[目标检测]RCNN系列原理
1 RCNN
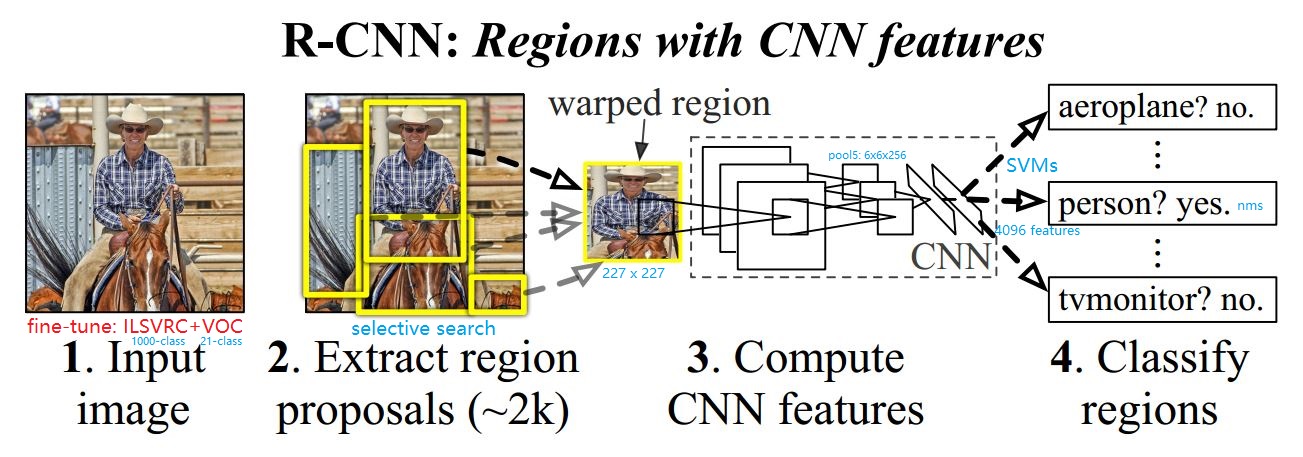
1.1 训练过程
(1) 训练时采用fine-tune方式: 先用Imagenet(1000类)训练,再用PASCAL VOC(21)类来fine-tune。使用这种方式训练能够提高8个百分点。
(2) 训练时每个batch的组成: batch_size = 128 = 32P(正样本) + 96(负样本组成)。可以使用random crop实现。
1.2 Inference过程
(1) 测试过程使用Selective Search生成2000个建议框,对建议框进行剪裁并调整尺度为227x227,以此保证全连接层得到特征为4096的固定长度。
(2) 剪裁后的proposal进行resize可能会使建议框区域变为畸形区域(warped region),因为selective region生成的region box形状长宽不一定相等。
(3) nms: 非极大值抑制: inference时,当某个小块中存在多个相同类别时,先确定最高分者,再将与最高分者重叠的预测结果去掉。
(5) 在pool5时,每个fearture map为6x6的尺寸,特征图中每个点可以感受到warped image中的195x195的区域。
1.3 RCNN缺点
(1) 多阶段训练: 预训练(ImageNet) + Selective Search + CNN特征提取器(VOC) + 分类器(SVMs) + 边界框回归器(LR)。
(2) 从每个建议框中提取的特征向量(1x4096)存储于硬盘,消耗大量时间空间成本。
(3) 每个warped region都需要重新送往CNN提取特征,多次重复卷积计算。
(4) Inference一张图片耗时太长,GPU: 13 s/frame,CPU: 53 s/frame。
SPP-Net
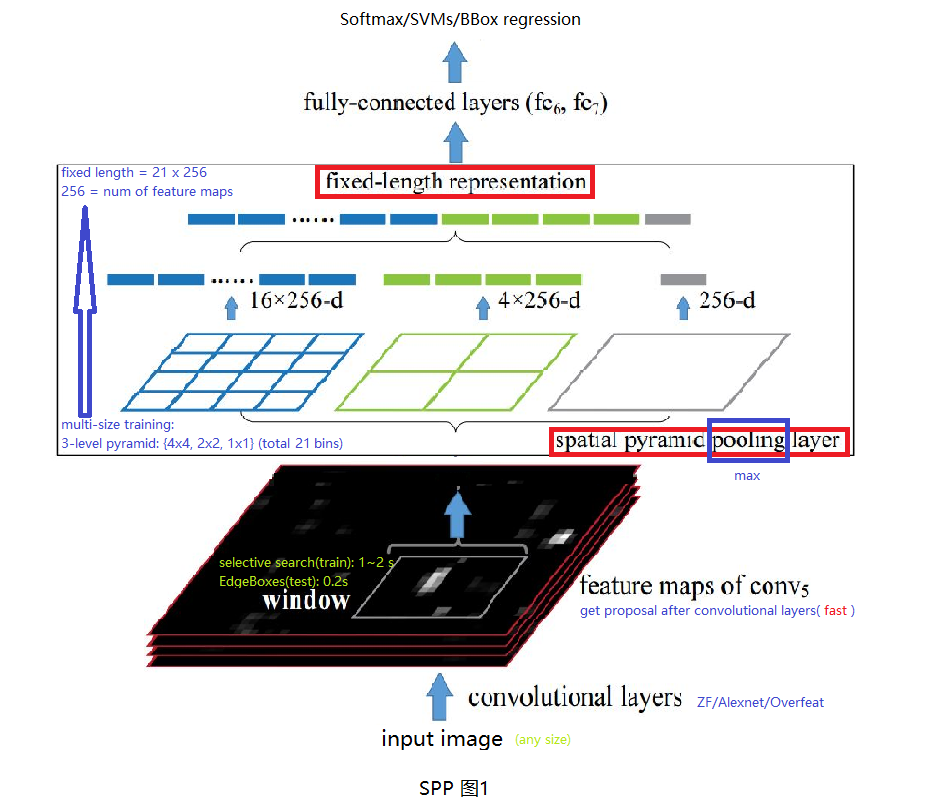
2.1 Inference过程
任意尺寸图像输入CNN(ZF/Alex/Overfeat)中,使用CNN卷积层部分得到最后一层特征向量,使用EdegeBoxes计算特征图中建议窗口(proposal wndows),使用SPP层将特征图转换为定长特征向量,该向量长度与SPP层参数及特征图个数有关。将定长特征向量经过两个全连接层后输入分类器(Softmax/SVMs)及回归器(BBox regressor)中。
2.2 SPP改进
