汉字编码新尝试:字理组字编码方案v0.0

↑对,这就是正片↑(同步自敝知乎专栏,不定期更新)(可能有点小,可以按Ctrl + "+"放大整个网页)
高清(确信)版:http://farter.cn/zzdm/latest.png
不用任何教程,试试对着表解码一下:
43 295 817 146 140 113 773 723 04 331 129 217 105 883 401 185 821 14 321 471 0268 742 495 04 903 02 75 0302 674
(分区内,先行后列,02是“亻*”,20是“女*”,0-02是“虫*”,00-02是“亼/”)
尚未定稿,表与细则仍在调整,暂勿直接用于存储。
~从甲骨文出发的汉字编码~
综述
众所周知,汉字中的大多数是由偏旁部首(统称为部件)组合出来的。
字理组字,就是按照汉字字理,组合构造出来的字,可以用表里的部件组出任何“讲道理”的字。
“这字是啥加啥,咋拼的,怎么表示的这个意思,我们古老的象形文字画的究竟是啥,以前是怎么写的,中间流传传抄演变的过程会不会写错了?”
字有字理,但字也会变化。有分,有合,也总有些字变得不是很讲理,看不出它是啥加啥。
本表把每个部件从甲骨文金文(若有)的源流到楷体印刷正体在中日朝韩越新马各国家地区的演化发展全流程纳入考虑,每个部件对应着尽量源头的写法,有理有据有根。(用的时候,你也需要考虑)
本编码期望为古籍规范数字化填坑加速,为人名地名生僻字文化保留铺平道路,为汉字发展释放造字活力扫除障碍。
本表酌情把常用而又变妈不认或者学术上仍不确定(统称有坑)的整体安排进码位,视作单体,不是一个“完全拆分到头”的字根树部件树。
本编码理论上可以用作输入法(比五笔郑码等26键形码是要硬核得多,但比电报码区位码JIS码Unicode还是更友好的,并且它由字理实现统一)。
本表也可以用作业余无线电电报码,一两张纸精炼信息搞定,而不需要整一本电码本字符集来翻。
本编码期望做字体、做输入法(尤其大字集、多地区)的开发者使用作为内码,不需要等Unicode收了你才有地方放生僻字。
本编码可以用于按规则生成相当大一部分结合时“没有不规则变化”的字的形码码表,还可以省去跟现行码表里的讹字对字形搞特殊区分码的绝大部分功夫。(重码高了不讨好,但无意义的同理异码在本编码里就不该存在)
本表实际上也是一个部件统合表、简繁类推表,力求达到异体写法(在多个层次上)分分合合的一个合理自洽的状态。
本编码甚至可能用作手写识别、机器学习古文字识别的直接目标编码,也可以作为智能动态组字的源编码。你感受到了么?
但总的来说,要把本表全部掌握牢固,可能还是算半个学汉语言文字砖业的big学生了(?)
但是通读一遍,也能入个门了吧(??)
此处真情实感建议,放大全图,逐区逐字浏览一遍,再回来继续看说明。
如果遇到一个生僻字,组得出来(表里找到,拼就完事了,但是注意字理,里面有“!”就是有坑要小心),成了,你就用规范的组字码串表示这个字。
只需要有做字人在字型(字体文件)里以这个码串为题,添加一个对应矢量图或像素字,你用这个字型(如果有生之年我做出了这套渲染系统的文本框),输入这个码串,便可显示。
到别的地方如果用的字体文件里没有这个码串,那确实暂时不能显示,但至少可以回退显示一串部件,表示这个字是由哪些部件组成的。
如果未来智能动态组字普及了,那就不成问题了,只是显示可能暂时丑点,随着技术进步终将修好。
常见类推简化部件简繁同码,若以本编码作简体字型,自然应该是统一简体部件。(细节后述)
这样,姓名地名“常见生僻字”、方言字、民间合字、道教讳秘字、天地会秘文、减字谱、合音字、网友新造字、喃字壮字、日月干戈心zuibiang……绝大部分,都不需等待任何批准收录,就可有理有据地编码表示。(遵守一些细节规则,下述)
比如最近最火的“鸟/甲”,代码就是“024 10 150”,简繁同码(或者就是简体)。
如果组不出来,八成是你这字有问题。如果你认为是另外两成,欢迎留言讨论【比如实在异形的方言字地名字
