

Elasticsearch中使用pipeline API来对事件进行处理
在Elasticsearch 5.0之前,如果我们想在将文档索引到Elasticsearch之前预处理文档,那么唯一的方法是使用Logstash或以编程方式/手动预处理它们,然后将它们索引到Elasticsearch。 Elasticsearch缺乏预处理/转换文档的能力,它只是按原样索引文档。 但是,在Elasticsearch 5.x之后引入一个名为ingest node的功能,为Elasticsearch本身的文档预处理和丰富之前提供了一个轻量级的解决方案。
当我们的数据进入到Elastic集群中,并指定需要用到的Pipeline,那么Elasticsearch中的ingest node将会帮我们安装规定的processor顺序来执行对数据的操作和处理。这在某种程度上方便了我们许多对集群的部署。如果我们单独部署一个Logstash有时没有那么多的灵活性。我们可以通过编程的方式随时修改这个pipeline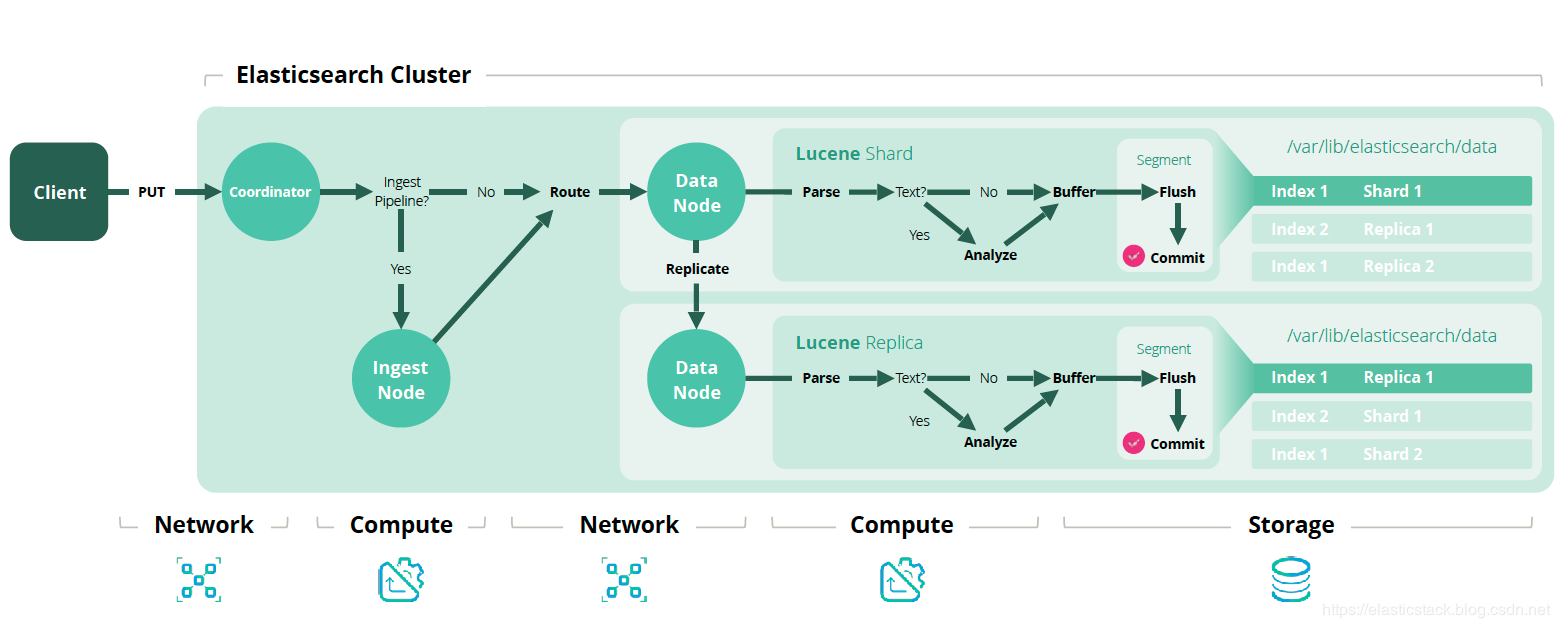
当我们的数据进入到Elastic集群中,并指定需要用到的Pipeline,那么Elasticsearch中的ingest node将会帮我们安装规定的processor顺序来执行对数据的操作和处理。这在某种程度上方便了我们许多对集群的部署。如果我们单独部署一个Logstash有时没有那么多的灵活性。我们可以通过编程的方式随时修改这个pipeline。
如果使用默认配置实现Elasticsearch节点,则默认情况下将启用master,data和ingest(即,它将充当主节点,数据节点和提取节点)。 要在节点上禁用ingest,请在elasticsearch.yml文件中配置以下设置:
node.ingest: false
ingest节点可用于在对文档执行实际索引之前预处理文档。 此预处理通过截取批量和索引请求的摄取节点执行,它将转换应用于数据,然后将文档传递回索引或批量API。 随着新的摄取功能的发布,Elasticsearch已经取出了Logstash的过滤器部分,以便我们可以在Elasticsearch中处理原始日志和丰富。
