图解内存池内部结构,看它是如何克服内存碎片化的?
内存是软件系统必不可少的物理资源,精湛的内存管理技术是确保内存使用效率的关键,也是进阶高级研发的必备技巧。为提高内存分配效率,Python 内部做了很多殚心竭虑的优化,从中我们可以获得一些启发。
开始研究 Python 内存池之前,我们先大致了解下 Python 内存管理层次:

众所周知,计算机硬件资源由操作系统负责管理,内存资源也不例外。应用程序通过 系统调用 向操作系统申请内存,而 C 库函数则进一步将系统调用封装成通用的 内存分配器 ,并提供了 malloc 系列函数。
C 库函数实现的通用目的内存管理器是一个重要的分水岭,即内存管理层次中的 第0层 。此层之上是应用程序自己的内存管理,此层之下则是隐藏在冰山下方的操作系统部分。
操作系统内部是一个基于页表的虚拟内存管理器(第-1层),以 页 ( page )为单位管理内存,CPU 内存管理单元( MMU )在这个过程中发挥重要作用。虚拟内存管理器下方则是底层存储设备(第-2层),直接管理物理内存以及磁盘等二级存储设备。
绿色部分则是 Python 自己的内存管理,分为 3 层:
- 第 1 层,是一个内存分配器,接管一切内存分配,内部是本文的主角—— 内存池 ;
- 第 2 层,在第 1 层提供的统一 PyMem_XXXX 接口基础上,实现统一的对象内存分配( object.tp_alloc );
- 第 3 层,为特定对象服务,例如前面章节介绍的 float 空闲对象缓存池;
那么,Python 为什么不直接使用 malloc 系列函数,而是自己折腾一遍呢?原因主要是以下几点:
- 引入内存池,可化解对象频繁创建销毁带来的内存分配压力;
- 最大程度避免内存碎片化,提升内存利用效率;
- malloc 有很多实现版本,不同实现性能千差万别;
内存碎片的挑战
内存碎片化 是困扰经典内存分配器的一大难题,碎片化导致的结果也是惨重的。这是一个典型的内存碎片化例子:
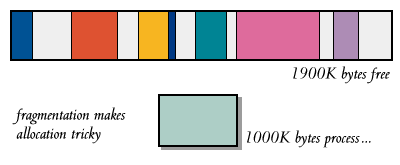
虽然还有 1900K 的空闲内存,但都分散在一系列不连续的碎片上,甚至无法成功分配出 1000K 。
那么,如何避免内存碎片化呢?想要解决问题,必先分析导致问题的根源。