能编码出多少字呢?理论上那就是无限的,用已收录部件讲字理的前提下完全自由,你可以用你认为对的字根与部件按规则粘成一个码串,就固定代表那个字了。
只是这个码串可能不符合“最短最简洁”常规需要纠正,可能合规但由于没被字型收录等原因,显示不出拼好的样子而已,毕竟目前动态组字还没那么成熟。做好这个平台,推动技术成熟吧。
但是,即使码串是合法的,合不合字理另说。可以就从你在画甲骨文的角度去想象。你当然可以画一对月亮,但朋友的“朋”实际上是大鹏尾巴的一大把羽毛;你还可以画一根禾苗,两边有两个人背对着(北),但“乘椉”实际上是一个大脚人站在一棵大树顶上……
这些就是字理了,是学科专业知识,可以去网上查古文字写法,可以去书里学,慢慢积累。
类似的“有坑”部件,本表多是收为单体,直接就用的,不需要去组。需要拼的生僻字古字如果有坑,就需要专业选手来辨认鉴别了。当然,做好字表词表对接上各种现有输入法后,一般用户就不需要拼字这一步。除非,遇到了输入法字表里没收的生 僻 字,或者你想造字了。
坑本身确实对应着字理,理解记忆这些坑,就对应着真正古文字演变的知识了。
相对的,五笔郑码等实用输入法形码,其中也总会有很多例外边角特殊规则,但它们是为输入法的实用性与性能参数(重码率)而人为规定的。
完全掌握本编码方案,确实也意味着要掌握这些“例外、讹变”,但它们是有古籍古文字来源依据的,可以说是“要背也是背了真的、有意义的东西”。
基本框架
本编码只编码汉字(包括壮字喃字等基于汉字部件的),标点符号目前都还没有【可以用独立的(空)代替着先
本编码的码位是数字串不是数字,00 000 0000,98 098 0098分别都是不同的码位,变长是因为适应汉字部件本身的频率分布。
每个码位分别有是否粘左、是否粘右的属性,这里的左右粘指码串位置的退和进(粘退粘进粘前粘后,太怪了……)。码串内相邻两码位之间若左不粘右、右不粘左,则是两字的分界。
“+”为包围杂合(即,任何复杂例外结合),“*”左右,“/”上下,“^”为优先级最高的修饰符,类似数学的符号便于理解优先级。
01<⿰> 10<⿱> 11<⿴⿻> 为“结合符”(等于是“*、/、+”二元中缀运算符)左右都粘,优先级与对应的粘法(“自带结合符”)一样。两边不粘需要焊接,或者明确改组合方式时才用它,多数时候不需要用。
(组字举例可能是强拆的,只为示意,如果码表里已经收录为单体,则实际编码应该直接用单体)
包围(以及杂合)关系相对严格要求,只有在“如果强行不包就空一大块丑得报警”的情况才算包。其余情况多如只有一笔伸过去的,都算左右或上下。(只在需要插结合符的情况考虑。表内预置粘右还是按照常识,如“走”标为包围结合)。例如“麻磨 䧹鹰 辰唇 石席 鹿麋”等等普遍适用本条,算上下。不然“鼠 麦”不同地区全分成两种炸了。
具体长笔画伸不伸过去随字型实现。此处插播一个“屎女屡”,就根本不是按字理拆分的。本是“尸娄”(84 536)。但如果你真想用甲骨文画一个有人在女上拉屎【那编码还是上下(0296 070)
“辶 廴 凵”还是都算包围,但是本编码选择强调规律性,牺牲今文字笔顺,编码上还是包围部在先,粘右。顺便“廴”有大坑,“凵”还真是坑,“辶”还在“徒從”等字里。
“宀 皿”算上下,虽然古时候是包围,这里还是向今文字妥协了,“齐”也统一算上下(?)。
“颖 颣 嗀 啟”形的“包围”算上下,这是最需要注意的;“戈口→戓 𢦏口→哉”拿不出去的算包围(“戈止→武”才是上下,“则戈→贼”算左右)。
“疆聽”这种太怪了还在纠结,目前算左右……“乙凵”如“氹凼”也尚在纠结,目前算包围。
变体选择修饰符(VS,变选符),000 001 010 011四个,用于选部件的变体异体,这里的变体更关注实际多了少了零件的情况,也可能有性质变化,但倾向于无视太细节的笔形变化(交给字体字型去选择)。
无变选符视作“默认智能自动选”,具体选择哪个变体依然由字体字型决定。
期望是简繁日韩越各自《基本/常用/规范》字集(里面讲道理的部分)不需要用到变体选择。
变选符可以堆叠视作四进制串扩展选择。(?)
变选符可以加在运算符上表降低优先级。(??)
