二分搜索
二分搜索
看到优化O(logn)时间复杂度问题, 一般用二分搜索
模板
int start = 0, end = array.size()-1, mid;
while (start + 1 < end){ //该结束条件表示:当start与end指针相邻(start + 1 == end),或者相交,或者错开 时终止,**一般是相邻时终止**。
mid = start + (end - start) / 2;
比较 A[mid] 与 target, 并且挪动 start 与 end 指针
}
此时,start与end相邻,分别判断start 与 end 谁是我们需要寻找的节点。
经典难题
寻找两个数组中第k大的元素 (O(log(m+n)))
这个问题最暴力方法是分别将两个数组按照大小合并为一个数组,新数组的第k个就是答案。以下基于此优化
看到O(log)级别的时间复杂度首先想到用二分搜索解决,但是难点在于如何每次将问题模型减小一半?
- 二分减小问题规模
问题给定了两个数组,从直观上很容易想到分别将k/2的数据分给A、B两个数组,去比较它们k/2位置元素的大小。但如何通过比较大小的结果来减小问题的规模呢?
第k个元素不可能出现在k/2位置较小的那个数组里,反证法可以证明:
假设B[k/2]<A[k/2],所求第K大元素出现在B的前k/2中,m为其在B中下标,那么根据暴力合并法过程我们知道:B[m]晚于A[k/2]合并入新列表,即B[m] > A[k/2],
这与我们的假设 B[m] < B[k/2] < A[k/2矛盾。
所以第k个元素不可能出现在k/2位置较小的那个数组里
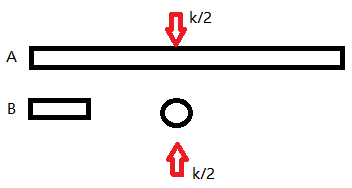
所以基于以上理论我们可以根据比较结果每次排除k/2较小数组的之前元素 - 当k/2位置超过了某个数组的边界了怎么办?
![|center]()
如图所示,这时第k大元素不可能在A的前k/2位置,仍然可以通过反证法证明:
假设第K大元素在A的前k/2位置的某处m,那么在暴力合并过程中B数组需要拿出多于k/2的元素来补够新数组有K个,但是B本身没有那么多元素,所以不可能出现
所以此时,我们可以将A的前k/2元素移除来减小问题规模。
题目
code
int findkth(vector<int> A, int startA, vector<int> B, int startB, int k) {
//考虑存在空数组
//并且startA与startB移动过程也可能移出所有元素,此时相当于A或B为空
if (startA >= A.size()) {
return B[startB + k - 1];
}
if (startB >= B.size()) {
return A[startA + k - 1];
}
if (k == 1) {
return A[startA] < B[startB] ? A[startA] : B[startB];
}
int A_key = startA + k/2 - 1 < A.size()
? A[startA + k/2 - 1]
: INT_MAX;
int B_key = startB + k/2 - 1 < B.size()
? B[startB + k/2 - 1]
: INT_MAX;
if (A_key < B_key) {
return findkth(A, startA + k/2, B, startB, k - k / 2);
}
else {
return findkth(A, startA, B, startB + k / 2, k - k / 2);
}
}
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/7116852.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号