我们知道,应用程序请求内存块尺寸是不确定的,有大有小;释放内存的时机也是不确定的,有先有后。经典内存分配器将不同尺寸内存块混合管理,按照先来后到的顺序分配:

当大块内存回收后,可以被分为更小的块,然后分配出去:

而先分配的内存块未必先释放,慢慢地空洞就出现了:

随着时间的推移,碎片化会越来越严重,最终变得支离破碎:

由此可见,将不同尺寸内存块混合管理,将大块内存切分后再次分配的做法是罪魁祸首。
按尺寸分类管理
揪出内存碎片根源后,解决方案也就浮出水面了——根据内存块尺寸,将内存空间划分成不同区域,独立管理。举个最简单的例子:
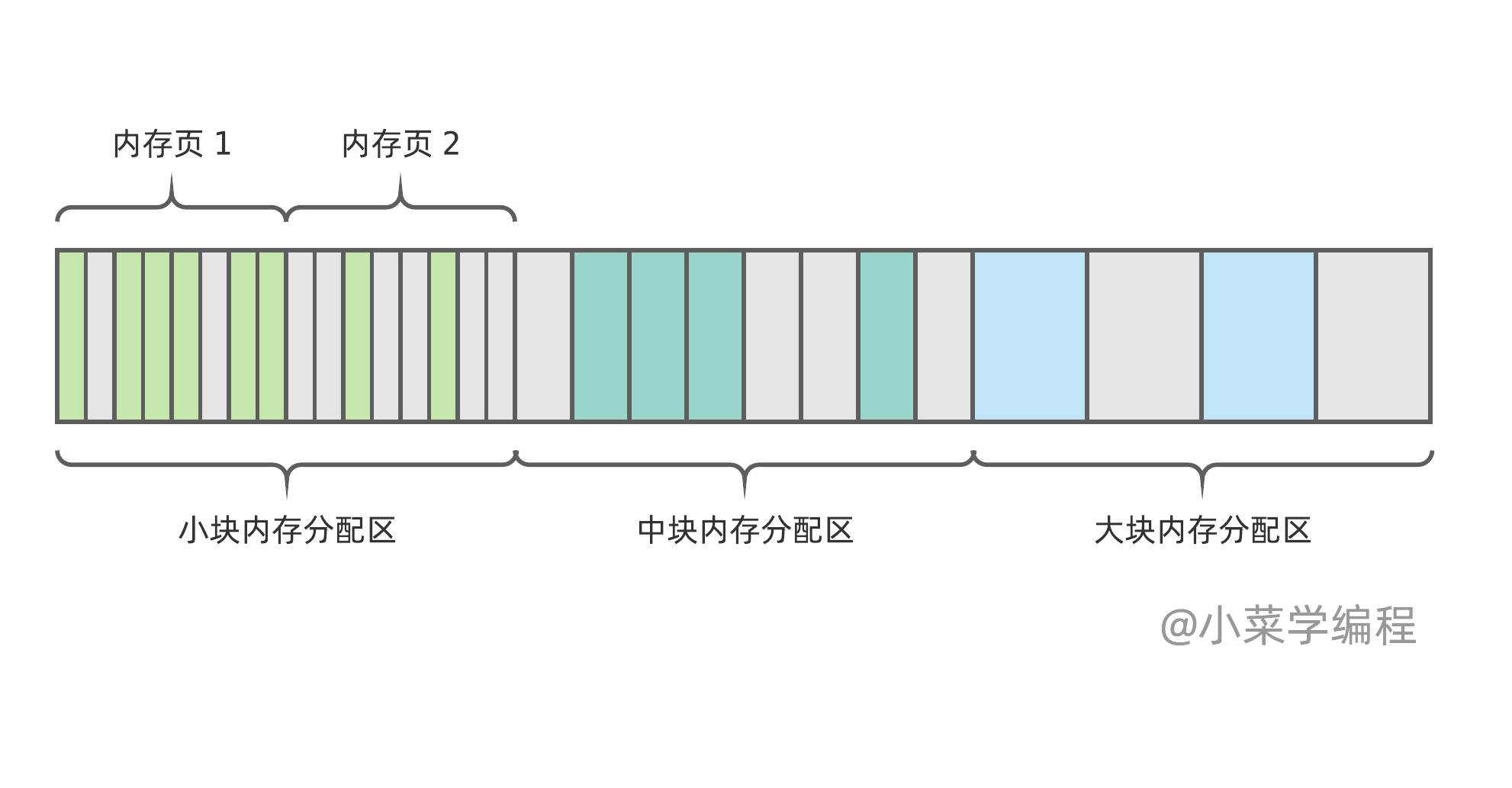
如图,内存被划分成小、中、大三个不同尺寸的区域,区域可由若干内存页组成,每个页都划分为统一规格的内存块。这样一来,小块内存的分配,不会影响大块内存区域,使其碎片化。
每个区域的碎片仍无法完全避免,但这些碎片都是可以被重新分配出去的,影响不大。此外,通过优化分配策略,碎片还可被进一步合并。以小块内存为例,新内存优先从内存页 1 分配,内存页 2 将慢慢变空,最终将被整体回收。
在 Python 虚拟机内部,时刻有对象创建、销毁,这引发频繁的内存申请、释放动作。这类内存尺寸一般不大,但分配、释放频率非常高,因此 Python 专门设计 内存池 对此进行优化。
那么,尺寸多大的内存才会动用内存池呢?Python 以 512 字节为限,小于 512 的内存分配才会被内存池接管:
- 0 ,直接调用 malloc 函数;
- 1 ~ 512 ,由专门的内存池负责分配,内存池以内存尺寸进行划分;
- 512 以上,直接调动 malloc 函数;
那么,Python 是否为每个尺寸的内存都准备一个独立内存池呢?答案是否定的,愿意有几个:
- 内存规格有 512 种之多,如果内存池分也分 512 种,徒增复杂性;
- 内存池种类越多,额外开销越大;
- 如果某个尺寸内存只申请一次,将浪费内存页内其他空闲内存;
相反,Python 以 8 字节为梯度,将内存块分为:8 字节、16 字节、24 字节,以此类推。总共 64 种:
| 请求大小 | 分配内存块大小 | 类别编号 |
|---|---|---|
| 1 ~ 8 | 8 | 0 |