要在索引之前预处理文档,我们必须定义pipeline(其中包含称为处理器的步骤序列,用于转换传入文档)。 要使用pipeline,我们只需在索引或批量请求上指定pipeline参数,以告诉摄取节点使用哪个pipeliPOST my_index/my_type?pipeline=my_pipeline_id
POST my_index/my_type?pipeline=my_pipeline_id { "key": "value" }
定义一个pipeline
pipeline定义了一系列处理器。 每个处理器以某种方式转换文档。 每个处理器按照在pipeline中定义的顺序执行。 pipeline由两个主要字段组成:description和processor列表。
description参数是一个非必需字段,用于存储一些描述/管道的用法; 使用processor参数,可以列出处理器以转换文档。processor的典型结构如下所示:
{ "description" : "...", "processors" : [ ... ] }
inget节点有大约20个内置processor,包括gsub,grok,转换,删除,重命名等。 这些可以在构建管道时使用。 除了内置processor外,还可以使用摄取附件(如ingest attachment,ingetst geo-ip和ingest user-agent)等摄取插件,并可在构建pipeline时使用。 这些插件在默认情况下不可用,可以像任何其他Elasticsearch插件一样进行安装。
Pipeline以cluster状态存储,并且立即传播到所有ingest node。 当ingest node接收到新pipeline时,它们将以内存pipeline表示形式更新其节点,并且pipeline更改将立即生效。
Ingest APIs
ingest节点提供一组称为inget API的API,可用于定义,模拟,删除或查找有关pipeline的信息。 摄取API端点是_ingest。
Put pipeline API
此API用于定义新pipeline。 此API还用于添加新pipeline或更新现有pipeline。
我们来看一个例子吧。 如下面的代码所示,我们定义了一个名为firstpipeline的新pipeline,它将消息字段中的值转换为大写