部件内变体具体列举与顺序,目前尚 未 定 义。目前码位的安排只供参考,先把码位定好再看这下一步吧。
变选符是绝大多数时候(常人写常文)不用的。仅在强行研究变体、高还原古籍时使用,需要搭配特制支持变体选择的字型。
期望是无脑去掉字符串里的变选符后,仍能表示一段同意义的文字,“不添错”。
异写分化字另论,如“气乞 巳已 牙互与”,确已分化的大概率另开码位在01xx区,可能罕用版需要拼字而常见分化字有码位(如“奈柰 粤雩”)。
略微特殊(摆烂)地,传统娱乐项目超级合字就用如“招+财+进+宝”(中间都用“11杂合”)表示,中间有些可能需要拼,可能有些细节问题。减字谱也用类似方法实现,后面详述。
没有组合字的整字变体选择,目前设计如此。这个口子一开没完。
唯一一个此用处的是“#疑”,粘左,只用于一字最后,表示按形记录而不确定字理。也许你也可以对这个码使用变选符罢(摇头
右“#”表示纯粹代表今文字字面形状,可能用于五笔郑码等形码输入法等的非字理字根表示。目前状态是极不确定的。
像 zi.tools 字統网 这里面“同声旁”带字理尚不明确部件的,录入时遇到更离谱的不认识的,就可以用后接“#疑”。可以用这个标记表示需要持续关注与校对。
半拉括号“(”左边为本码位能够直接代表的字形举例,第一个通常为单字典型。右边为需要改动(添加部件)才能组出的字例。字例同样可能是强拆示意,也要检查是否已被收录为单体。
(双)括号右边有时只是一种提示,如果右边是空的大概率是有对应未隶定的甲金初文。
字形举例有多个时,代表的是本部件“自 动 选 择 合 适 的”(实际上还可能有例字之外的)。后面详述。
由于制表便利,表中文字都以unicode今文字国标宋体为参考了,也许以后会画点甲骨文上去。
有时只有两个组出的字例,那就是这个部件Unicode没收或者在太新的区一般设备都显示不出来,看共性就知道了,你懂的。
如果不懂可以去查汉典国学大师字统网【但也不可全信哦【【【
目前带“?”的有多种情况,可能是字理还存疑,可能是摇摆要不要收录占一位还是适合手动拼(易拆、无疑,但较为常用,又需要结合符焊接)。换句话说,没带“?”的部件,默认有坑(“基本上不是你看起来那样组成的”),带了的,可能是没坑,可能是巨 大 坑……
尽量短
组字,应该用尽量短的表示、尽量用字理上对的粘法、尽量用已有的粘左右。
有一些单字没有不粘形式,后缀了“~”符号提示。让它粘上一个00(空)表示单字,粘上别的就是合字,如“艹(00)→艸,禾(00)→禾”。
有些字只有粘左版(如“斤 攵 力 瓦”),想表示单体就只能先(空)再粘左。两者都有时,表示单字优先用粘右和(空)。
注意同字可能有粘左版,可能有粘右版。当作为字的右、下、内部时,若有粘左版就必用,除非需要结合符改结合方式,让码长变长,而又有不粘的单体可用,比如“女”在右时,不用只能在下的“/女”。
粘左版普遍可在下可在右,若能通过其左旁自带的组法决定就决定(甚至可以是被左旁“包围杂合”成“在内”,在组合方法意义上,包围杂合最优先)。
很多部件自带粘左粘右的方式是两可,且都有组法优先顺序(*/表示优先左右,对面不同意再上下)。若难以决定(X对Y、XY对YX)或者能确定但不对,则插入结合符可作强制修改,如“翦”等。(有时候也不需要完全死板,默认给字体自由选择的空间,如“男 界畍 略畧 勇”等目前计划为默认不需严格指定)
剩下少数情况,如两码互相都不粘,就只能用相应结合符焊起来了。
粘右版设计时倾向确定粘法,利于熟记后直接写字抄收的潜力。但仍有可能被强行修改,还需脑内缓冲。
本编码用作输入法时,实际上没什么处理,就类似区位码。需要实现的就是一些纠错、常见错拆(其实就是看起来像什么但实际不是什么,因为字形讹变了;或者表里有合体而输入者去拼了,即使拼对了)的提醒修正。
绝大多数情况,部件只看位置不分声意符,但“/*寸又彐”“/*口曰甘”是特殊,只在不作声符时才用。
做字体字型相关
用本编码做字型,需要预设好是做的简体,或某标繁体,或甲金文,或篆书,或某时期某地隶书等等,确定默认用来显示不带变体选择的普通文本时采用什么字形为第一要务。简体的话,部件应该参照表内允许形态酌情尽量类推。
不期望同一字型同时显示简繁(虽然理论能做),但类似TTC,可以有共享矢量图的多字形字体包。
期望,甲金文变体和今文字变体能对应上的,就安排在同一变选符里。甲金文字型中后起字形没有对应甲金文的部件,可以编一个【或者摆烂用今文
