
[ML] 通过llama.cpp与羊驼聊天的网页界面- 详解 Serge 的启动使用

Serge 虽然能够让我们在笔记本上跑起来 7B模型, 但实际运行非常消耗CPU,对话生成响应非常非常慢。
1. 官方指导是使用如下命令直接运行:
$ docker run -d -v weights:/usr/src/app/weights -v datadb:/data/db/ -p 8008:8008 ghcr.io/nsarrazin/serge:latest
随后打开地址 localhost:8008
注意:这里面有个文档上面没说的事,就是你本地是没有模型时,镜像内部会进行下载。
7B模型大小 4G,下载这会持续一段时间,所以打开 localhost:8008 后 Model choice 是没有模型可以选择的,按钮也是不可以点击的。
你进入到 docker 容器中可以查看 ./weights 目录里的文件下载进度情况。
2. 等下载完之后就会选中模型,此时 “Start a new chat” 按钮才是可以点击的,而不是 disabled 状态。
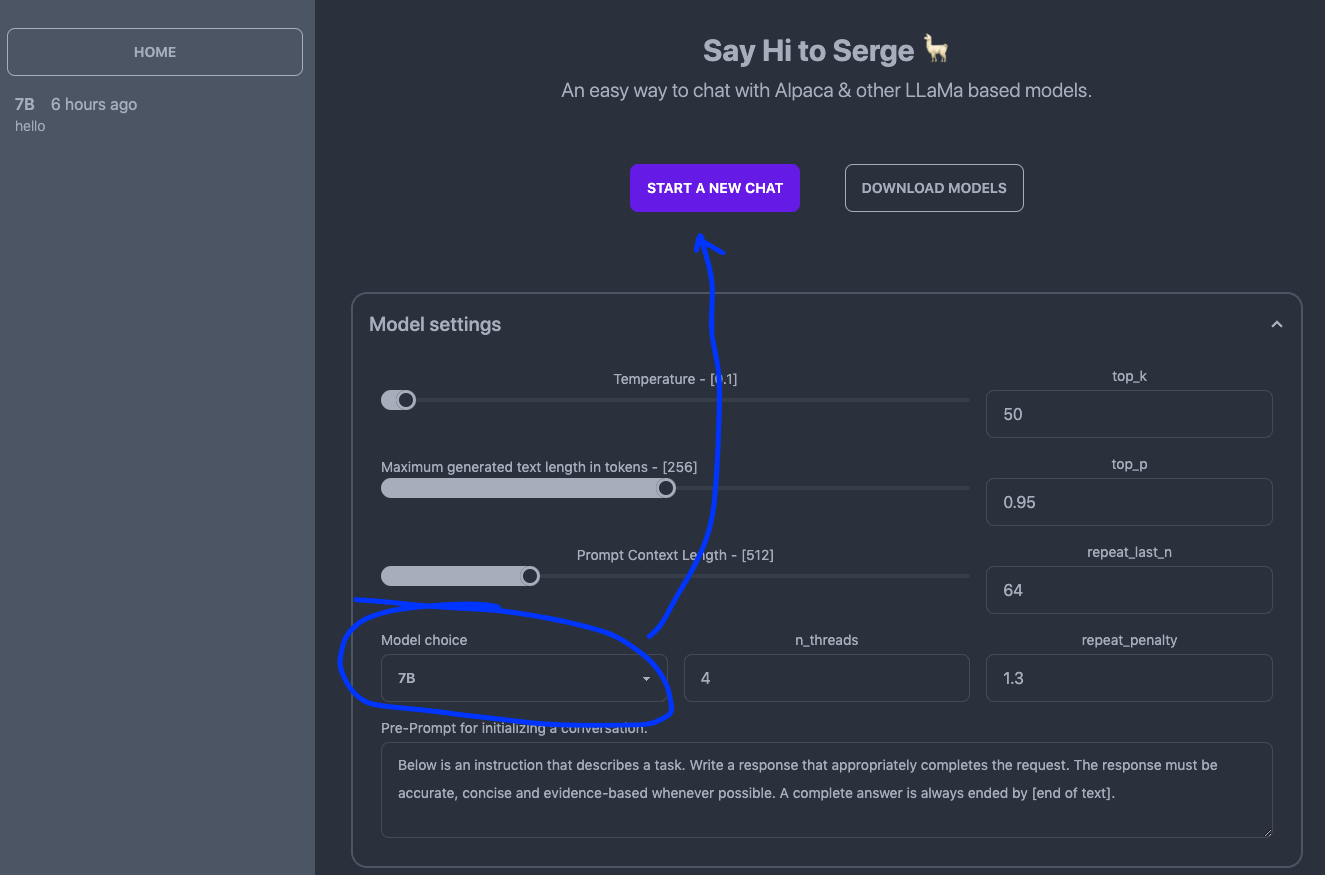
3. 如果提前在 Huggingface 上面下载好的文件,放到 weights 里面要改名为 7B.bin
https://huggingface.co/nsarrazin/alpaca/tree/main/alpaca-7B-ggml
因为可以看到实际生成用的是 docker 镜像内的指定目录内的 bin 文件,比如: 7B.bin
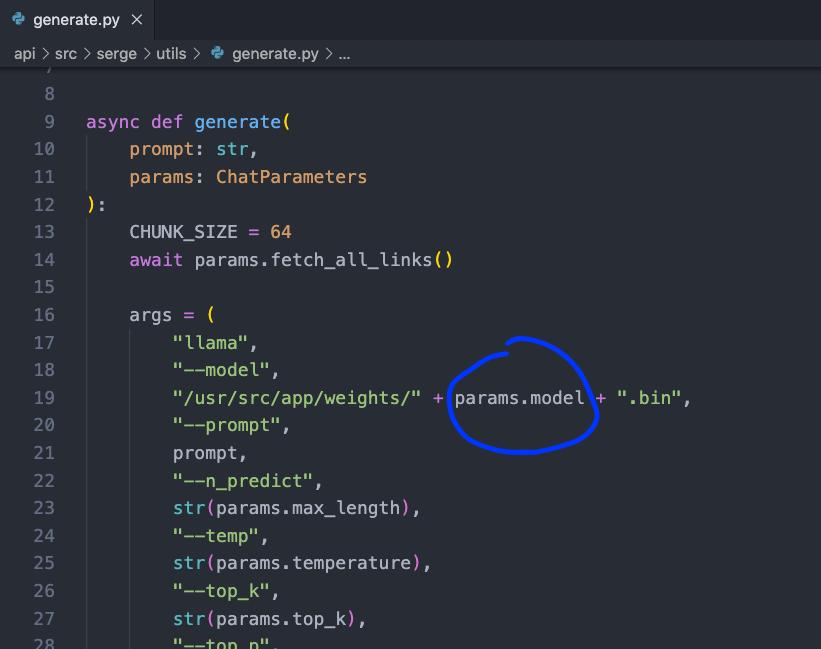
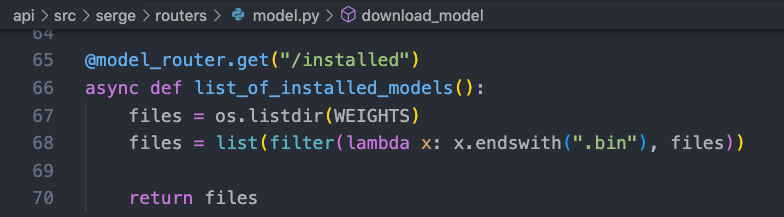
检验有没有下载好的模型文件,也是通过检测目录下的 7B.bin 等文件。
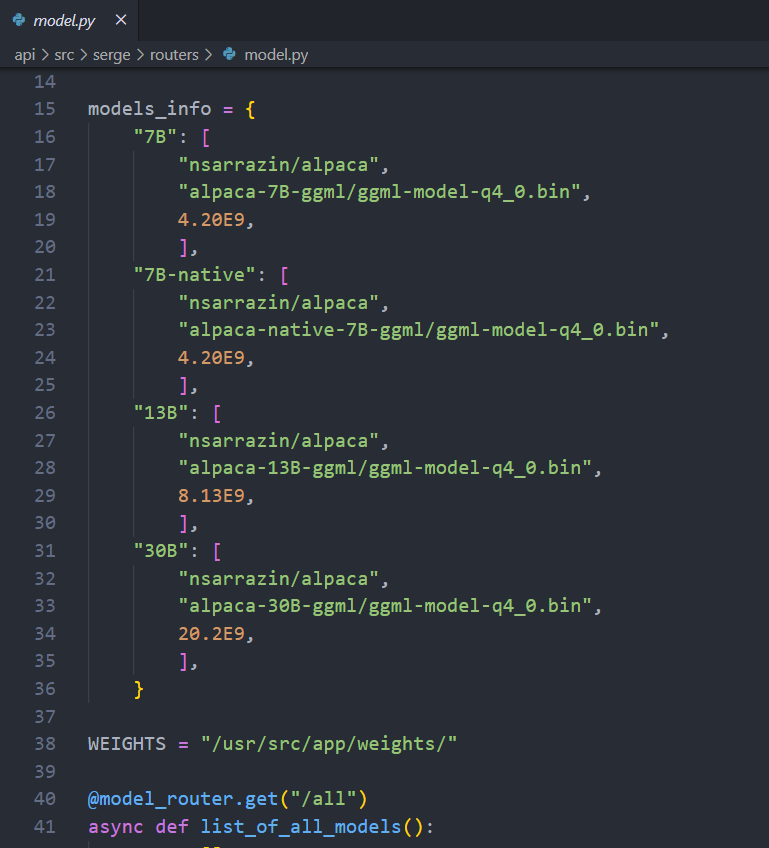
补充说明:具体程序是去哪里下载的可以看到列的模型信息,单独使用时可以自己去 HuggingFace.co 搜索下载。
Tool:ChatAI Online

 浙公网安备 33010602011771号
浙公网安备 33010602011771号