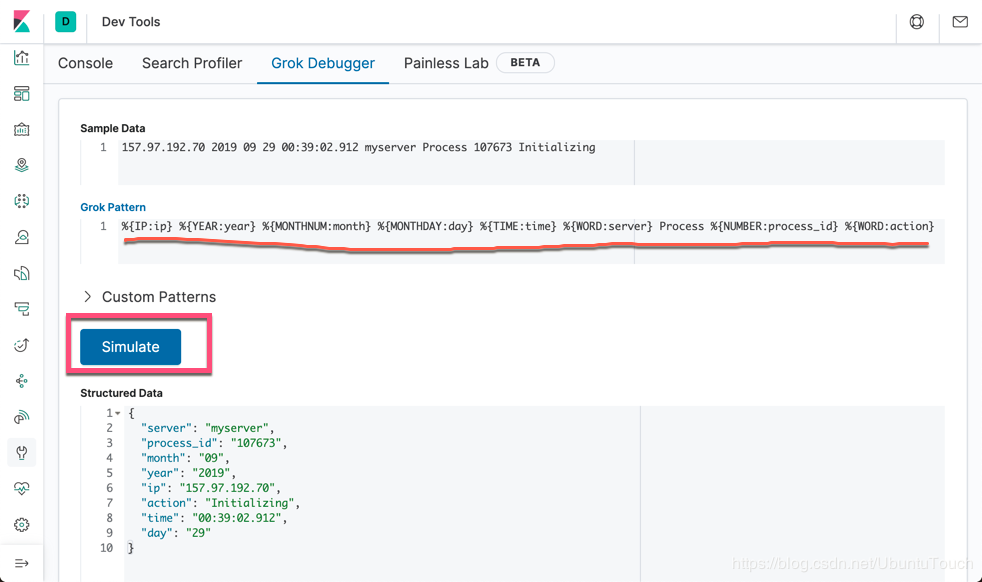
显然,它正确地解析了我们的日志,但是美中不足的是我们最终需要的是一个真正的日期,而不是用 year, month, day, time 来表示的一个时间。我们可以点击上面的 custerm pattern,并输入一下的句子:
EVENTDATE %{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME}
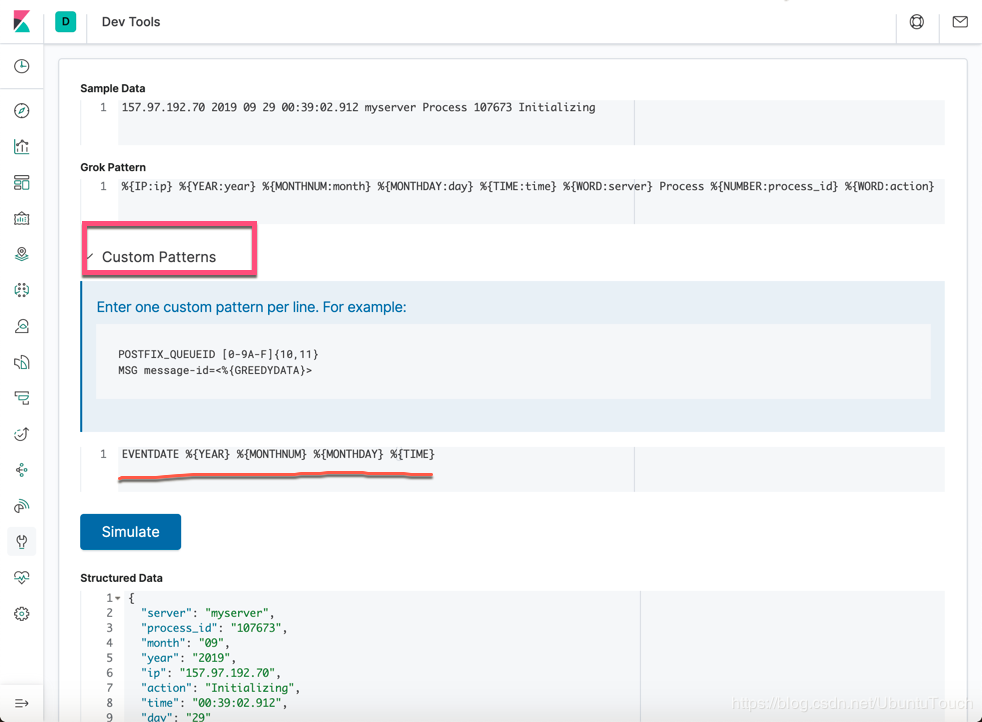
在上面,我们定义了 EVENDATE 为 YEAR, MONTHNUM, MONTHDAY 及 TIME 的组合。那么我们该如和应用上面的 custom patttern呢?