| 9 ~ 16 | 16 | 1 |
| 17 ~ 24 | 24 | 2 |
| 25 ~ 32 | 32 | 3 |
| ... | ... | ... |
| 497 ~ 504 | 504 | 62 |
| 505 ~ 512 | 512 | 63 |
以 8 字节内存块为例,内存池由多个 内存页 ( page ,一般是 4K )构成,每个内存页划分为若干 8 字节内存块:

上图表示一个内存页,每个小格表示 1 字节,8 个字节组成一个块( block )。灰色表示空闲内存块,蓝色表示已分配内存块,深蓝色表示应用内存请求大小。
只要请求的内存大小不超过 8 字节,Python 都在这个内存池为其分配一块 8 字节内存,就算只申请 1 字节内存也是如此。
这种做法好处显而易见,前面提到的问题均得到解决,还带来另一个好处:内存起始地址均以计算机字为单位对齐。计算机以 字 ( word )为单位访问内存,因此内存以字对齐可提升内存读写速度。字大小从早期硬件的 2 字节、4 字节,慢慢发展到现在的 8 字节,甚至 16 字节。
当然了,有得必有失,内存利用率成了被牺牲的因素,平均利用率为 (1+8)/2/8*100% ,大约只有 56.25% 。
乍然一看,内存利用率有些惨不忍睹,但这只是 8 字节内存块的平均利用率。如果考虑所有内存块的平均利用率,其实数值并不低——可以达到 98.65% 呢!计算方法如下:
# 请求内存总量
total_requested = 0
# 实际分配内存总量
total_allocated = 0
# 请求内存从1到512字节
for i in range(1, 513):
total_requested += i
# 实际分配内存为请求内存向上对齐为8的整数倍
total_allocated += (i+7)//8*8
print('{:.2f}%'.format(total_requested/total_allocated*100))
# 98.65%
内存池实现
pool
铺垫了这么多,终于可以开始研究源码,窥探 Python 内存池实现的秘密了,源码位于 Objects/obmalloc.c 。在源码中,我们发现对于 64 位系统,Python 将内存块大小定义为 16 字节的整数倍,而不是上述的 8 字节:
#if SIZEOF_VOID_P > 4
#define ALIGNMENT 16 /* must be 2^N */
#define ALIGNMENT_SHIFT 4
#else
#define ALIGNMENT 8 /* must be 2^N */
#define ALIGNMENT_SHIFT 3
#endif
为画图方便,我们仍然假设内存块为 8 字节的整数倍,即(实际上,这些宏定义也是可配置的):
#define ALIGNMENT 8
#define ALIGNMENT_SHIFT 3
下面这个宏将类别编号转化成块大小,例如将类别 1 转化为块大小 16 :
#define INDEX2SIZE(I) (((uint)(I) + 1) << ALIGNMENT_SHIFT)
Python 每次申请一个 内存页 ( page ),然后将其划分为统一尺寸的 内存块 ( block ),一个内存页大小是 4K :
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
#define POOL_SIZE SYSTEM_PAGE_SIZE
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
Python 将内存页看做是由一个个内存块组成的池子( pool ),内存页开头是一个 pool_header 结构,用于组织当前页,并记录页中的空闲内存块:
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* number of allocated blocks */
block *freeblock; /* pool's free list head */
struct pool_header *nextpool; /* next pool of this size class */
struct pool_header *prevpool; /* previous pool "" */
uint arenaindex; /* index into arenas of base adr */