(1) RCNN中对proposal region进行resize会使输入变得畸形,影响检测结果。而只有FC层才需要固定长度特征向量,因此,作者提出卷积层最后的池化层换为SPP层,使不同输入图像进入FC层之前能够变为相同长度特征向量。
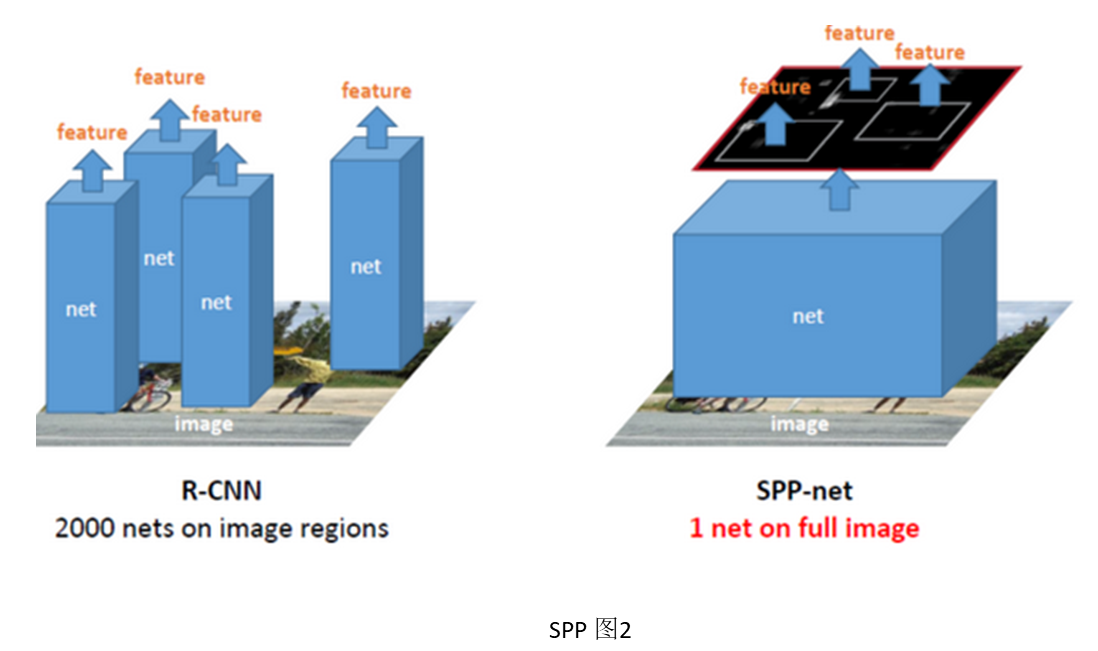
(2) 将原图放入CNN中计算到Conv5再进行选择proposal,然后SPP。这样只用做一次卷积部分运算(卷积层很费时),共享卷积层计算,加快了前传速度(24~102倍 x RCNN, 0.14s Vs 9.03s),这里有个很好的SPP与RCNN计算差别示意图见SPP图2,参考。
(3) 至于SPP-Net如何将EdegeBoxes/SelectiveSearch生成的建议框映射到特征图中,文中最后附录A也进行了说明,也可以参考里面的说明。其实,
x为原图中坐标,x`为特征图中的坐标,S为原图与特征图之间所有卷积或者池化层的核步长的乘积。
2.3 SPP训练
(1) 使用fine-tune的对SPP的效果不大。
(2) 在训练时每个epoch使用不同的输入图片尺寸(因为Caffe,cuda-convnet不支持变尺寸做为输入进行训练),这样可以增加数据,并且增加网络对目标尺寸的鲁棒性。
2.4 SPP缺点
(1) 多阶段训练: 预训练(ImageNet) + Selective Search + CNN特征提取器(VOC) + 分类器(SVMs) + 边界框回归器(LR)。与RCNN一样,多阶段分开训练。
(2) 特征图存储硬盘,时空开销大。
(3) 文中2.3节提到SPP-Net与RCNN都使用低效的更新参数方式,限制CNN网络精度的提高。这可能是因为他们训练过程都是多阶段组合,每个阶段都只能更新需要被fine-tune部分的参数。例如,在训练SVMs分类器过程中,CNN部分参数并不能被更新。
3 Fast-RCNN
创新点: 合并CNN特征提取模块与分类回归模块 + ROI pooling(SPP的特例)

3.1 Fast-RCNN 相比于SPP与RCNN的改进
(1) CNN特征提取模块与分类回归模块三者合并,除(RP生成模块)之外部分实现端到端训练,并且使用回归与分类之和的multi-loss监督网络收敛。带来以下好处:
- 加快测试速度:CNN特征提取模块如果独立,那么需要将提取的特征存储于硬盘中,导致占用大量硬盘,并且训练与Inference的速度都非常慢。
- 提高模型精度:CNN模块、分类模块、回归模块如果三者独立,那么需要分三个阶段对每个模块进行finetune,在训练每个模块的过程其它模块参数保持不变,使得反向传播过程参数更新的不充分,限制最终模块精度的提升。