简繁统一
本表将绝大多数类推简化偏旁部首都合一了,并且酌情收录一些规范上不可类推的,使其繁体版“能表示”简体部件。这部分仍待考虑调整。
但这远没有达到直接等于进行简繁转换的地步。非一一对应的特殊字,仍需要复杂对应关系的精确简繁转换特制规则,分词甚至看词性等。这是另外的事,已有许多努力(如OpenCC等软件)但难臻完美,本编码改变不了这一现状。同往常一样,要结合上下文特别判断处理。
只是最大部分的类推替换工作,在本编码下消失了。但如果不加最后这复杂的处理,只切换字体,是一种“能看、不出错(不添错)”的转换。
关于各地各国的简化字,为方便使用,02xx收录了一些难以分类的单字,仍需逐个考虑调整。
这里有很多特别细节,如这里的“发髮”就只代表髮,用于头发,“发發”在前面别的区,用于组“拨泼”等字。在简体字字型中,可能显示为一样,但是编码上不一样,在别的地区字型中也显示不一样。
总体思想是,依据字形行书简化草书楷化的而又有一定类推例子的统合,另选声符简化的区分(此处有纠结,类推较多的,可能归于繁体部件,允许简体字型逐字选择显示换声符简化),单体代表增部件版分化字但实际两者区别不可忽视的分,局部记号字未被收录单字的,就用今文字笔形符号(05xx区后带#的)。表内搜不到的,就说明完全分开了,自己拼。
异码同形现象
这一点,我觉得需要接受,不然永远脱离不了按“整体今文字形”编码,“宁”永远同时是㝉的繁体和寧的简体,另外如国标的“月、肉”碰上再分,收录顺序不同的时候也就尴尬了。
如果发电报,人给人抄收译码,那字理上有点错也没问题,都会简体字都能懂。但输入计算机的最好是统一的。
以此码渲染文本的系统,理想地,应该在渲染时醒目(不要太醒【)标记不常用字、可能错误、可能异常编码(但可能是汉字研究文章一个刻意体现不同字形的编码,可能是带变体选择)、可能最后带着“#疑”(说人话就是8105∩6763之外全标黄),最好是统一提供鼠标移上去后显示“字理组字码串显示和解释”工具提示。(这个深入UI框架去了,算是做梦,但在web上还真不是大问题了?)
细则
组合细则
(此处举例均略去了具体组合方式)
部件顺序,比较显然的是,包围杂合的大的先,上下左右先上和左,特别难决定时,按第一笔所在部件先。
部件一旦稍多,结构树不是严格能够确定的,但多数时候(加上一点点书法考量)可以确定。
这种组合不确定性本就经常发生(如“荆荊 㽔蕤 邃莲 黙勲 憩簸㓹”……)。初学拆字时也要多往这方面想,被扭歪的多数是声符。
本编码认为这种差异(即本字理码规范编码相同)不可能认为两个字(“字位”),如有反例请不吝赐教。
包围的结合优先级最低,但:
当包围部件有左旁或上旁时,如“俯蔗槌笝”等,结合优先级的理解上可以不严格,不必在这种情况认为违反字理,强行调优先级。
当包围的右侧或下侧是开放的时,如“郾劂励”,那方向上又有左右上下结合,同样不必(甚至多数时候就有此类变形如“取最㓹罽”)。需要强分的情况,也就是那方向也封闭,“慁恩爴剛鹇”等极少数情况。
但是上下和左右都是分的。如“鵝鵞䳘䳗、㲻氽汄氼”四个码串都不同。(然而也有少数如“融稣略”有坑,想避免混乱,如果收录为单码位,就顺便把不同结构统了)
有一些特别组合方式导致合体字书写顺序被拆开,但如果那个合体字明显自成字理层级而不是散开的,此时部件的顺序,按字理层级,而不是笔顺。假设把“顷禾→颖”中的顷强拆开,就也应按“匕页禾”而不是“匕禾页”;“须此→頿、(嗀)禾→穀”等同理。(其实阴谋过“阝土”“酉皿”等合体作为包围部件,但忍住了,所以还是按书写顺序了)(这里也欢迎边缘例子,我觉得会有)
多少零件的变体
某个部件兼容少了零件多了零件的情况时,如果单字(在当前字型的目标字形风格中)默认是少零件的,手动加零件表示一定要用多零件版(这里其实有点纠结)。相反情况如果默认是多零件版而想用少零件的,用变选符指定。
单字和被用于组字的时候,默认选择不一定是一样的,如“睿叡”在繁体环境,单字选“叡”,“氵”黏上它还是可以实现为“濬”,毕竟繁体常常也有从X省的。
总的来说,也是理解为“智能自动选择合适的那种”,除非加了变选符表示意图。
默认选多零件版但又被加一次的情况,字型实现不加两次,只理解为“要用加了的”,明显不该重复加的就不加。一个怪点的例子,U+31F63 应该编码“艹华”,简体可以显示成“艹华”,繁体还是显示“華”。