uint szidx; /* block size class index */
uint nextoffset; /* bytes to virgin block */
uint maxnextoffset; /* largest valid nextoffset */
};
- count ,已分配出去的内存块个数;
- freeblock ,指向空闲块链表的第一块;
- nextpool ,用于将 pool 组织成链表的指针,指向下一个 pool ;
- prevpool ,用于将 pool 组织成链表的指针,指向上一个 pool ;
- szidx ,尺寸类别编号;
- nextoffset ,下一个未初始化内存块的偏移量;
- maxnextoffset ,合法内存块最大偏移量;
当 Python 通过内存池申请内存时,如果没有可用 pool ,内存池将新申请一个 4K 页,并进行初始化。注意到,由于新内存页总是由内存请求触发,因此初始化时第一个内存块便已经被分配出去了:
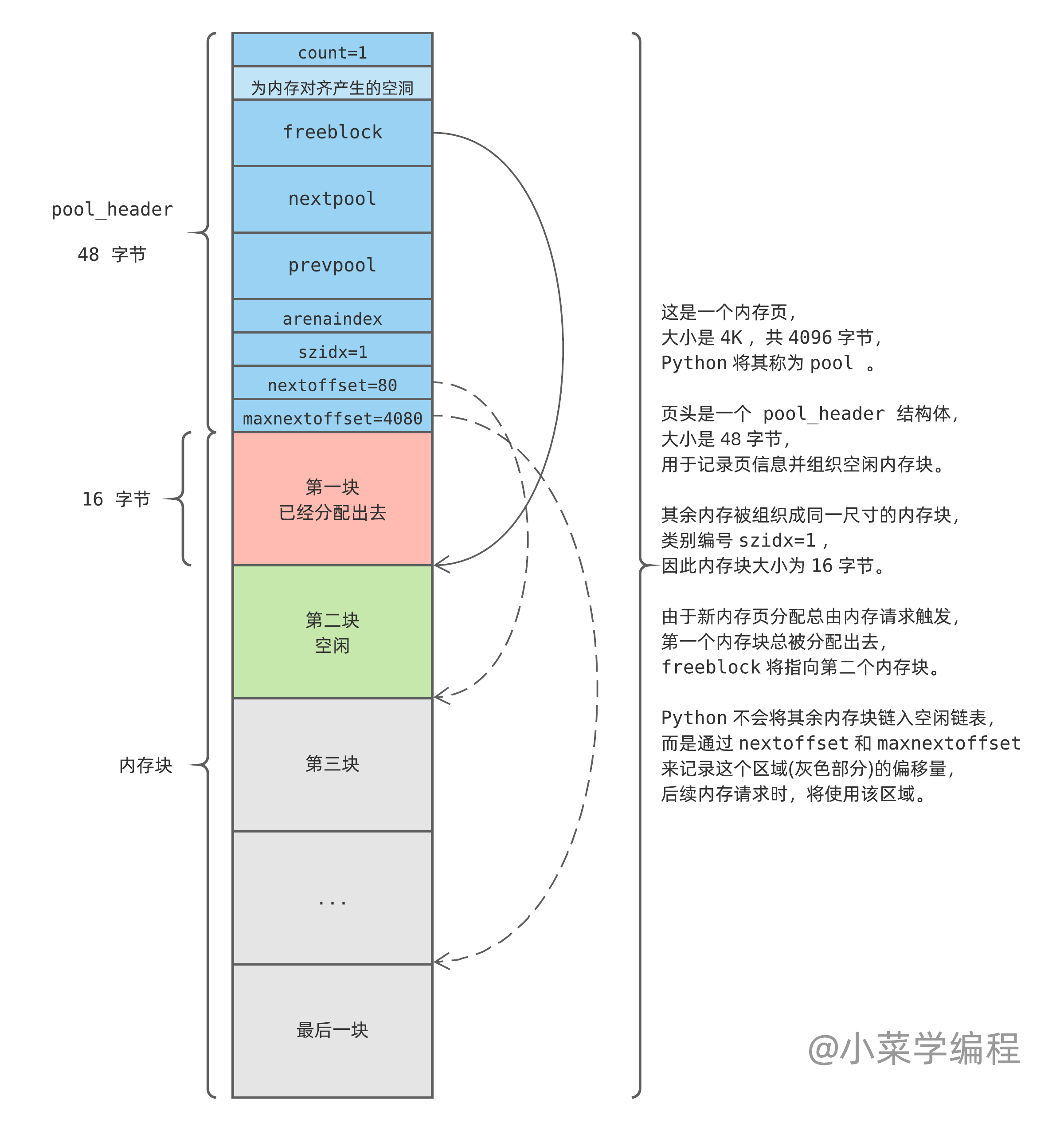
随着内存分配请求的发起,空闲块将被分配出去。Python 将从灰色区域取出下一个作为空闲块,直到灰色块用光:
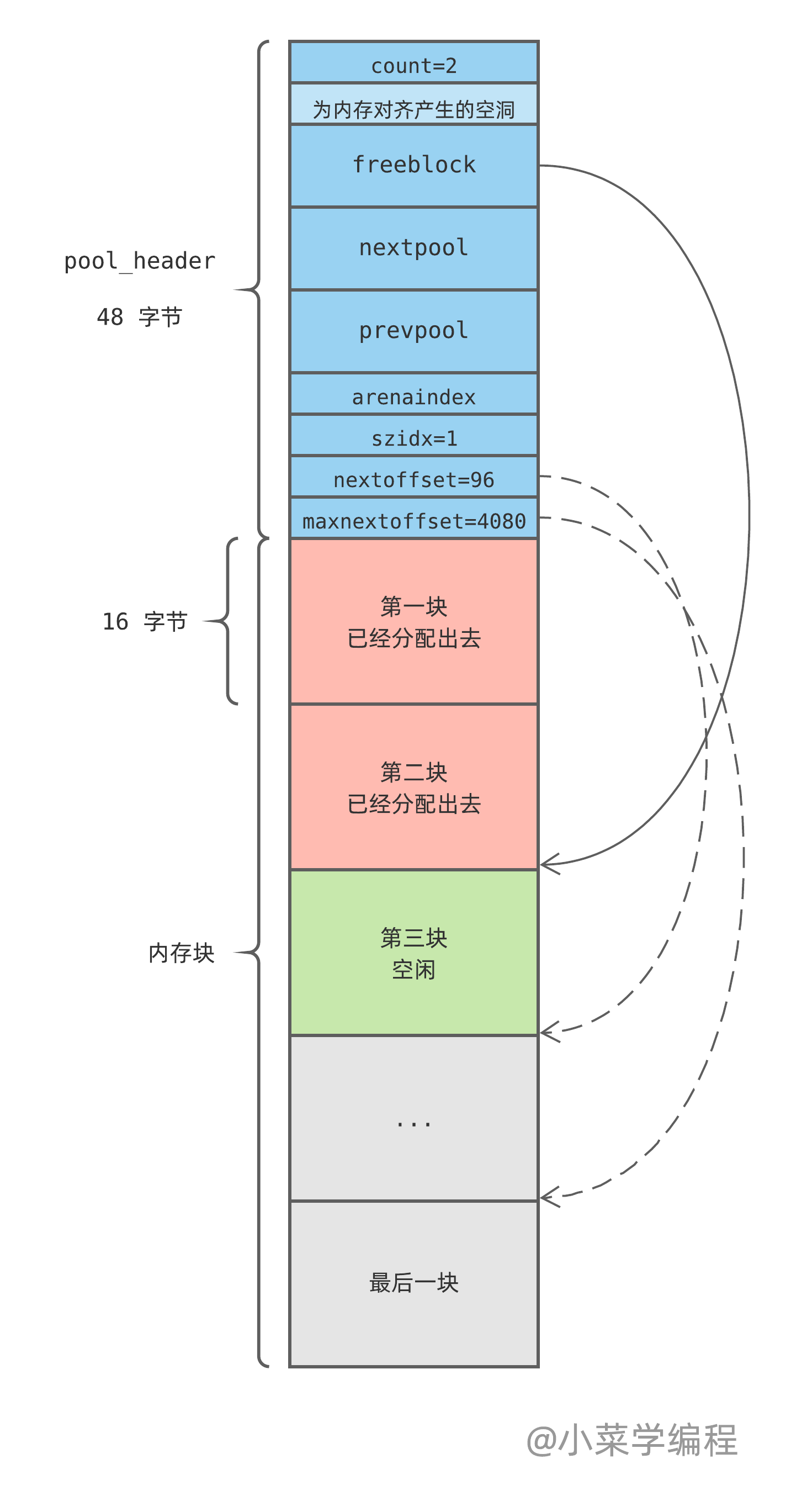
当有内存块被释放时,比如第一块,Python 将其链入空闲块链表头。请注意空闲块链表的组织方式——每个块头部保存一个 next 指针,指向下一个空闲块:
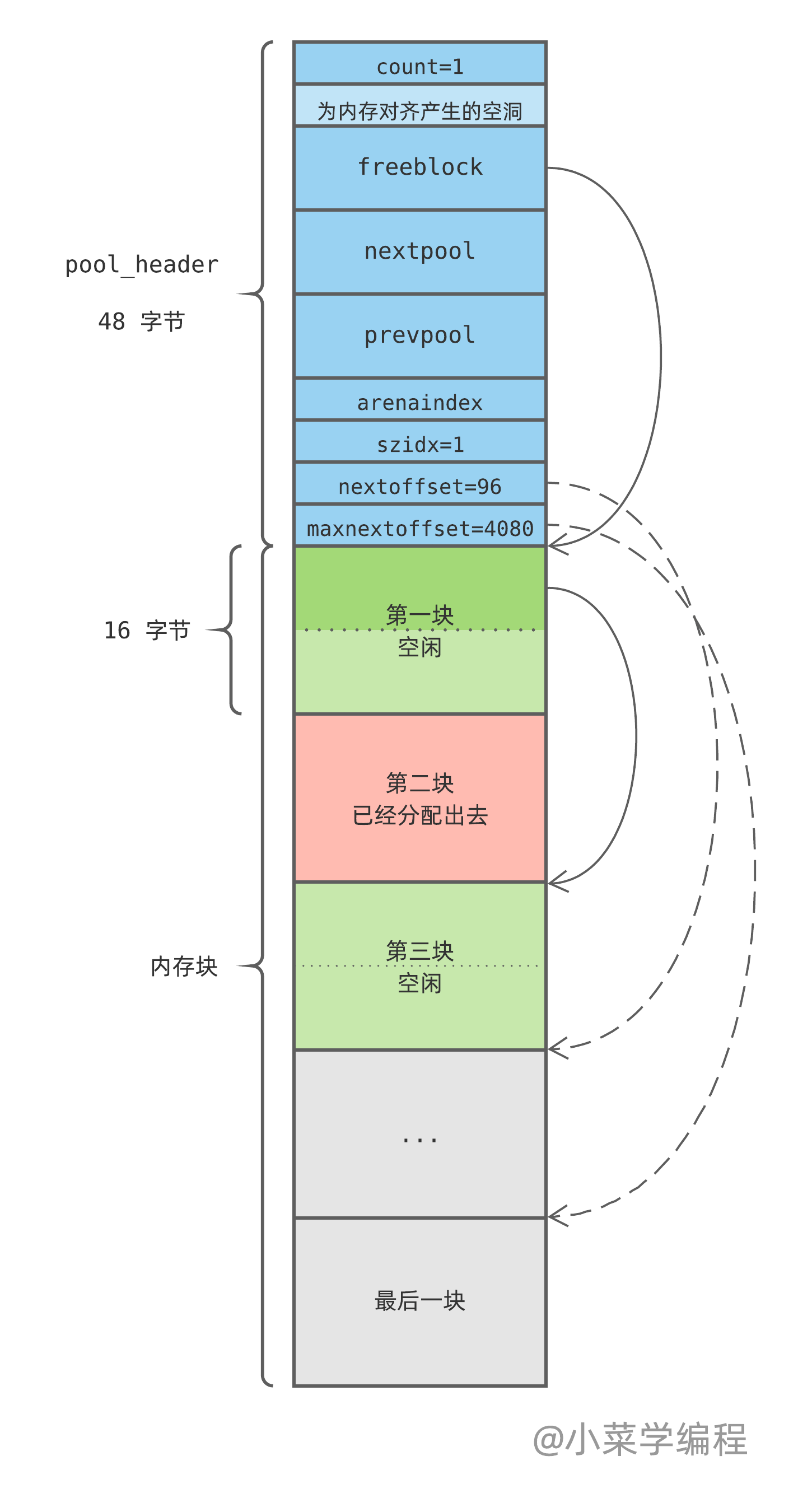
这样一来,一个 pool 在其生命周期内,可能处于以下 3 种状态(空闲内存块链表结构被省略,请自行脑补):
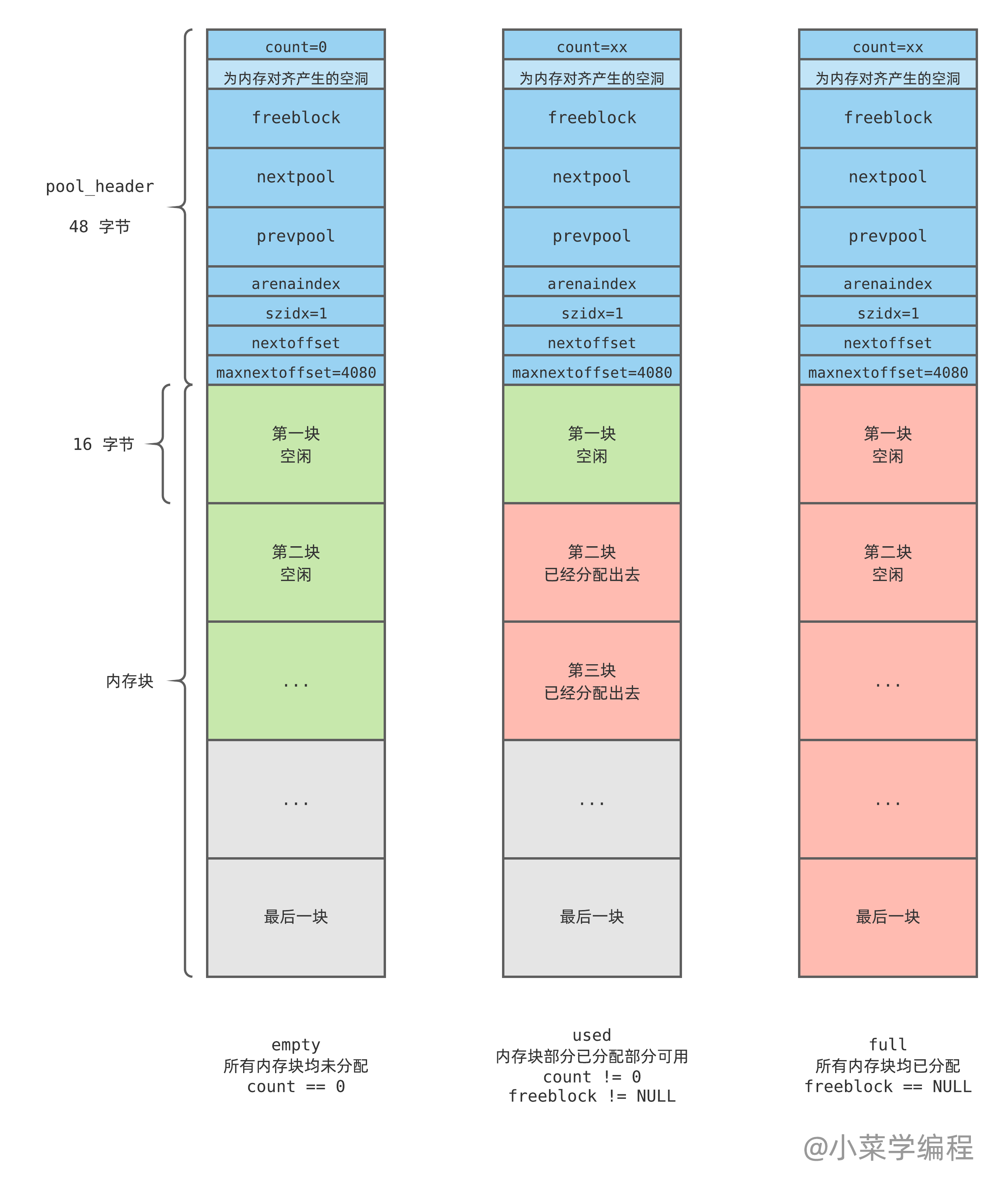
- empty ,完全空闲 状态,内部所有内存块都是空闲的,没有任何块已被分配,因此 count 为 0 ;
- used ,部分使用 状态,内部内存块部分已被分配,但还有另一部分是空闲的;
- full ,完全用满 状态,内部所有内存块都已被分配,没有任何空闲块,因此 freeblock 为 NULL ;
为什么要讨论 pool 状态呢?——因为 pool 的状态决定 Python 对它的处理策略:
- 如果 pool 完全空闲,Python 可以将它占用的内存页归还给操作系统,或者缓存起来,后续需要分配新 pool 时直接拿来用;
- 如果 pool 完全用满,Python 就无须关注它了,将它丢到一边;
- 如果 pool 只是部分使用,说明它还有内存块未分配,Python 则将它们以 双向循环链表 的形式组织起来;
可用 pool 链表
由于 used 状态的 pool 只是部分使用,内部还有内存块未分配,将它们组织起来可供后续分配。Python 通过 pool_header 结构体中的 nextpool 和 prevpool 指针,将他们连成一个双向循环链表:
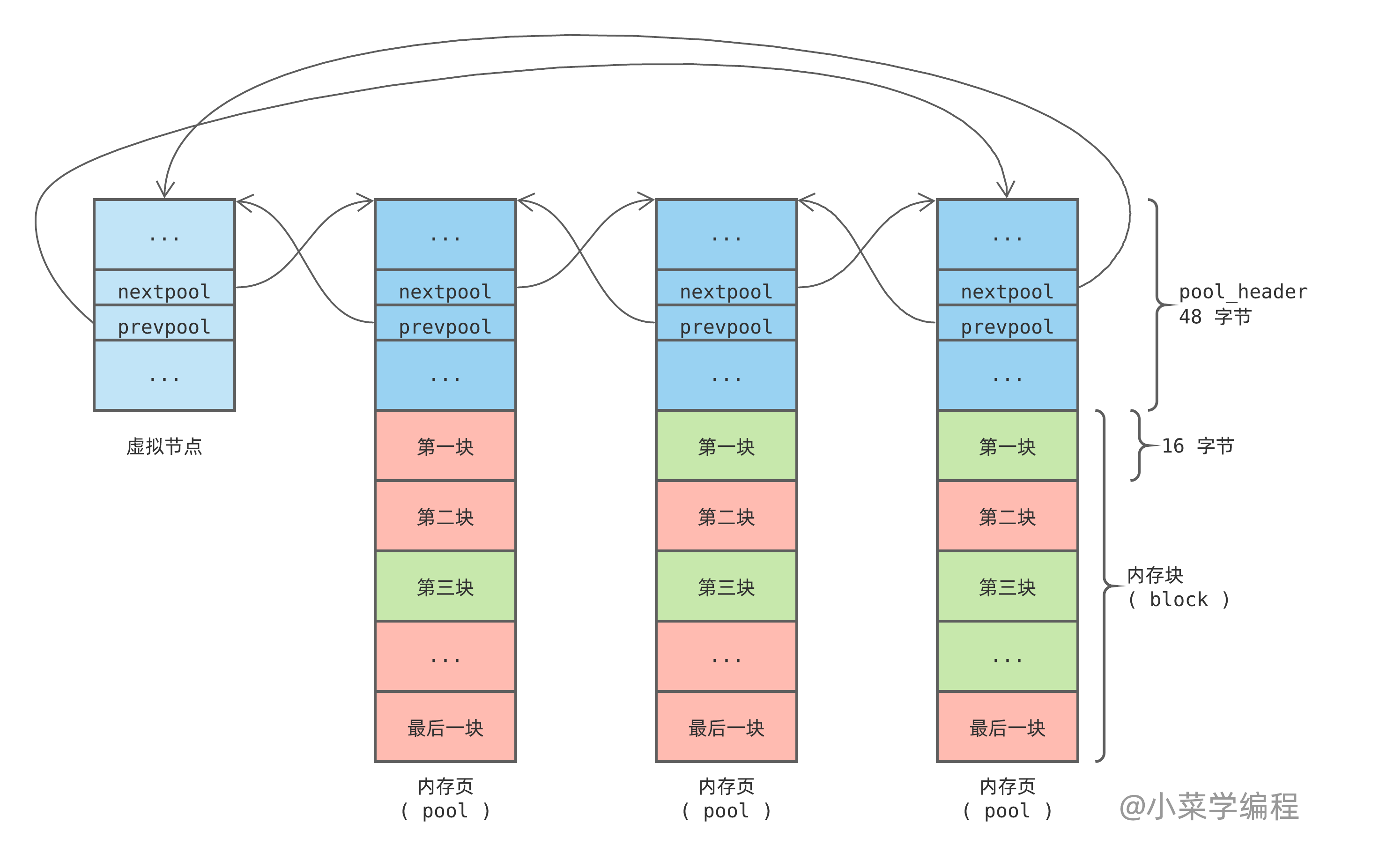
注意到,同个可用 pool 链表中的内存块大小规格都是一样的,上图以 16 字节类别为例。另外,为了简化链表处理逻辑,Python 引入了一个虚拟节点,这是一个常见的 C 语言链表实现技巧。一个空的 pool 链表是这样的,判断条件是 pool->nextpool == pool :

虚拟节点只参与链表维护,并不实际管理内存块。因此,无须为虚拟节点分配一个完整的 4K 内存页,64 字节的 pool_header 结构体足矣。实际上,Python 作者们更抠,只分配刚好足够 nextpool 和 prevpool 指针用的内存,手法巧妙得令人瞠目结舌,我们稍后再表。
Python 优先从链表第一个 pool 分配内存块,如果 pool 用满则将其从链表中剔除:
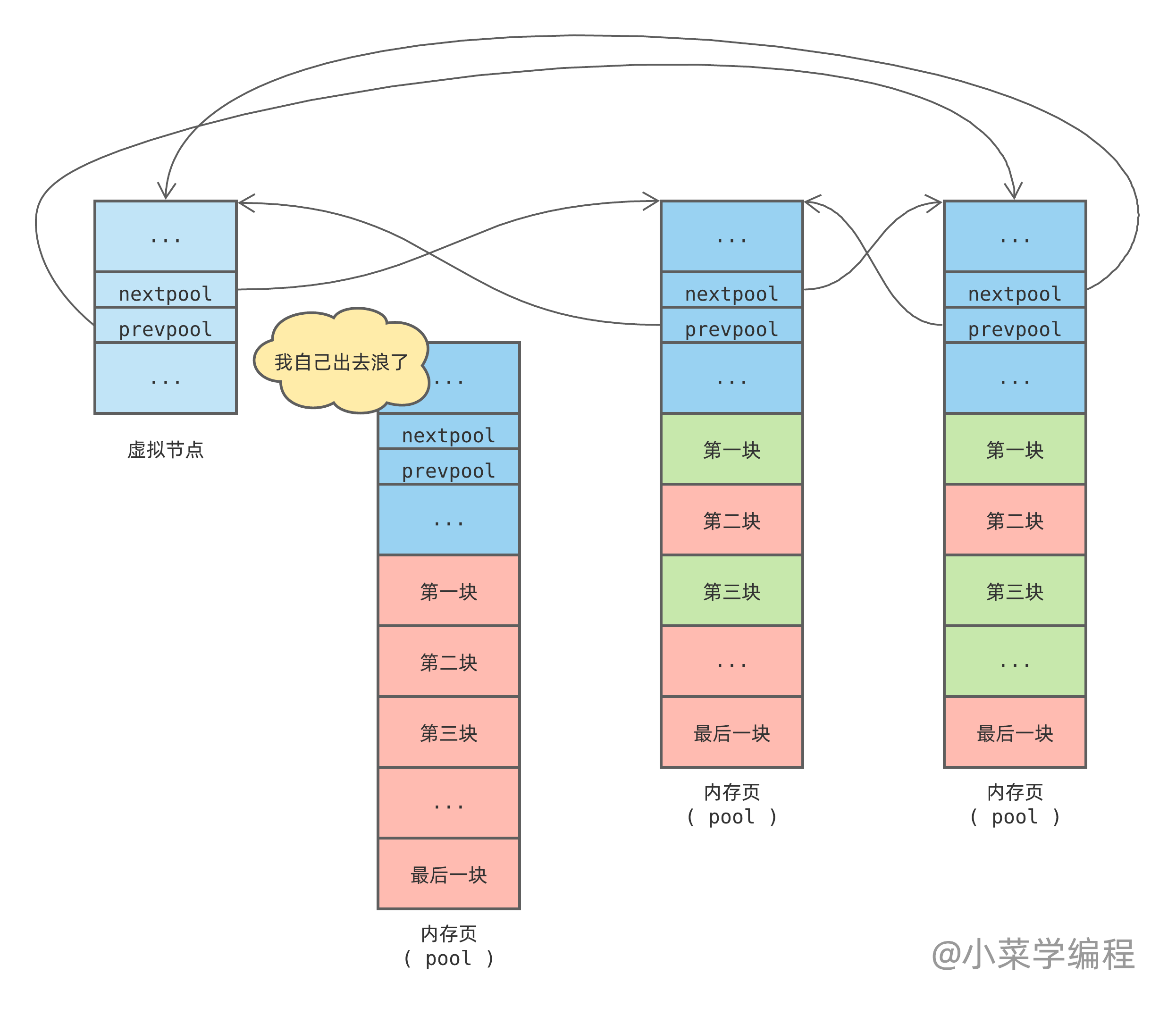
当一个内存块( block )被回收,Python 根据块地址计算得到 pool 地址。计算方法是大概是这样的:将 block 地址对齐为内存页( pool )尺寸的整数倍,便得到 pool 地址,具体请参看源码中的宏定义 POOL_ADDR 。
得到 pool 地址后,Python 将空闲内存块插到空闲内存块链表头部。如果 pool 状态是由 完全用满 ( full )变为 可用 ( used ),Python 还会将它插回可用 pool 链表头部:
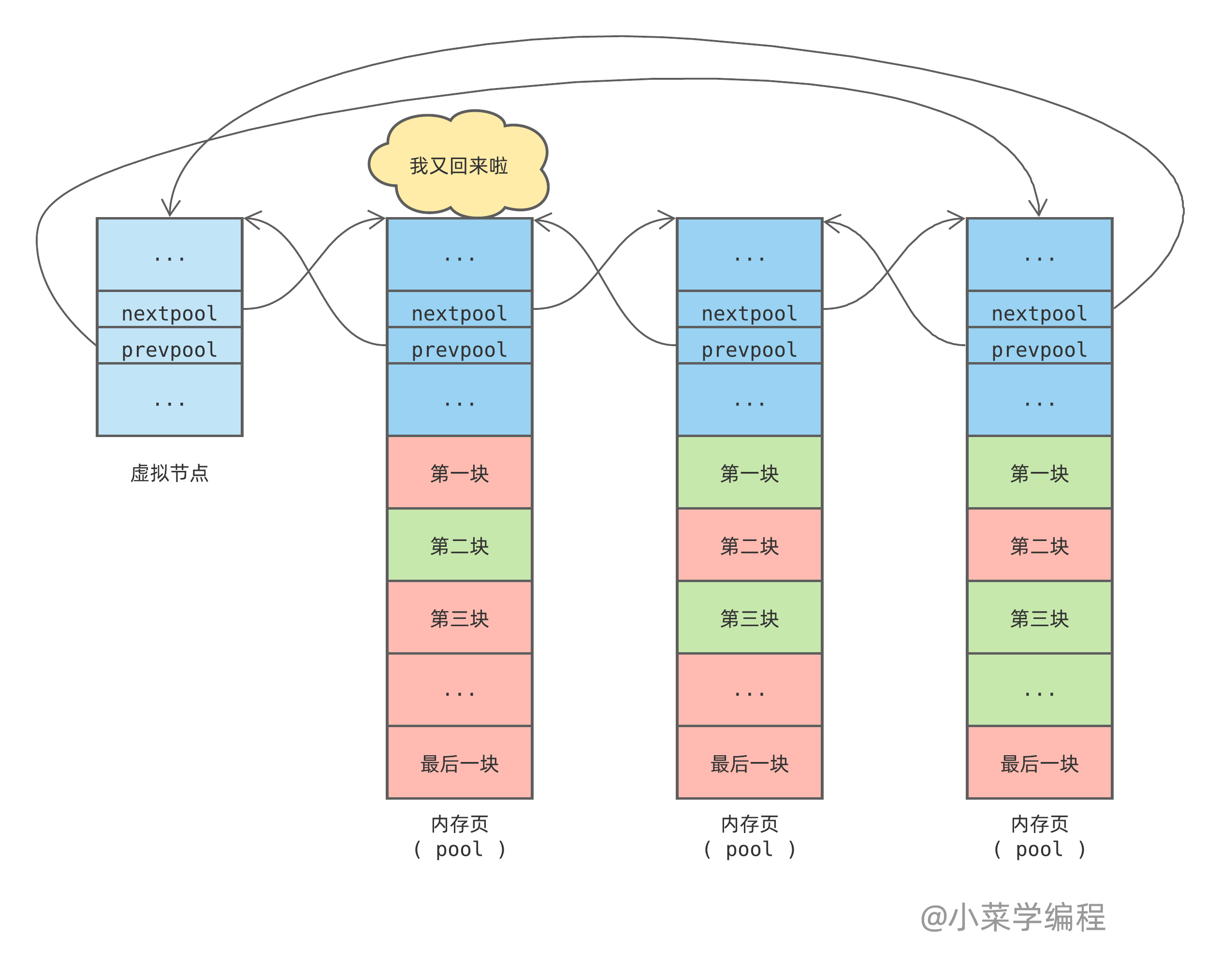