PUT _ingest/pipeline/firstpipeline { "description": "uppsercase the incoming vlaue in the message filed", "processors": [ { "uppercase": { "field": "message" } } ] }
我们在Kibana中执行上面的命令,我们可以看到成功返回:
让我们来测试一下我们新建立的pipeline:
PUT myindex/_doc/1?pipeline=firstpipeline { "name": "pipeline", "message": "this is so cool!" }

我们看见我们的文档印被成功创建并存于一个叫做myindex的index里。下面我们来查看一下,我们刚才定义的pipeline是否已经起作用了。
GET myindex/_doc/1
我们可以看到我们的message已经都变成大写的了。
创建管道时,可以定义多个处理器,执行顺序取决于定义中定义的顺序。 让我们看一个这样的例子。 如下面的代码所示,我们创建了一个名为secondpipeline的新管道,它转换“message”字段中存在的大写值,并将“message”字段重命名为“data”。 它创建一个名为“label”的新字段,其值为testlabel:
PUT _ingest/pipeline/secondpipeline { "description": "uppercase the incoming value in the message field", "processors": [ { "uppercase": { "field": "message", "ignore_failure": true } }, { "rename": { "field": "message", "target_field": "data", "ignore_failure": true } }, { "set": { "field": "label", "value": "testlabel", "override": false } } ] }

我们的第二个被叫做secondpipeline的也已经创建好了。接下来,让我们来利用这个pipeline来对我们的文档进行处理。我们在Kibnana中输入:
PUT myindex/_doc/1?pipeline=secondpipeline { "name": "pipeline", "message": "this is so cool!" }
然后,我们使用如下的命令来查询我们刚才输入的文档:
GET myindex/_doc/1
显示的结果如下:
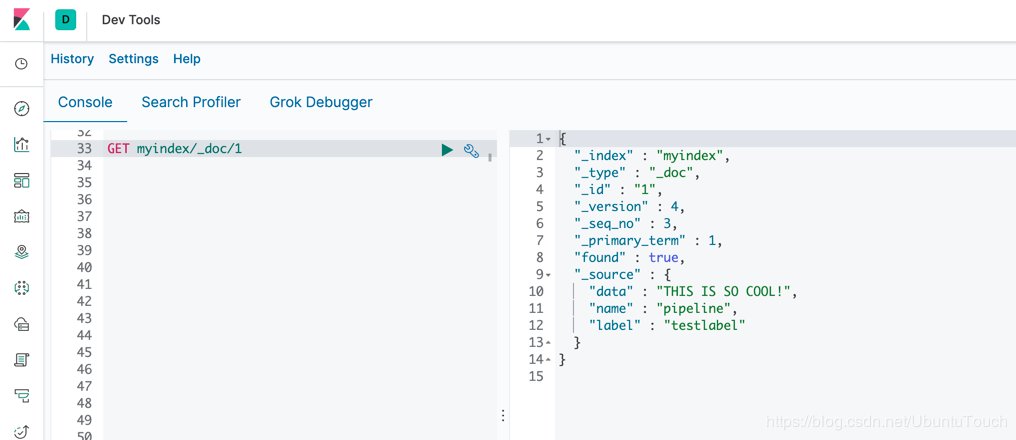
通过上面的例子,我们可以看到我们之前的message项不见了,取而代之的是data,同时它里面的字符都变成大写的了。另外,它也新增加了一个叫做label的项,并且它的值被设置为testlabel。
提示:如果缺少处理器中使用的字段,则处理器将抛出异常,并且不会对文档编制索引。 为了防止处理器抛出异常,我们可以利用
“ignore_failure”:true参数。
获取 pipeline API
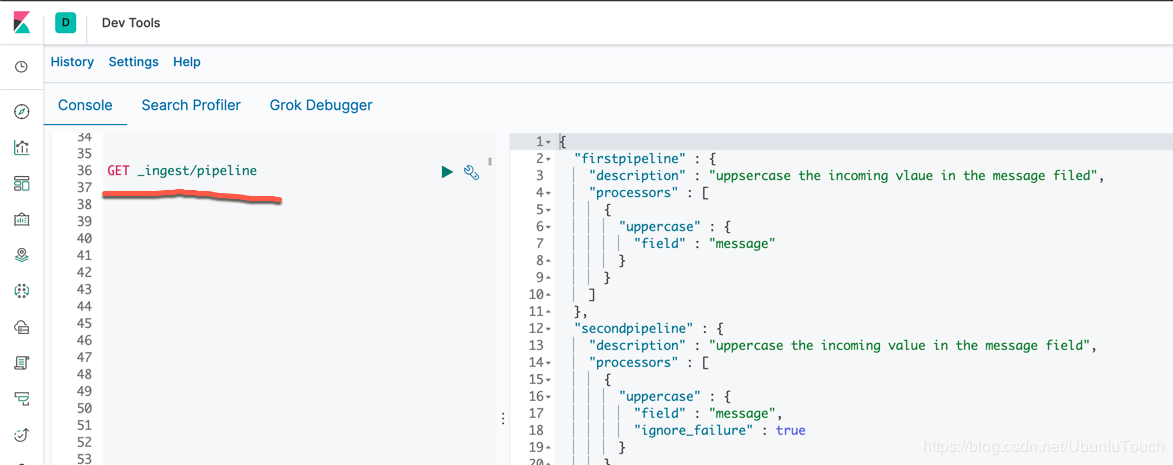
此API用于检索现有pipeline的定义。 使用此API,可以找到单个pipeline定义的详细信息或查找所有pipeline的定义。
查找所有pipeline定义的命令是:
GET _ingest/pipeline
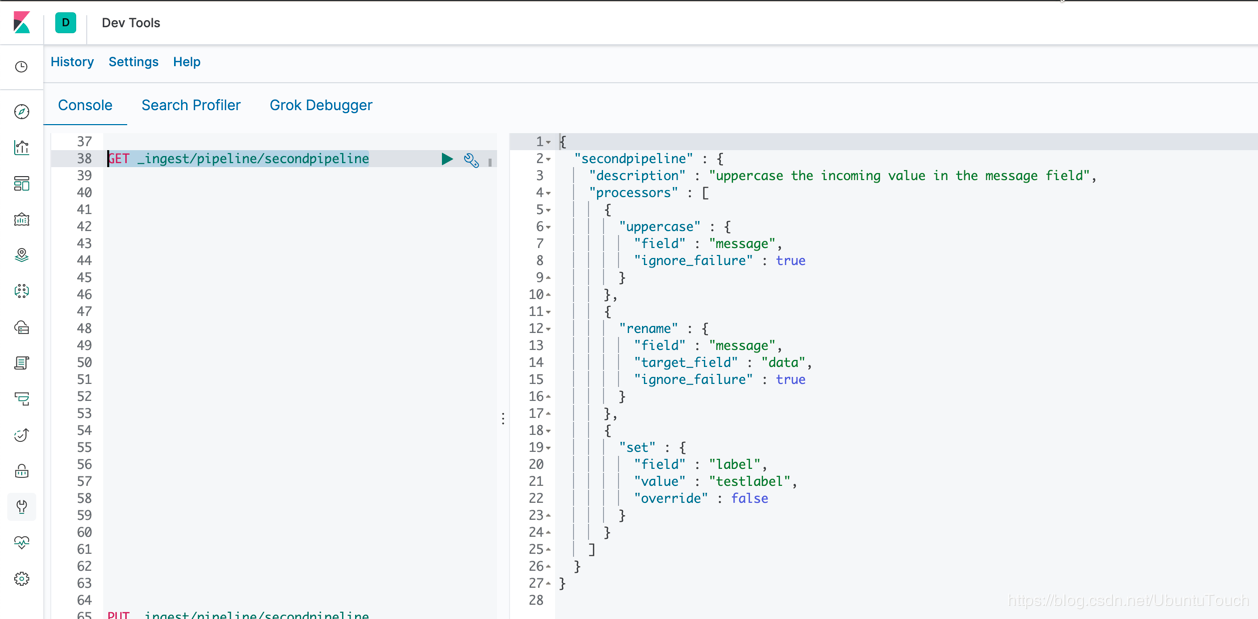
要查找现有pipeline的定义,请将管道ID传递给get管道.api。 以下是查找名为secondpipeline的pipeline定义的示例:
GET _ingest/pipeline/secondpipeline
我们也可以使用filter_path来获取pipeline的部分内容,比如:
GET _ingest/pipeline/secondpipeline?filter_path=*.processors.uppercase
上面将返回如下的结果:
{ "secondpipeline" : { "processors" : [ { "uppercase" : { "field" : "message", "ignore_failure" : true } } ] } }
上面返回processors中的uppercase内容。
删除 pipeline API
