【淘汰9成NLP面试者的高频面题】BPE 分词器是如何训练的?
**【淘汰9成NLP面试者的高频面题】BPE 分词器是如何训练的? **
︎重要性:★★
此题主要是考察面试者对分词的理解,一个好的分词器不仅能够降低词表的大小,减少OOV的出现,而且还能引入额外的先验知识,降低模型的学习难度。
这是我常用的一个面试题。看似简单的基础题,但在面试中能准确回答的不足三成,常识题的错误反而会让人印象深刻。
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
字节对编码(Byte Pair Encoding,BPE)模型是一种常见的子词词元模型。该模型所采用的词表包含最常见的单词以及高频出现的子词。
BPE是从一个小词汇表开始,根据次元成对出现的频率进行合并,合并过程将一直持续达到预定义的词表大小。
BPE算法合并的选择标准是计算两个连续词元的共现频率,也就是每次迭代中,最频繁出现的一对词元会被选择与合并。
BPE 算法中词元词表的计算过程:
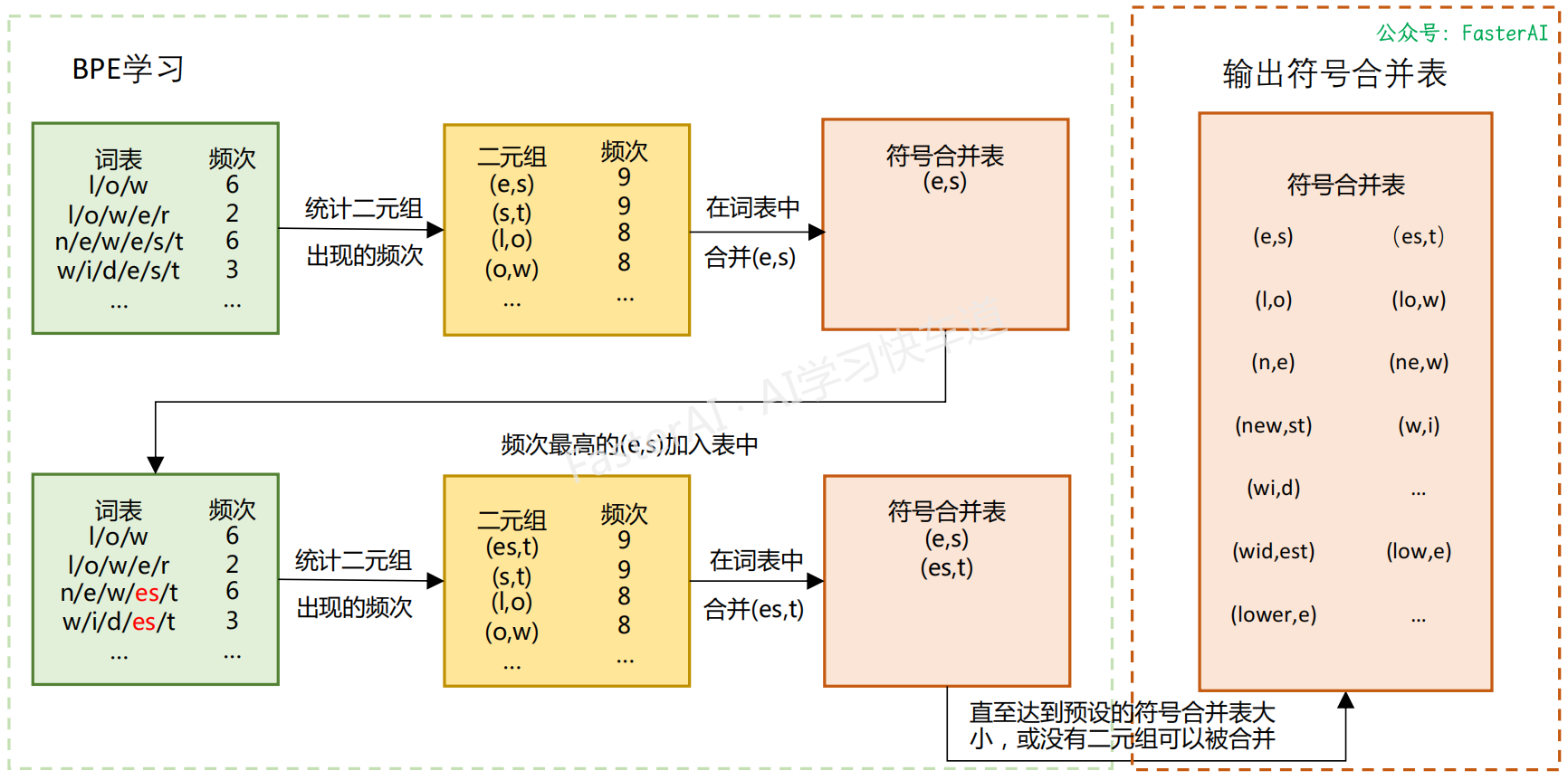
BPE 算法的具体流程示例:

BPE 算法的代码如下:
from transformers import AutoTokenizer
from collections import defaultdict
# 语料库
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
# 使用 GPT-2 tokenizer 将输入分解为单词:
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 词频
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(
text
)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
# 计算基础词典, 这里使用语料库中的所有字符:
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
# 增加特殊 Token 在字典的开头,GPT-2 中仅有一个特殊 Token``<|endoftext|>''表示文本结束
vocab = ["<|endoftext|>"] + alphabet.copy()
# 将单词切分为字符
splits = {word: [c for c in word] for word in word_freqs.keys()}
# compute_pair_freqs 函数用于计算字典中所有词元对的频率
def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
# merge_pair 函数用于合并词元对
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
# 迭代训练,每次选取得分最高词元对进行合并,直到字典大小达到设置目标为止:
vocab_size = 50
merges = {}
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
splits = merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
# 训练完成后,tokenize 函数用于给定文本进行词元切分
def tokenize(text):
pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
# 测试训练好的 BPE 模型
print(tokenize("This is not a token."))
本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号