插到可用 pool 链表头部是为了保证比较满的 pool 在链表前面,以便优先使用。位于尾部的 pool 被使用的概率很低,随着时间的推移,更多的内存块被释放出来,慢慢变空。因此,pool 链表明显头重脚轻,靠前的 pool 比较满,而靠后的 pool 比较空,正如上图所示。
当一个 pool 所有内存块( block )都被释放,状态就变为 完全空闲( empty )。Python 会将它移出链表,内存页可能直接归还给操作系统,或者缓存起来以备后用:
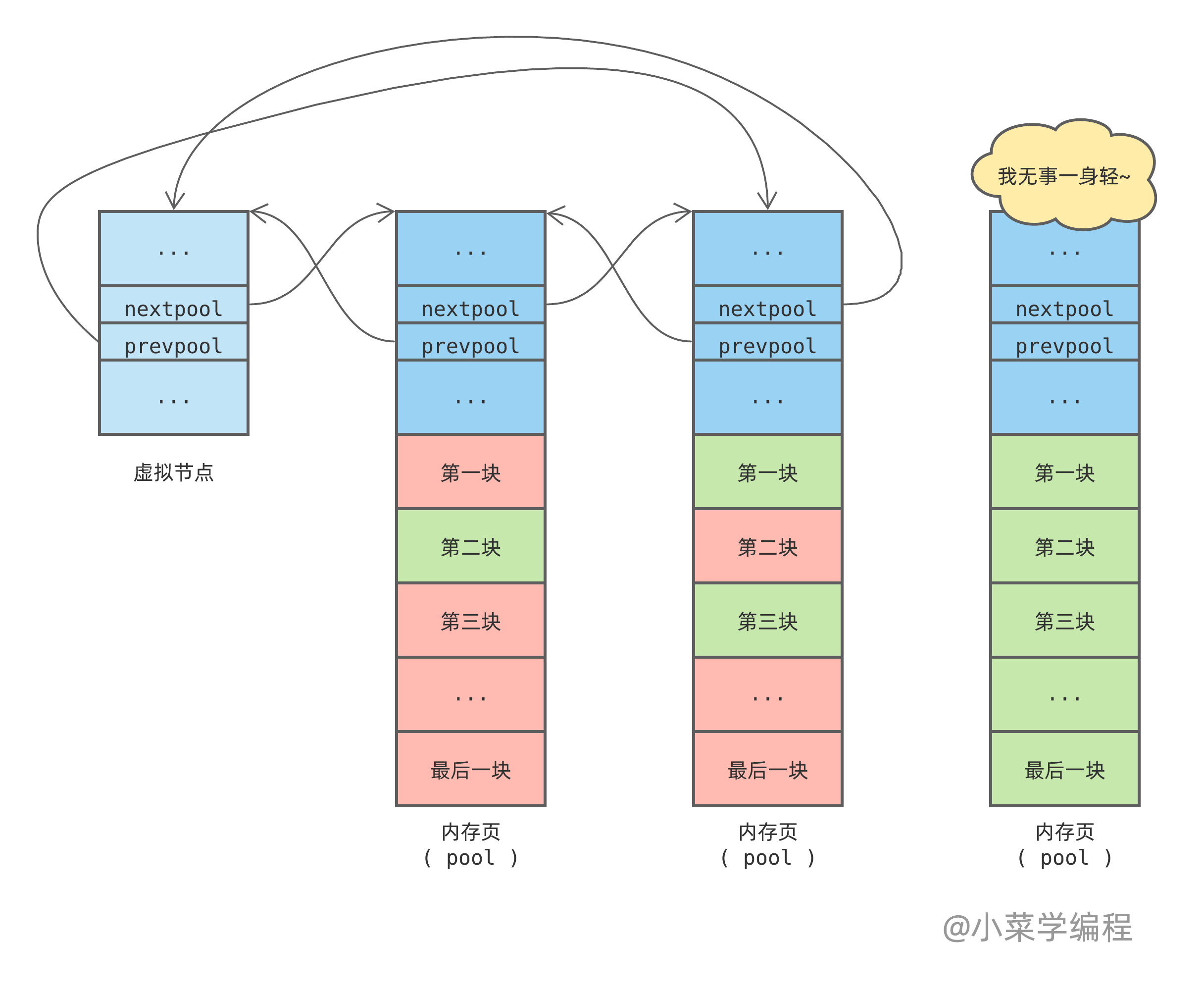
实际上,pool 链表任一节点均有机会完全空闲下来。这由概率决定,尾部节点概率最高,因此上图就这么画了。
pool 链表数组
Python 内存池管理内存块,按照尺寸分门别类进行。因此,每种规格都需要维护一个独立的可用 pool 链表。如果以 8 字节为梯度,内存块规格可分 64 种之多(见上表)。
那么,如何组织这么多 pool 链表呢?最直接的方法是分配一个长度为 64 的虚拟节点数组:
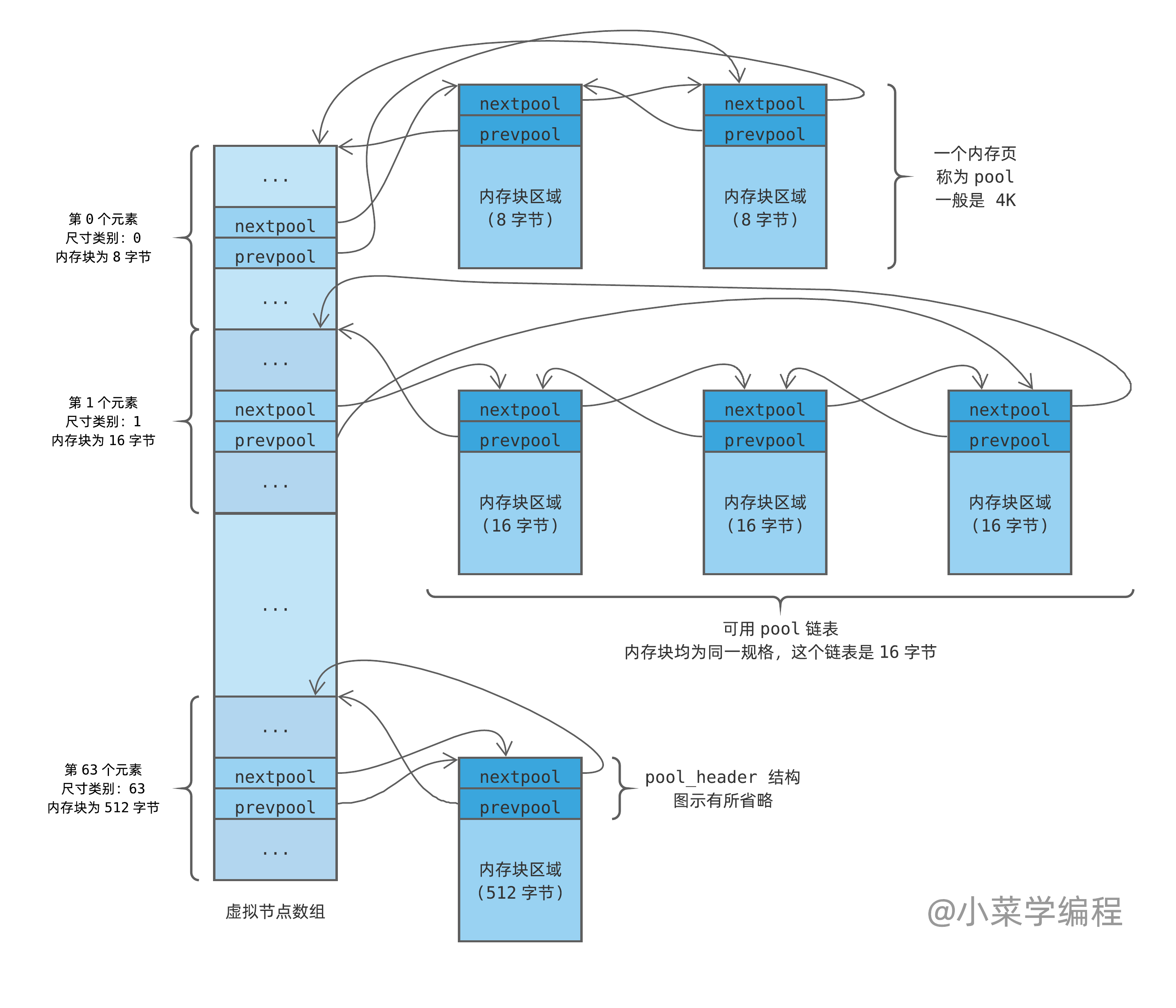
如果程序请求 5 字节,Python 将分配 8 字节内存块,通过数组第 0 个虚拟节点即可找到 8 字节 pool 链表;如果程序请求 56 字节,Python 将分配 64 字节内存块,则需要从数组第 7 个虚拟节点出发;其他以此类推。
那么,虚拟节点数组需要占用多少内存呢?这不难计算:
$$48 \times 64 = 3072 = 3K$$
哟,看上去还不少!Python 作者们可没这么大方,他们还从中抠出三分之二,具体是如何做到的呢?
您可能已经注意到了,虚拟节点只参与维护链表结构,并不管理内存页。因此,虚拟节点其实只使用 pool_header 结构体中参与链表维护的 nextpool 和 prevpool 这两个指针字段:

为避免浅蓝色部分内存浪费,Python 作者们将虚拟节点想象成一个个卡片,将深蓝色部分首尾相接,最终转换成一个纯指针数组。数组在 Objects/obmalloc.c 中定义,即 usedpools 。每个虚拟节点对应数组里面的两个指针:
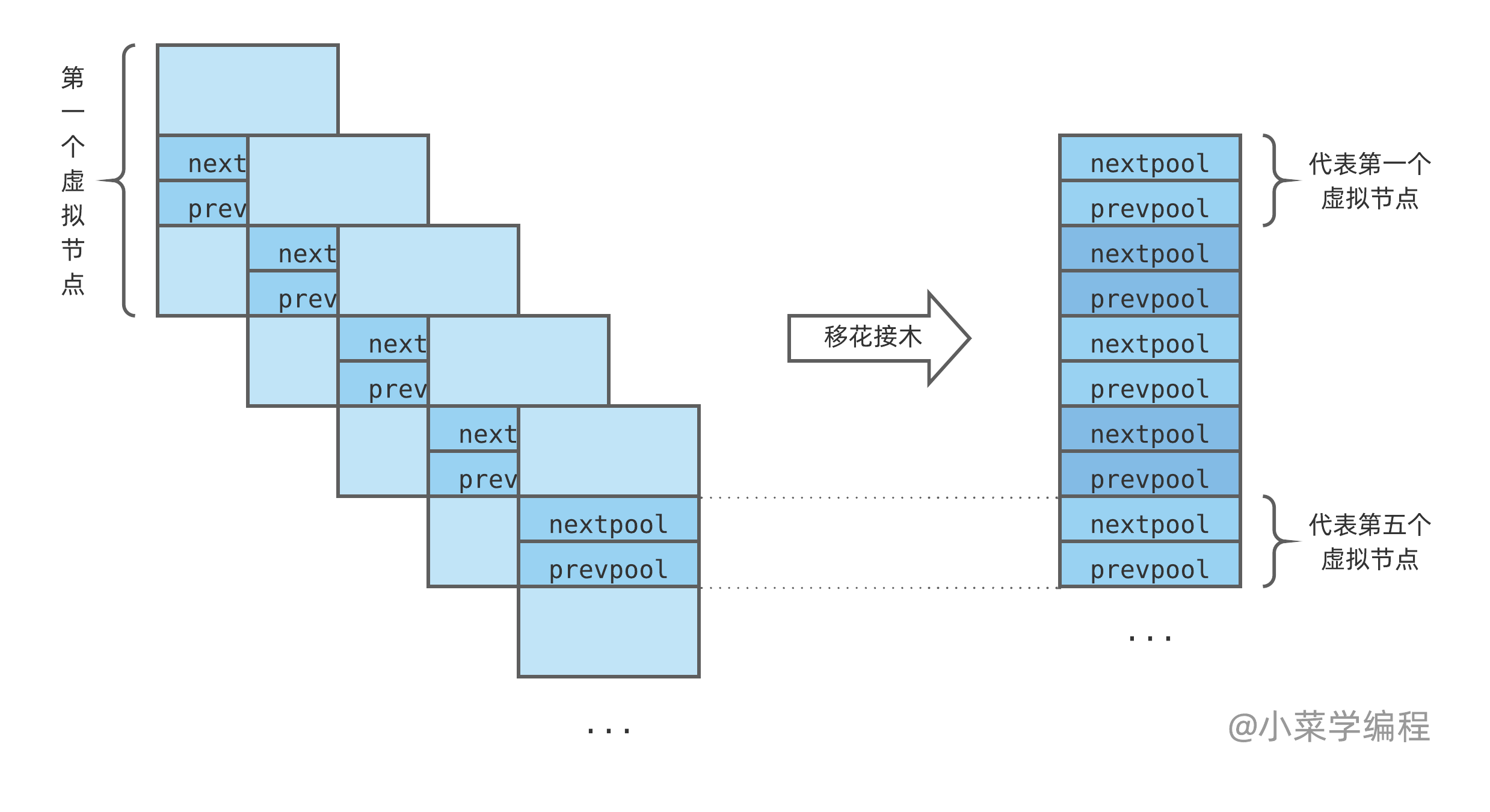
