
【LLM训练】从零训练一个大模型有哪几个核心步骤?
【LLM训练】从零训练一个大模型有哪几个核心步骤?
⚠︎ 重要性:★★★
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
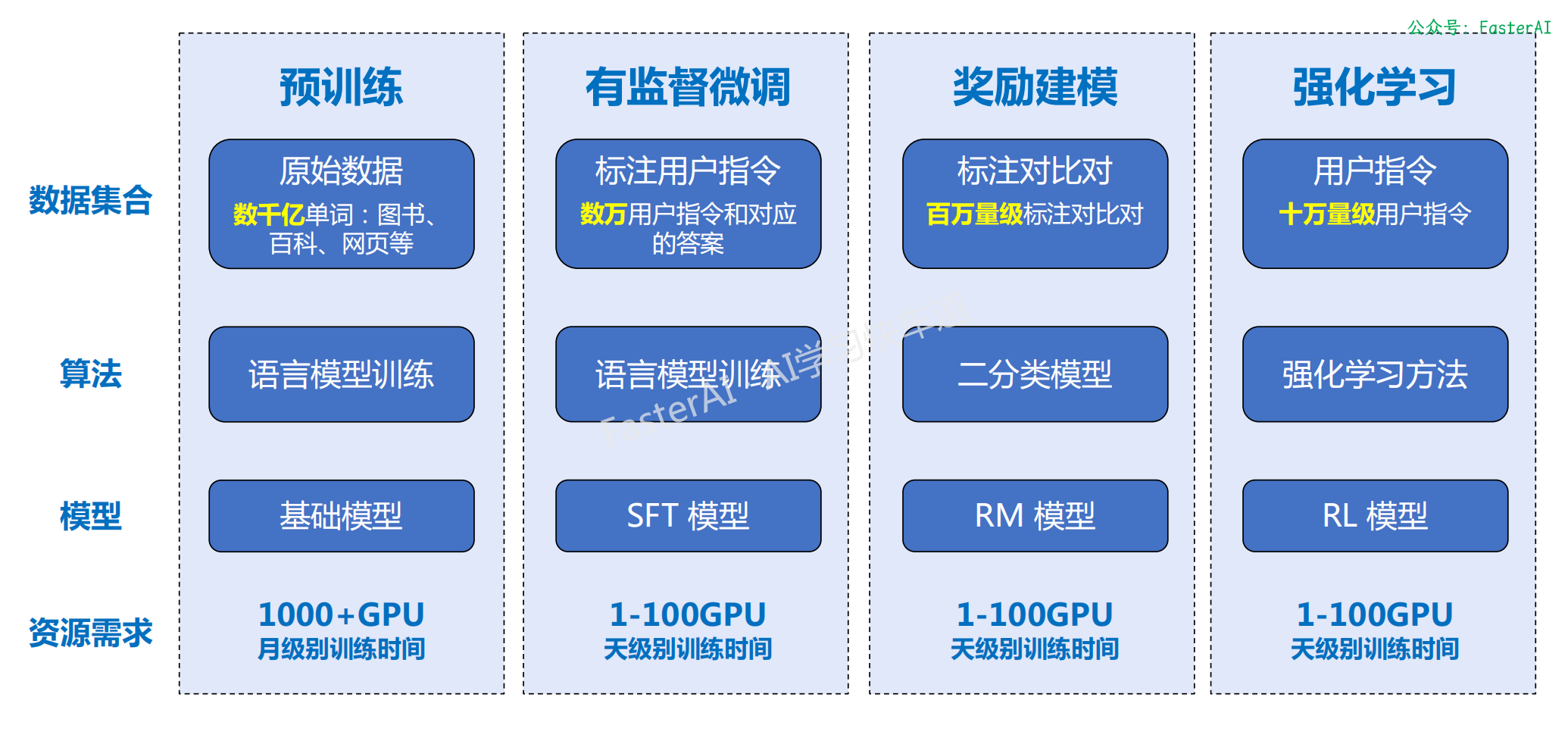
从零开始训练LLM需要如下4个核心步骤:

LLM的构建主要包含四个阶段:
- 预训练
- 有监督微调
- 奖励建模
- 强化学习
这四个阶段都需要不同规模数据集合以及不同类型的算法,会产出不同类型的模型,同时所需要的资源也有非常大的差别。