我们必须修改上面的 Grok pattern 为:
%{IP:ip} %{EVENTDATE:@timestamp} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}
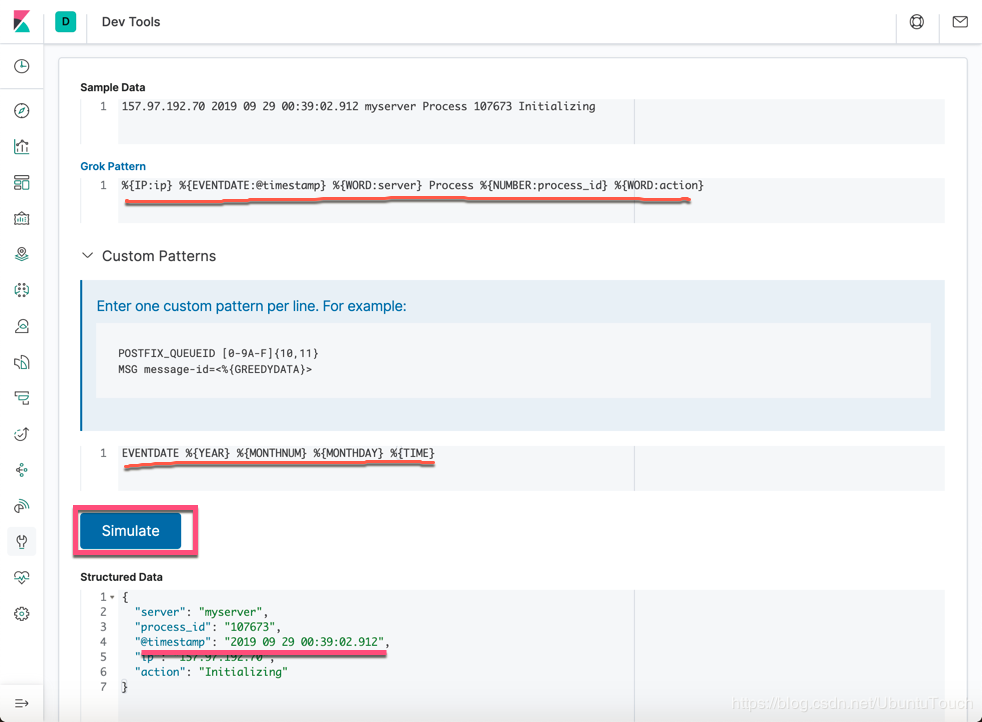
从上面,我们可以看出来,我们的 EVENTDATE 起作用了。它正确地解析了我们的时间。
那么在我们实际的使用中,我们该如何地应用呢?
我们可以创建如下的一个命令:

POST /_ingest/pipeline/_simulate { "pipeline": { "processors": [ { "grok": { "field": "message", "patterns": [ "%{IP:ip} %{EVENTDATE:@timestamp} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}" ], "pattern_definitions": { "EVENTDATE": "%{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME}" } } } ] }, "docs": [ { "_source": { "message": "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing" } } ] }
运行上面的命令:
{ "docs" : [ { "doc" : { "_index" : "_index", "_type" : "_doc", "_id" : "_id", "_source" : { "server" : "myserver", "process_id" : "107673", "@timestamp" : "2019 09 29 00:39:02.912", "ip" : "157.97.192.70", "action" : "Initializing", "message" : "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing" }, "_ingest" : { "timestamp" : "2020-06-15T08:33:01.28191Z" } } } ] }
上面显示我们的日志被正确地解析并结构化。
另外一种方法是通过 set processor 来把上面的日期相关的字段来组成我们需要的 @timestamp 字段。
POST /_ingest/pipeline/_simulate { "pipeline": { "processors": [ { "grok": { "field": "message", "patterns": [ "%{IP:ip} %{YEAR} %{MONTHNUM} %{MONTHDAY} %{TIME} %{WORD:server} Process %{NUMBER:process_id} %{WORD:action}" ] } }, { "set": { "field": "@timestamp", "value": "{{year}} {{month}} {{day}} {{time}}" } } ] }, "docs": [ { "_source": { "message": "157.97.192.70 2019 09 29 00:39:02.912 myserver Process 107673 Initializing" } } ] }
在上面,我们通过:
{ "set": { "field": "@timestamp", "value": "{{year}} {{month}} {{day}} {{time}}" } }
来把 @timestamp 进行定义,它组合了 year, month, day 及 time 的值。
转载自:https://blog.csdn.net/UbuntuTouch/article/details/106764157


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!