

Elasticsearch:如何使用 Elasticsearch ingest 节点来丰富日志和指标
当导入数据到Elasticsearch中时,用其他信息丰富文档通常是有益的,这些信息以后可用于搜索或查看数据。丰富化是将权威来源的数据合并到文档中的过程,这些数据被摄入到Elasticsearch中。
例如,可以使用GeoIP处理器来进行扩充,该处理器可以处理包含IP地址的文档,并添加有关与每个IP地址关联的地理位置的信息。在导入数据时用地理位置丰富文档非常有用,因为它允许快速的查询时操作,例如按位置查询或在地图上高效地显示信息。
虽然GeoIP处理器是了解丰富功能的一个很好的例子,但在许多其他情况下,可能需要使用自定义数据来丰富文档。不难想像这样的场景:有些设备将数据记录到Elasticsearch中,并且从这些设备发送的数据需要使用主数据进行充实。该主数据可以包括诸如设备位置,团队拥有给定设备,设备类型等信息。
从历史上看,数据丰富功能仅在Logstash中可用,但是由于Elasticsearch 7.5.0中引入了enrich处理器,因此可以直接 Elasticsearch 中进行丰富,而无需配置单独的服务/系统。如果你想知道在Logstash中是如何实现,那么请参阅我之前的文章“Logstash:运用jdbc_streaming来丰富我们的数据”。
由于通常用于富集的主数据通常是在CSV文件中创建的,因此在此博客中,我们将逐步说明如何使用CSV文件中的数据将在摄取节点上运行的enrich处理器用于丰富数据。
样本 CSV 数据
可以使用Kibana导入以下CSV格式的示例主数据,然后在将文档吸收到Elasticsearch中时用于丰富文档。 对于本博客中给出的示例,我们将主数据存储在一个名为test.csv的文件中。 此数据代表组织清单中的设备。
test.csv

请注意,CSV数据不应包含任何其他空格,因为当前版本的Data Visualizer需要精确格式化数据。 在此github问题中对此进行了记录。
将CSV数据导入Elasticsearch
我们可以直接使用Kibana来把数据导入。打开Kibana:
点击上面的 Import a CSV, NDJSON, or log file 链接:
点击 Select or drag and drop a file, 然后选择刚才我们创建的 test.csv 文件:
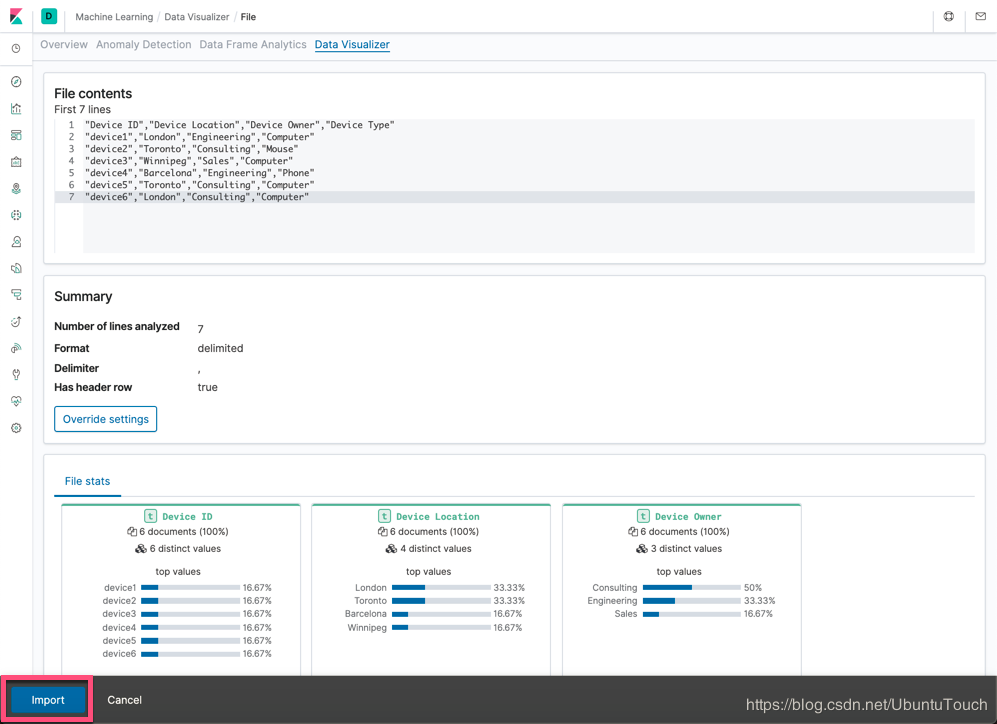
点击 Import 按钮:
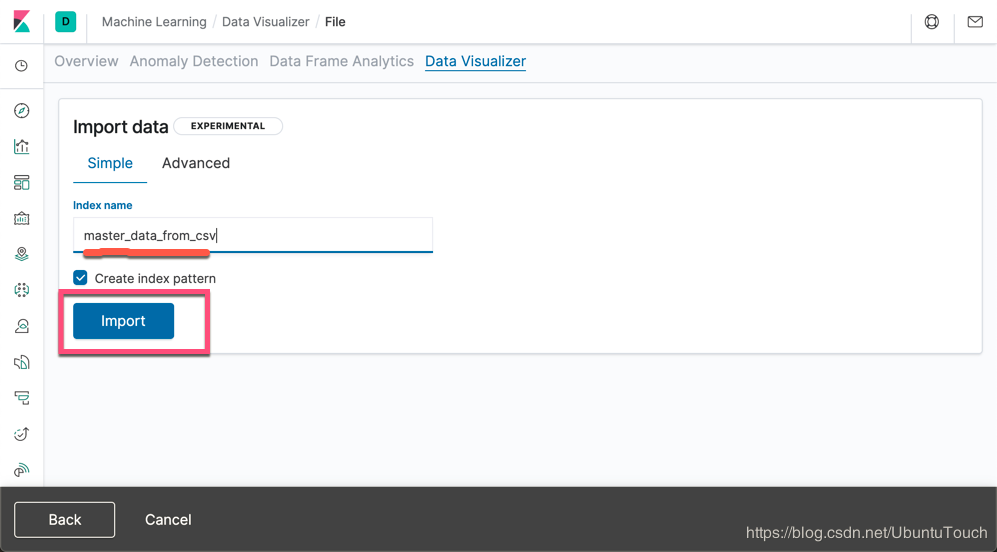
我们把导入的这个index的名字叫做master_data_from_csv。点击 Import 按钮:
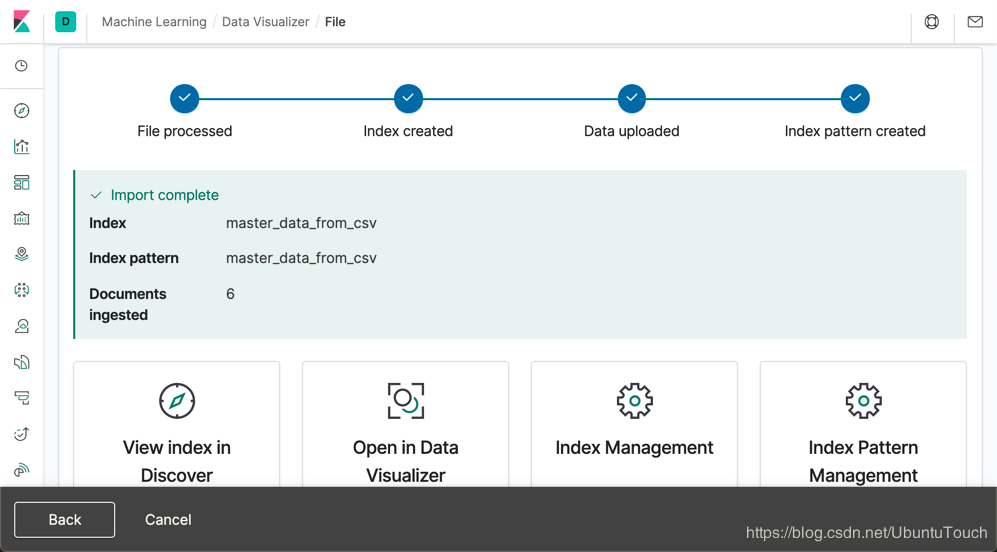
这样就完成了我们的 master_data_from_csv 的索引创建。我们可以在上面屏幕的下方的四个选项中任意选择一个来查看导入的数据。
利用我们的主数据丰富文档
在本节中,我们演示如何使用Enrich Processor将主数据合并到输入数据流中的文档中。
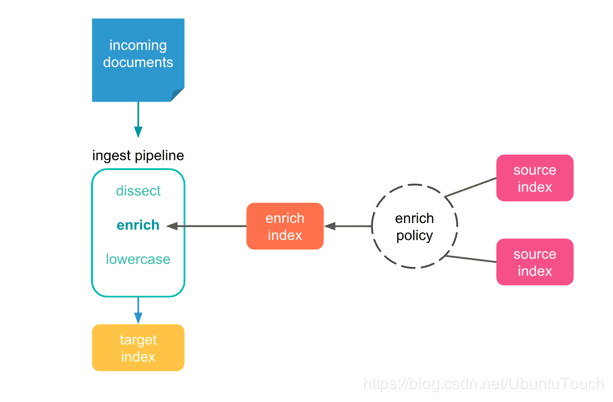
第一步是创建一个丰富的策略,该策略定义我们将使用哪个字段将主数据与输入数据流中的文档进行匹配。 下面提供了适用于我们的数据的示例策略:

PUT /_enrich/policy/enrich-devices-policy { "match": { "indices": "master_data_from_csv", "match_field": "Device ID", "enrich_fields": [ "Device Location", "Device Owner", "Device Type" ] } }
运行上面的策略。然后,我们使用execute enrich policy API为该策略创enrich索引:
接下来,我们创建一个使用我们的丰富策略的ingest pipeline。
PUT /_ingest/pipeline/device_lookup { "description": "Enrich device information", "processors": [ { "enrich": { "policy_name": "enrich-devices-policy", "field": "device_id", "target_field": "my_enriched_data", "max_matches": "1" } } ] }