虽然但是,就算除开“鑫森淼焱垚”这样的叠字,我们确实还是已经有很多类似“曝呵圆樑溢燃墅擧捧暮”的重复偏旁(曾被评为“叠床架屋”)的字,这些贴的方向不一样不同质,所以码串里表达出来了还是要照样加的。
如果多零件的出现在括号右边提示中,那说明这个码位只能代表少零件版,是必须要手动加上对应零件才代表多零件的字。
类推简化字的边缘
若按本表定义制作简体字型,则常见部件都应该(按本表定义)类推,自然都应该是“一致的简体”;若做日本新字体,也进行类似类推;港澳台韩标旧旧旧隶篆金甲骨文字型,都是可以实现的,只是一些后起字形可能需要造一个甲骨文【
一些在类推与否边缘的部件,可能是分码的(也就是不类推),可能是一个部件码位定义上两者都允许(也就是同码,“可选类推”),可以在不同目标地区的字型中逐字作不同选择。此时多半那个简体版也单独有码,两者配上部分偏旁,简体环境看上去就完全一样。相当于“用繁体的码”。如“兒”简体显示儿、繁体显示兒,“亻兒”简繁都显示倪。码位形如“兒!儿”表示,需要注意。(换声符、记号字情况都有,情况较复杂,多数时候简体版另有码位,如“菐!卜 劦!办 阑!兰 堇 𦰩 爯!尔 奥!夭 聽!听……”实际上如果按前面说的大原则,可能最终有很多会被删(也就是简繁分码),但一些不类推有群众基础,有一点纠结)这个边缘也是整理调整重点,一些部件的处理可能不完全符合相关国家标准。讨论字形时可以用变选符指定一种,前提是字型要支持加了变选的。
叠字修饰符
要表示叠字,用后接101(吅)110(吕)111(品)这几个“叠字修饰符”,它们都可表示简体以“双”、两点、四点代替重复部件的情况。重复三次如“三川”形的,用两次(吅)或(吕)。横纵先后不明的“㗊”形或更多不定形重复,用两次(品)(已在80x的三叠字,只用一次,如各种四田“雷壨”用畾+(品))。
200(旋转翻转),以及周围的几个,极少使用,暂定:单用为“智能选择最常见的一种翻法”,200 001横翻,200 002纵翻,200 003旋转180°,200 000“最常见旋法”,200 000 001顺90°,200 000 002逆90°。
为了程序处理(判断字与字的边界)简洁,表内标记了粘右的部件加上变选符或者各种叠字符后,都失去向右粘的属性。若要接一个不粘左的部件,中间需要再插对应的结合符。
汉堡包形,左右或上下部件相同或对称(字理上)时,一律认作包围,从头拼的话用“[半边][叠字符][包围][中间]”。“^^(北)”叠字符表示两者相反(相向/相背?),用于“修饰”叠字修饰符(就是跟在它后面),此处细则待定。
从X省
其实有很多,少零件版,从X省,但省前的X没有收录为码位的情况。这里的坑在于,有些复杂部件省后也还是一个完整的字。这里规定,如果这个被省的整体“省后成字”,且字理对得上是“完整的一部分”,则用省后的字(也可能得拼)作此部件,这里其实对应很多声符错配丢失现象,如“玉册→珊(删),劦肉→脋(协)、木㐬→梳(疏)、酉禾→酥(稣)”;否则要完整使用未省的字,如“革匊言(鞠言)→鞫;差鱼→鲝”(单纯羊在上留出一撇的极少)。
回到变选符
如果含变选符的码串在字型中未收录,则试着去掉串内所有(部分?)变选符再查找字库并渲染。如果此时成功,可以渲染但也作视觉提示区别。再失败,就渲染为部件序列好了。
实际上对于组出来的字整体,依然适用“智能决定”,不排除做上一些微小缩合处理(也对应着“杂合”)而不需要变选符,甚至会有一些特殊约定,讲理就行。
必须有的例子也不少,如“土弓畺→疆;彖矢→彘;亻侯→候;凡鸟→鳳(!);卧品→临臨;贤忠→贒”(能分析为上下/左右就尽量,若不明确的组合方式、严重变形丢部件融合时,再用包围杂合;边缘情况欢迎讨论)。本编码无意编码所有精确变化,若你想表现,那你用unicode private variation selector area去呀【【【【本编码拟允许部件接连续三个及以上的变选作为私用定义变体?
分与合
汉字部件的分分合合,从细微笔形差异到各种演化简化,在形式上几乎是连续的(数分爷别杠球球嘞),立出一个标准就是要在中间砍一刀分两半,可以说砍哪里都有问题。
本方案仍将继续改进,尽量做到足够合理再定稿。
048x两怪字的词,为了占用码位少,暂用一码表示两个字,变选符选单字,方案仍在纠结,是否要一个“有意义的不应删除的选字符”。
每个分区、行、列的排列顺序有什么规律?