删除管道API按ID或通配符匹配删除pipeline。 以下是删除名为firstpipeline的pipeline的示例:
DELETE _ingest/pipeline/firstpipeline
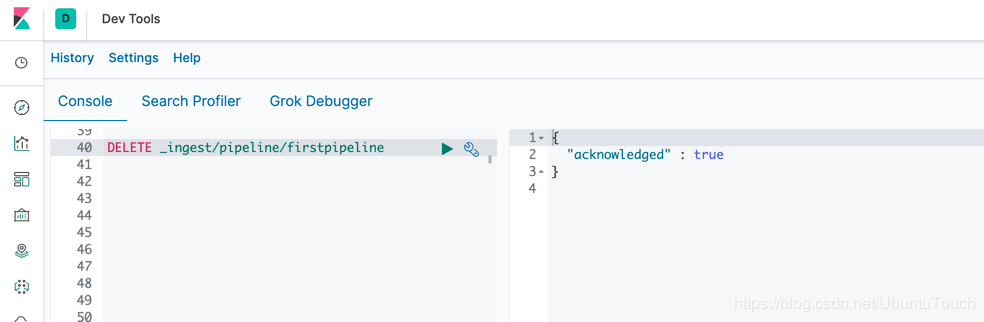
这样firstpipeline就被删除了。
由于pipeline是群集级存储而被保存在每个节点的内存中,并且pipeline始终在ingest node中运行,因此最好在群集中保留需要的pipeline,而删除那些不需要的pipeline。
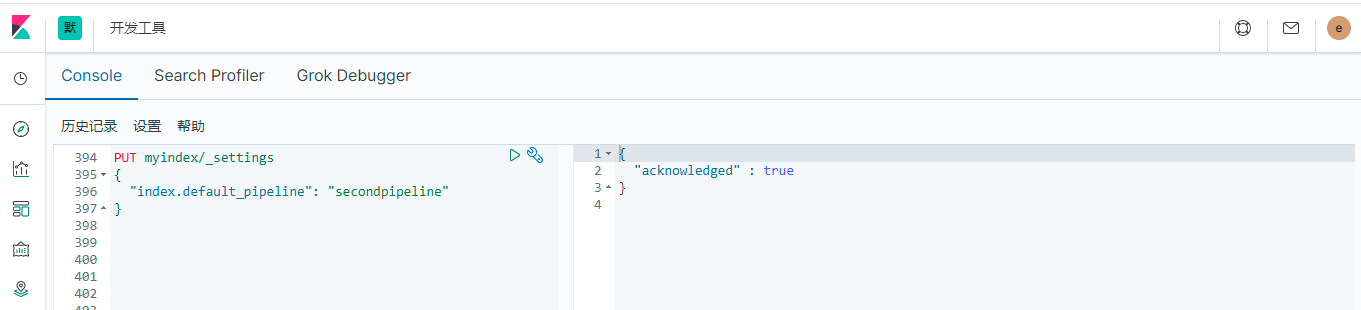
设置默认pipeline API
模拟 pipeline API
此pipeline API可用于根据请求正文中提供的文档集模拟pipeline的执行。 可以指定要对提供的文档执行的现有pipeline,或者在请求的主体中提供pipeline定义。 要模拟ingest pipeline,请将“_simulate”端点添加到pipeline API。
以下是模拟现有pipeline的示例:
POST _ingest/pipeline/secondpipeline/_simulate { "docs": [ { "_source": { "name": "pipeline", "message": "this is so cool!" } }, { "_source": { "name": "nice", "message": "this is nice!" } } ] }
执行的结果是:
我们可以在右边看出来执行pipeline所显示的结果。
内置processors
默认情况下,Elasticsearch提供大量的ingest处理器。 我们可以在地址https://www.elastic.co/guide/en/elasticsearch/reference/current/ingest-processors.html 找到已经为我设计好的内置的processors。下面是一些常见的一些processor的列表: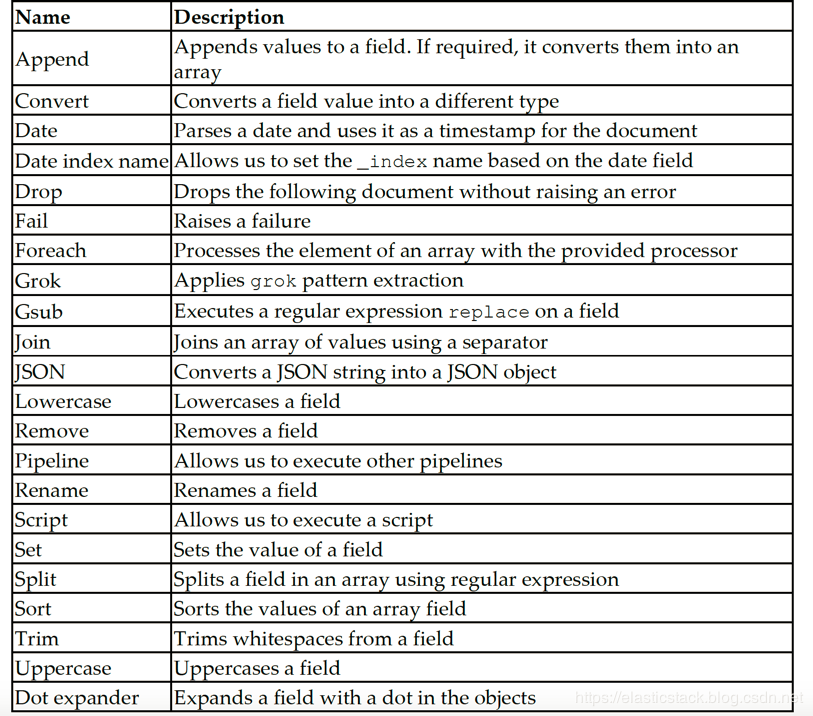


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!