OpenAI 使用的大规模语言模型构建流程:
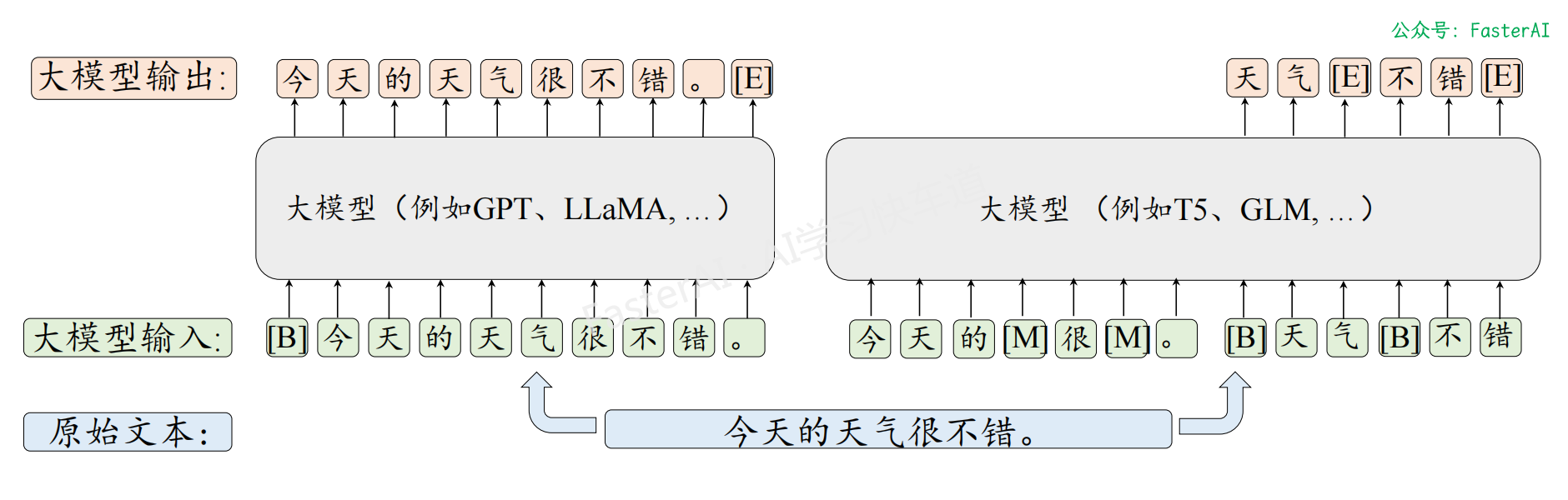
第 0 步:预训练基础大模型
目的:基于海量数据以“文字接龙”的形式构建基础语言模型。
语言建模和去噪自编码的输入输出对比:
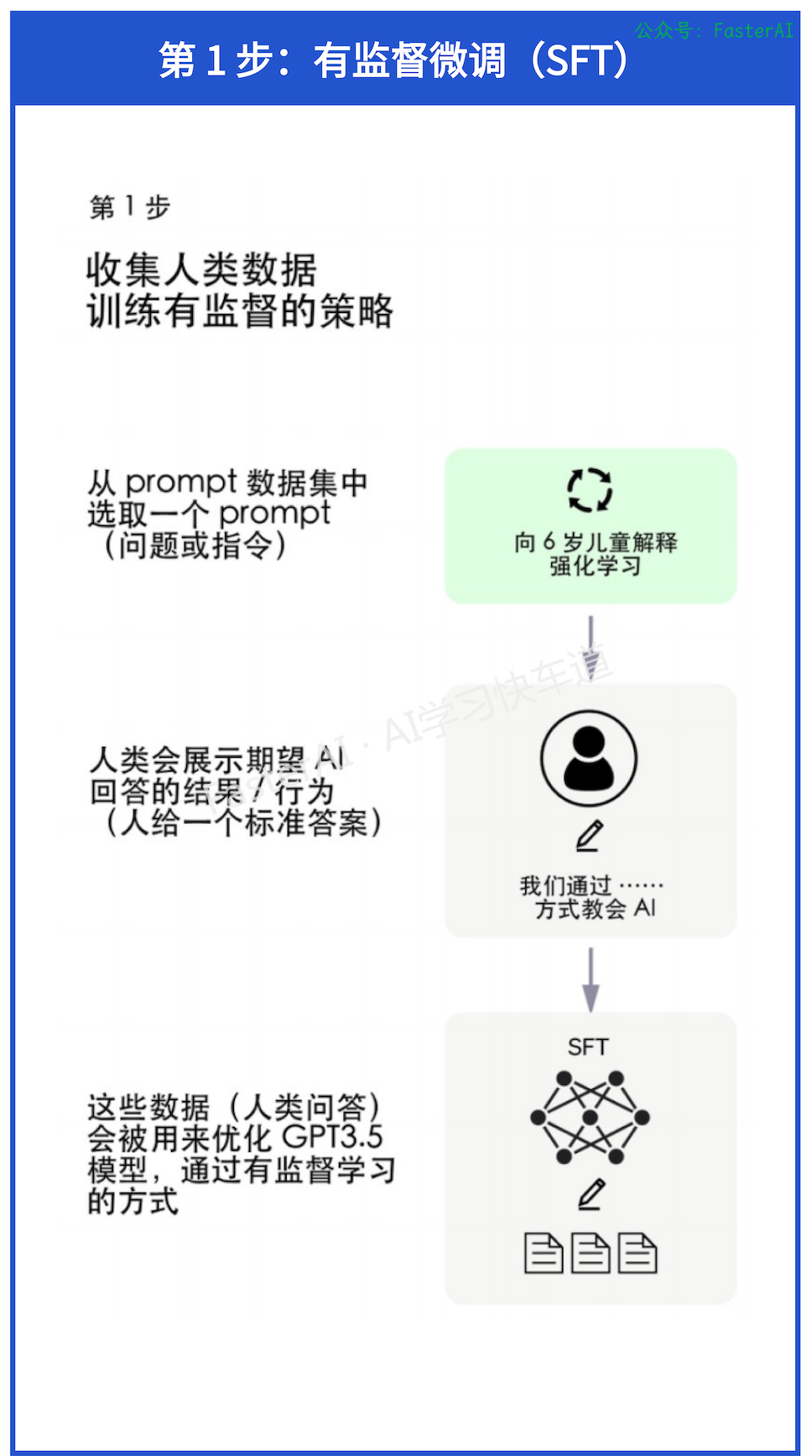
第 1 步:有监督微调(SFT)
目的:人类引导“文字接龙”的方向。利用少量高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。