我当然是希望方便查找、方便记忆的,如果真的浏览了一遍,还是看得出一些“规律”吧。
但汉字就是这么博大精深,没有一个严谨的死规则全局好用。甚至就连分区的方式也是,一旦想贯彻一种,都总有刺头会出来让这个规则显得很蠢。
从古至今已有意符部首、声符韵部、四角号码、拼音注音序等多种尝试,依然是各有各的局限与不便,达不到理想的境界。况且本方案的目标还略微远大一点,想要包揽古今。所以如果从像数学一样严谨的意义上说,就是没有规律,只有熟悉整张表。
本表顺序甚至考虑了字频与摩尔斯电码(屁牌TIANSMURDH码欢迎食用)长度【目前顺序位置没有冻结,欢迎提出调序建议
实际最一致的方面的大概还是局部按偏旁共性、字频、组字能力排列。
一定有很多坑。
猜错不是你的错,尽管本编码已经努力隐藏很多坑,但汉字字理就是还有这么多的坑。
我同时致力收集这些坑作为附录,以及放进将来的直接组字码输入法,如果用户输入匹配上错的串,就提示改正就好了(同样,如果输入了收为单码字的合体字正确组合,也提示改为单码字;但这样的组合串是合法码流,可能用于表示“没有缩合变化的简单确定组合”,对一些分化的特殊情况还必须用,如“柰邪党杰”等),这也算最直球的字理普及、增量学习方式吧。标准数据整理好了,功能实现真不是什么难事。
减字谱暂定方案
有单体代表字尽量使用代表字(用连不用车,用进進不用隹佳,用次软不用欠,用食不用亻,用打不用丁,用起不用巳,用勾不用勹,用散不用艹,用急不用刍及,用外不用卜),无单体代表字时,可以比实际部件完整(“按掐挑撞摘”用“安臽兆童啇”,泛用乏,吟用今,落用各,劈用辟,等等),但不能比实际部件少(捻拼出念,荡用艹氵?改用昜?),可以比代表字少(抹用末不用木,徽用微不用山),特殊情况(省从俗?)还待确认,中间用+连接(全部?),最后“#减字谱”。
具体到数据的实现
其实已经有很多个阴谋(在4bit半字节流上的、8bit字节流上的、跟ascii共生的DCBS、寄生在utf8、utf16的、直接电码的、兼容摩尔斯电码的、26个英文字母的,自同步、子串查找无压力的,梦里都有【
简单起见,最通行、最易识的明码方式,还是数字串加空格吧。
一个类似utf8思想的,用字母数字作为码字编码(约等于36进制)方法:
2码开头用A-J,3码开头用K-T,4码0xxx开头用U-Z(感觉不会超过1+10+6个区,超了再分大小写【),分别后接1-2个数字。就自同步,子串不泄漏,不用分隔符。甚至可以用在网址上类似punycode,中文域名你怕不怕。
E3M95S17L46L40L13R73R23A4N31L29M17L05S83O01L85S21B4N21O71W68R42O95A4T03A2H5X02Q744bit码字编码方法,不出现码字0(约等于15进制):
[1-7][1-F]105个码位编2码“00~99”,[8-F][1-F][1-F]1800个码位3码4码塞进去即可。如果想避免大数除法让4bit处理器也能用的话,还可以第二码的低三位和第三码的四位合起来仿照2码,第一码低3位和第二码最高位合起来为分区号,1600个码位也刚好。仅前缀码,无其他优良性质。
3e976c238c28bb89ebdeba9159b28af923896c69a128ebc271f9a7a5ce59bbda7615c941361e93b5f7bit码字编码方(伪·DBCS),兼容ASCII:
[80-FF]有128个码位,拿100个表示2码,再拿16个表示3码4码的分区号(后接一个2码),完事,还有至少10个码元可以霍霍。变长1-2字节每码位,某种程度上自同步。
比较难展示,但规则算最简单的,省略了。
实践上,在嵌入式设备等性能捉急的地方,可以要求用至多N个码位拼,比如可能最低要求,8个码位(实际上设计理念就是关注最长码串,“非怪字”5码应该是最多了,当然减字谱以及合字就不止了)。但最好还是变长索引结构,可以用上面写的4bit编码法作16叉树,供参考。
常见问题
- 你谁啊?
- 一程序猿
- 什么万码奔腾?
- 但是有些码它跑得太慢了……
- 什么落后玩意?
- 谁挡路谁才是落后玩意……
- 为什么十进制不用16进制?
- 看上面16进制36进制128进制都有,乘除固定数的优化自己学去,都是8位ALU能搞定的事。
- 明码还是给人类读写的,人类习惯还是10进制的。现在不差那点算力,转就完了,手算都行。
- 为什么99是空的?
- 看下面电报码
- 你咋不去写甲骨文呢?