接下来的一切交给想象力——将两个指针前后的内存空间想象成自己的,这样就得到一个虚无缥缈的却非常完整的 pool_header 结构体(如下图左边虚线部分),我们甚至可以使用这个 pool_header 结构体的地址!由于我们不会访问除了 nextpool 和 prevpool 指针以外的字段,因此虽有内存越界,却也无伤大雅。
下图以一个代表空链表的虚拟节点为例,nextpool 和 prevpool 指针均指向 pool_header 自己。虽然实际上 nextpool 和 prevpool 都指向了数组中的其他虚拟节点,但逻辑上可以想象成指向当前的 pool_header 结构体:
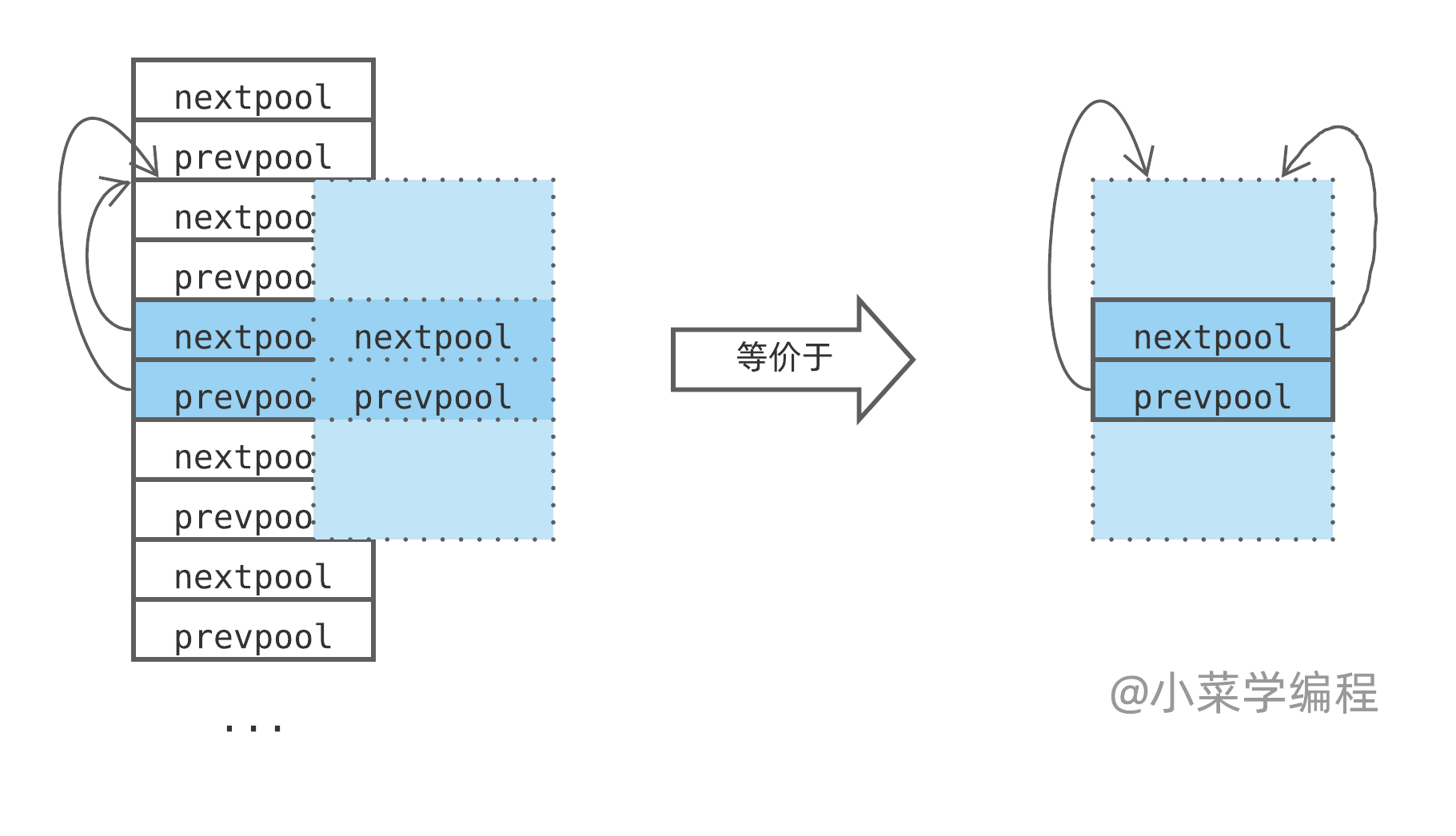
卧槽,这移花接木大法也太牛逼了吧!非常享受研究源码的过程,当年研究 Linux 内核数据结构中的链表实现时,也是大开眼界!
经过这般优化,数组只需 16*64 = 1024 字节的内存空间即可,折合 1K ,节省了三分之二。为了节约这 2K 内存,代码变得难以理解。我第一次阅读源码时,在纸上花了半天才完全弄懂这个思路。
效率与代码可读性经常是一对矛盾,如何选择见仁见智。不过,如果是日常项目,我多半不会为了 2K 内存而引入复杂性。Python 作为基础工具,能省则省。当然这个思路也有可能是在内存短缺的年代引入的,然后就这么一直用着。
不管怎样,我还是决定将它写出来。如果你有兴趣研究 Objects/obmalloc.c 中的源码,就不用像我一样费劲,瞎耽误功夫。
因篇幅关系,源码无法一一列举。对源码感兴趣的同学,请自己动手,丰衣足食。结合图示阅读,应该可以做到事半功倍。什么,不知道从何入手?——那就紧紧抓住这两个函数吧,一个负责分配,一个负责释放:
- pymalloc_alloc
- pymalloc_free
虽然本节研究了很多东西,但还无法涵盖 Python 内存池的全部秘密,pool 的管理同样因篇幅关系无法展开。后续有机会我会接着写,感兴趣的童鞋请关注我。等不及?——源码欢迎您!
如果觉得我写得还行,记得点赞关注哟~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号