我们插入一个文档,并让它使用上面定义的ingest pipeline,如下所示:
PUT /device_index/_doc/1?pipeline=device_lookup { "device_id": "device1", "other_field": "some value" }
我们可以使用GET API查看导入的文档,如下所示:
GET device_index/_doc/1
{ "_index" : "device_index", "_type" : "_doc", "_id" : "1", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "my_enriched_data" : { "Device Location" : "London", "Device Owner" : "Engineering", "Device ID" : "device1", "Device Type" : "Computer" }, "device_id" : "device1", "other_field" : "some value" } }
在上面,我们可以看出来在返回的文档信息中,有多一个叫做my_enriched_data的字段。它包含了Device Location, Device Owner, Device ID 及 Device Type。这些信息都来自于我们之前导入的test.csv文档信息。enrich processor 通过关联 device_id 为 device1 而从 master_data_from_csv 索引中获得这些信息。也就是说我们的数据变得更多了,这也就是我们之前说的丰富了。
结论
通常需要在导入时丰富文档,以确保Elasticsearch中的文档包含搜索或查看它们所需的信息。 在此博客中,我们演示了在ingest节点上运行的enrich处理器如何使用CSV数据进行扩充,这对于在将主数据吸收到Elasticsearch中时将主数据合并到文档中非常有用。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!