- 本表意在支持甲骨文用这个编码指定与制作字型,意在包含各种未隶定的甲骨文部件(一定程度地统合,加入变体选择)。甲骨文好玩。
- 中文编程?
- 兹磁啊【字符串库的设计还得复杂点
- 收费吗专利吗?
- 不收费不专利,任意合法使用后果自负,但本人保留0.0版著作权,公开后与网友合作修订属于集体创作。
- 用的啥软件?
- office2003excel好玩
- 整多久了?
- 距离新建文件夹大概一年了,但阴谋开始得更早
- 改到啥时候?
- 如你所见还有一些缺,还有很多问号,04xx 05xx区还待查缺补漏排序,啥时候稳定很难回答。
怎么用?
一个字,拼;四个字,查表拼字,见啥拼啥,虽然有坑,但是别怕【
你可以用它当上课传小纸条、写情书、写日记的密码【
你可以给你的网站做个防爬字体,把汉字换成用这个编码的连字【
你可以用[-/../.-/-./.../--/..-/.-./-../....](同莫尔斯电码的TIANSMURDH)分别代表0123456789然后用来发CW电报。不用最短的E避免节奏太不稳,留出了99[.... ....]作为纠错,表明编码方式的prosign拍个脑袋就是<ZZ>或者<ZZDM>(组字电码)?其他多数prosign甚至可以换成就用中文字词,数字都用长码也就不打架了,如果大量数字还可以全单码【然后参考wabun code,<SN>表示返回标准摩尔斯电码吧
如果按国际英文莫尔斯电码来解释,就是:SN AHM DIR ISU IST IIN RRN RAN TS NNI IAH AIR ITM DDN STI IDM DAI IS NAI SRI TAUD RSA SHM TS HTN TA RM TNTA URS
美签要填电报码,我们的身份证银行系统也记录一个字理码,这样一来保证姓名生僻字有理,二来就算字体没支持,不管谁收不收,至少信息系统判个等没问题。
其实,一般用户不需要操心,本编码主要是替换内码,上面完全可以接已有的输入法,拼音五笔注音仓颉该咋打咋打,只是从输出Unicode(或者GB码)变成输出本编码。具体用哪个码串,都是输入法的字表词表内部机制要操心的,就像一般人不需要操心Unicode的4E00是“一”一样。
除非,是字表词表没收的生僻字,这时你可以手动拼字,无人能挡。本编码就是没有“字符集”这个概念的,只有部件表,真没见过的部件再叫我加进去。
尚未定稿,表与细则仍在调整,可以先玩着,暂勿直接用于存储。
个人观点,仅供参考
最终还是要讲理的。
Unihan,GB18030,都能用,但是如果你觉得它坑了,你就来看看我这个。
有IDS为啥不用?首先俺这个更短。并且,现有这些一字一码的主要问题就是实际上还是在以今文字具体字形收字去重(很多时候去了个寂寞),用它表现字理、组字有更多的坑,尽管“Unicode不指定字形”。啊对对对。语义?不妨去感受下 CJK Radicals Supplement 区。兼容区用不用?兼容区撞了隶定卡不卡?来点“月、宁、享、巿”?看看00xx、04xx、05xx区吧,古文字考虑过么?小篆区据说要开了,甲骨文准备等多久?
这部分的确很难,本方案与理想也还差得远。
字理需要的部件大量在扩BCDEFGH,大字集字体都得开天窗,知乎还能给你吃了;要么有匹配上放在PUA里的部件,不符合标准不认;单字隶定避这避那字形又怪,也没有文档说明是什么字里的什么。我们自己的字符集其实也都没做好,某种意义上,方正甲骨文算是干了一些事。
以及历史包袱,真就是一包袱九万个好东西,但是国标还是已经把整坨咽下去了。
导致做汉字处理门槛太高,一涉及细节,必然拦在面前。做6763别人看不起,做20902里面就已经有很多答辩了,做8105国内好了,想显示繁体字日语又开天窗了还是成问题。日韩汉字并没有多出“很多东西”,pan一下cjk咋就那么难呢?为什么还是经常无奈得用含有繁体部件的字呢?确实还是需要一个更《科学》(人话:人干事)的字符集,但这个字符集建立在什么之上呢?用什么来表示呢?
是有问题,但是为了兼容性,改是不可能改的,这辈子不可能改的,就是这样。等猴年马月它改了你再等做字人越过9万个好东西的包袱继续接受更新罢。
你字体字全吗?你输入法码表全吗?大字集覆盖多少?做字人、做输入法人、做动态组字人,对着那一大坨有动力做吗?