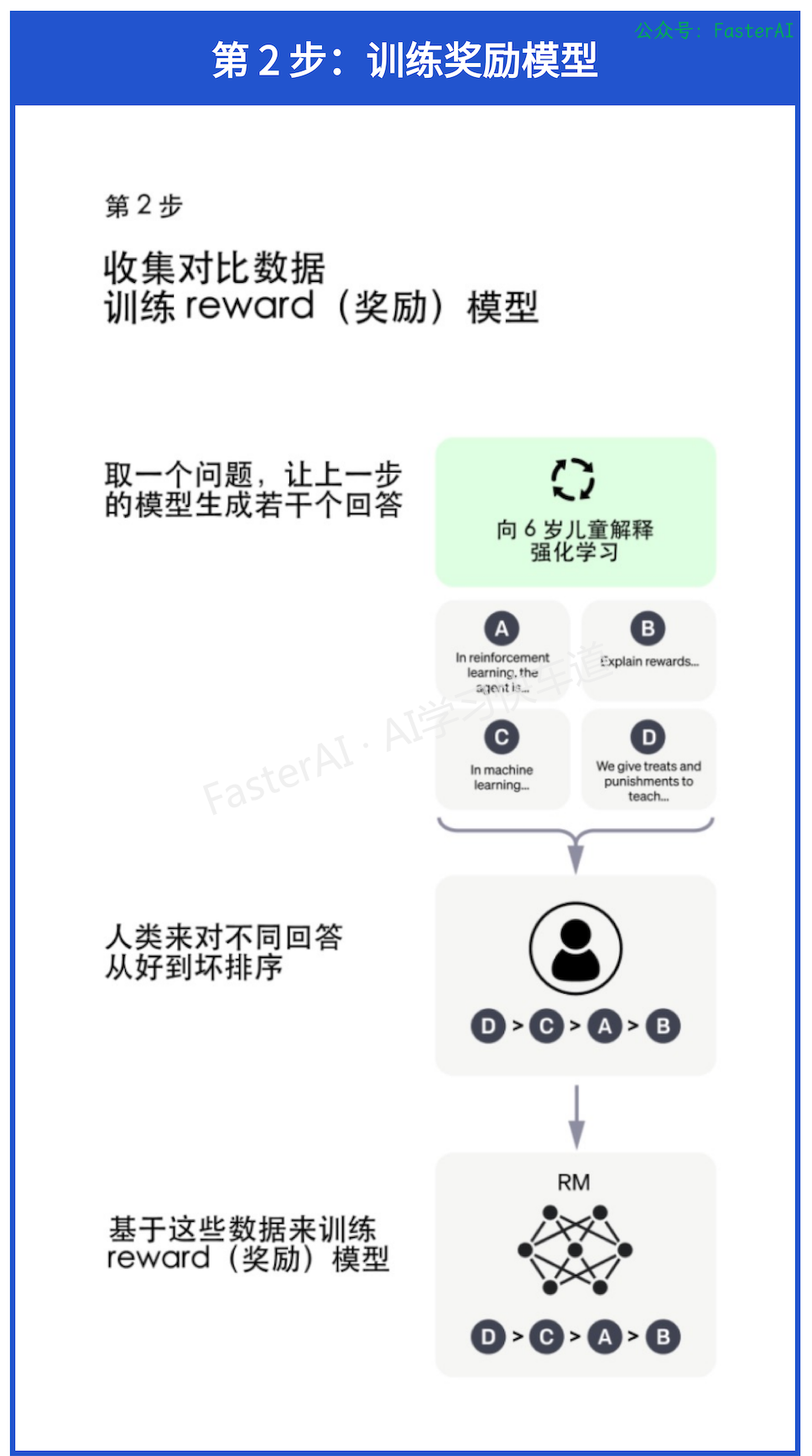
第 2 步:训练奖励模型
目的:为GPT请一个好老师。基于人类反馈训练的奖励模型可以很好的人类的偏好。从理论上来说,可以通过强化学习使用人类标注的反馈数据直接对模型进行微调。构建奖励模型(Reward Model),模拟人类的评估过程可以极大降低人类标注数据的时间和成本。奖励模型决定了智能体如何从与环境的交互中学习并优化策略,以实现预定的任务目标。
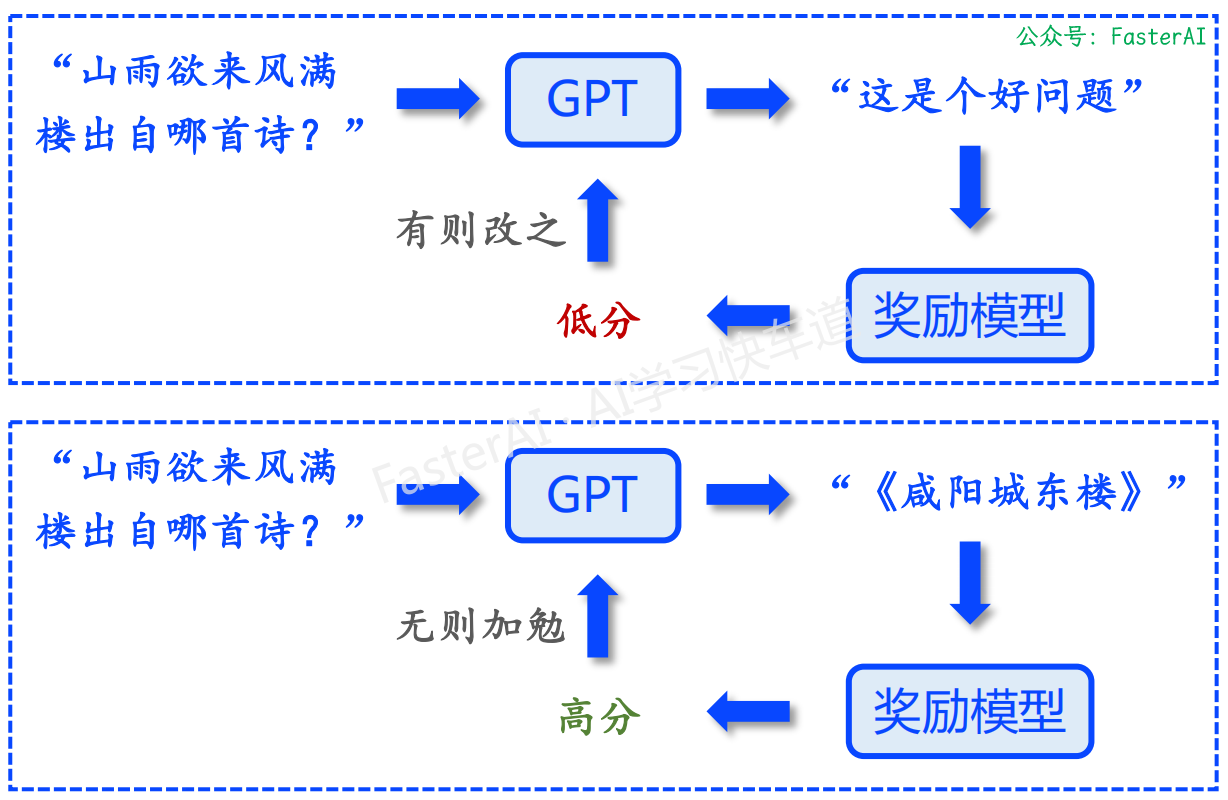
第 3 步:根据奖励模型进行强化学习
目的:AI 指导 AI,优化预训练模型。