但是磕字理不容易,感谢所有汉语言文学文字学研究者的辛勤劳作,感谢所有我用过的网络字典工具无私分享。
难还难在确实还有些东西确实没有定论,还有些字可能还在地下没挖出来。同样,这个理可能也不唯一(不同时代不同层次),理还可能是被群众重新创作的(理据重构),理有些时候也是坑。留有一些余量,但只要下刀一定还是会有错的。
但至少,不再需要“值値晚晩”这种破事了。
所以本编码的理念依然是,填小坑,明大坑,排除障碍,加速向前。虽然讲理,但还是一定程度的能用就行。至少,你懂的。
一些可供感受的链接
金融业生僻字信息平台-北京金融科技产业联盟 这网页标题图上的常见生僻字,只有一对“㬎显”在本编码里统合,需要变选区分,别的全部直接组(简繁同码)就完事。
Group:sinzengo_U外字集01 - GlyphWiki
工具网站链接
ZZDMCodec 几种表现形式的转换器,用于转换文中的示例(待补全
todo
说文妙妙篆、异形方言字等等待收集整理,码位可选变体表、以本编码表示的CJK通行推荐字集,都还有待确定码表后进行(不过总的来说,所有单码字+8105+少量“常用生僻字”、你关注的独有的字,就接近可用了)
字库格式、渲染器、排版器、文本框,从通规、gb2312、unicode但带有地区模式选择(应对“㝉宁寧么幺”等)加坑码警告的转码表转码器,词库,输入法对接,适应本编码的简繁互转,都是后续任务,还得慢慢来……
附录(并不
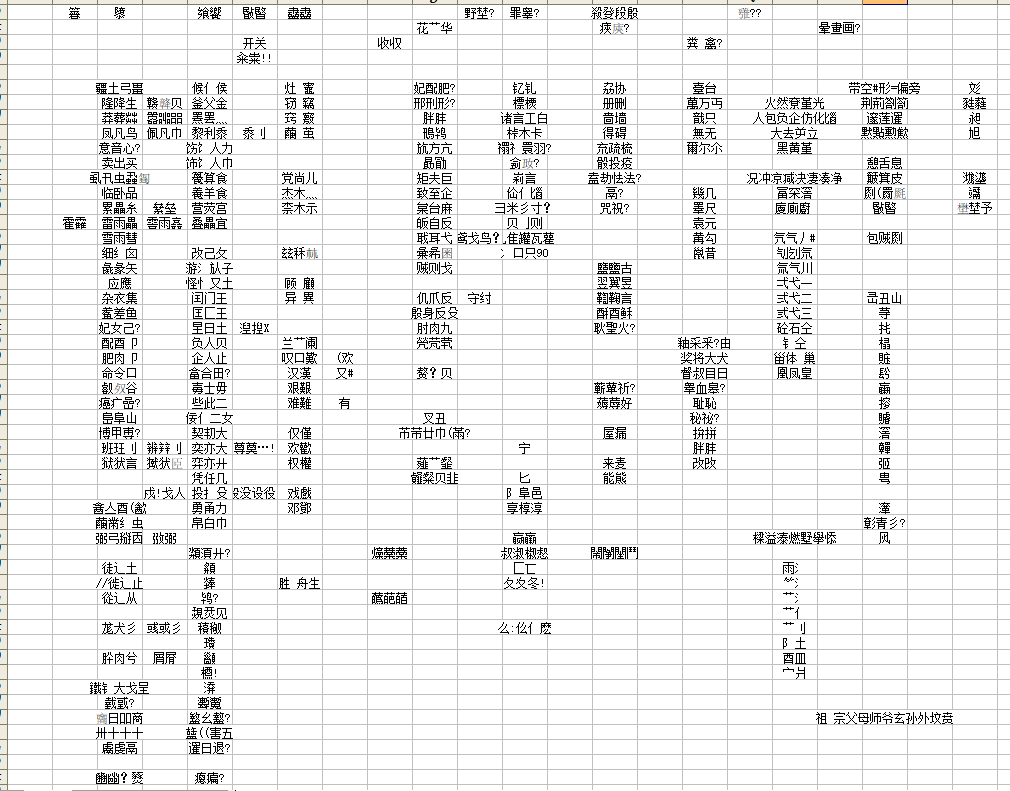
也就是至少还有这么多坑,从浅到深的
最后
尚未定稿,表与细则仍在调整,欢迎查漏补缺,欢迎各种建议!
欢迎分享你身边的地名人名生僻字,作为参考,也是为本编码码表字表贡献力量!
提建议时,可以查查它(各个部件)的甲骨文怎么写的。甲骨文好玩。方正甲骨文字体是免费使用的哦。
如果有什么地方觉得本文没有说清楚,欢迎提问,我会参考完善本文。
屁牌字理组字编码QQ裙:435296404,如果你坚持看到了这里,欢迎加入咨询与讨论!
【虽然有个《编码的汉字与汉字编码》裙是符合本话题的,但想了想还是避免打扰分开吧】

 浙公网安备 33010602011771号
浙公网安备 33010602011771号