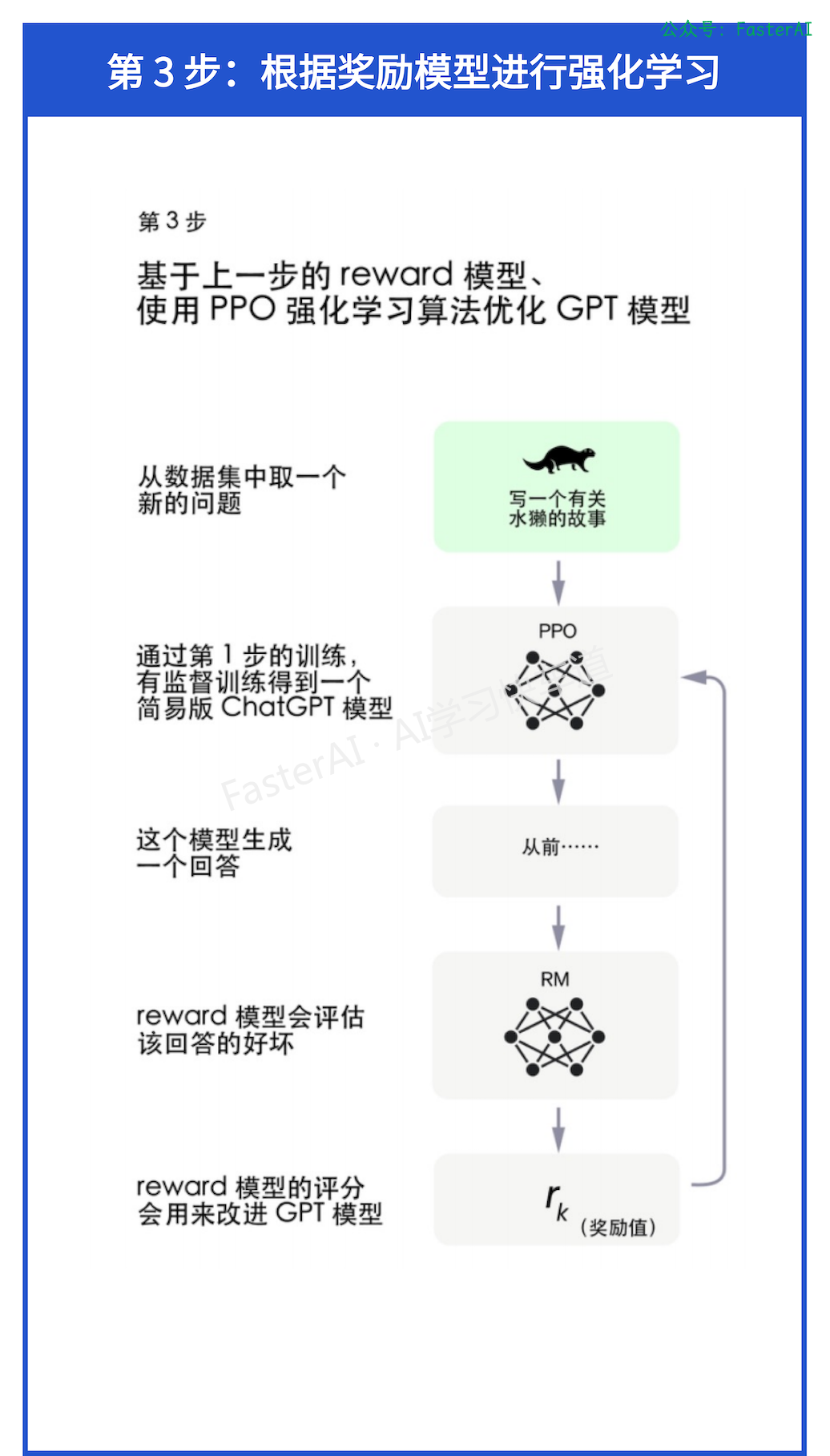
使用奖励模型强化训练基础模型:
MLP 大模型高频面题汇总
NLP基础篇
-
【NLP 面试宝典 之 模型分类】 必须要会的高频面题
-
【NLP 面试宝典 之 神经网络】 必须要会的高频面题
-
【NLP 面试宝典 之 主动学习】 必须要会的高频面题
-
【NLP 面试宝典 之 超参数优化】 必须要会的高频面题
-
【NLP 面试宝典 之 正则化】 必须要会的高频面题
-
【NLP 面试宝典 之 过拟合】 必须要会的高频面题
-
【NLP 面试宝典 之 Dropout】 必须要会的高频面题
-
【NLP 面试宝典 之 EarlyStopping】 必须要会的高频面题
-
【NLP 面试宝典 之 标签平滑】 必须要会的高频面题
-
【NLP 面试宝典 之 Warm up 】 必须要会的高频面题
-
【NLP 面试宝典 之 置信学习】 必须要会的高频面题
-
【NLP 面试宝典 之 伪标签】 必须要会的高频面题
-
【NLP 面试宝典 之 类别不均衡问题】 必须要会的高频面题
-
【NLP 面试宝典 之 交叉验证】 必须要会的高频面题
-
【NLP 面试宝典 之 词嵌入】 必须要会的高频面题
-
【NLP 面试宝典 之 One-Hot】 必须要会的高频面题
-
......
BERT 模型面
LLMs 微调面
-
【NLP 面试宝典 之 LoRA微调】 必须要会的高频面题
-
【NLP 面试宝典 之 Prompt】 必须要会的高频面题
-
【NLP 面试宝典 之 提示学习微调】 必须要会的高频面题
-
【NLP 面试宝典 之 PEFT微调】 必须要会的高频面题
-
【NLP 面试宝典 之 Chain-of-Thought微调】 必须要会的高频面题
-
......
本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号