(2) ROI池化取代SPP-net中SPP池化,好处是本来SPP池化生成的是定长特征向量,但ROI池化生成定尺寸特征图,保留了特征的空间位置特征,这一步的作用在Faster-RCNN中才能体现。其实,ROI池化得到的只是SPP多尺度金字塔的其中一层。
(3) 训练过程中,Fast-RCNN相对于SPP与RCNN每个Iteration更快并且反向传播更充分,原因在于Fast-RCNN每个Iteration中128个样本取自于两个样本图像,而SPP与RCNN每个样本取自于一张图像。更快的原因:SPP虽然使用了共享卷积部分计算的机制,但是由于每个样本取自于不同图像,那么训练过程的共享计算机制相当于无效,而RCNN没有共享计算机制。反向传播更充分的原因:每个ROI样本在原图中感受野很大几乎接近于原图大小,Iteraions中不同样本取自于同一张图,那么不同样本之间的相关性很大,这样的一个batch对于SGD的反向传播有很大的益处。以上结论参考于Kaiming ICCV2015报告分享。
3.2 Fast-RCNN实验结论
- 基于Imagenet预训练模型 fine-tune的方法:
训练数据输入为图片列表与每张图片对应的ROI位置,替换最后一个pooling层为ROI pooling层,softmax分类器替换为一个分类+回归的双任务层。 - 实验证明:对于Alexnet这种小网络,从第三个卷积层开始fine-tune才有意义,第一个卷积层独立于所做的任务,只是提取基于线条特征,第二层fine-tune与not fine-tune效果差距不大
- 实验证明:对于分类任务,使用softmax与SVMs分类器效果差异不大,因此,没有必要像RCNN一样,fine-tune的时候来回切换不同的分类器。
3.3 Fast-RCNN中FC层加速
在分类任务中,卷积层部分与全连接层都只做一次,卷积层耗时巨大。但在检测任务中,每图卷积一次,但对每个建议框都要做一次全连接层计算,这时全连接层耗时相对变大,作者的加速方案为truncated SVD。
SVD加速全连接层的原理如下:
其中,\(dim(W) = u x v\), \(dim(U) = u * t\), \(dim(V) = t * v\),如果\(t<<min(u, v)\),那么计算三次内积的计算量\(t*(u+v+t)\)要小于计算一次内积的计算量\(u*v\)
加速前后效果图如下:

4 Faster-RCNN
创新点: Fast-RCNN + RPN
本文主要提出了RPN,即建议框生成网络,该网络与Fast-RCNN网络共享卷积层参数,从而低代价生成了更精准的建议框,并且将建议框生成算法与目标检测算法统一于一个网络
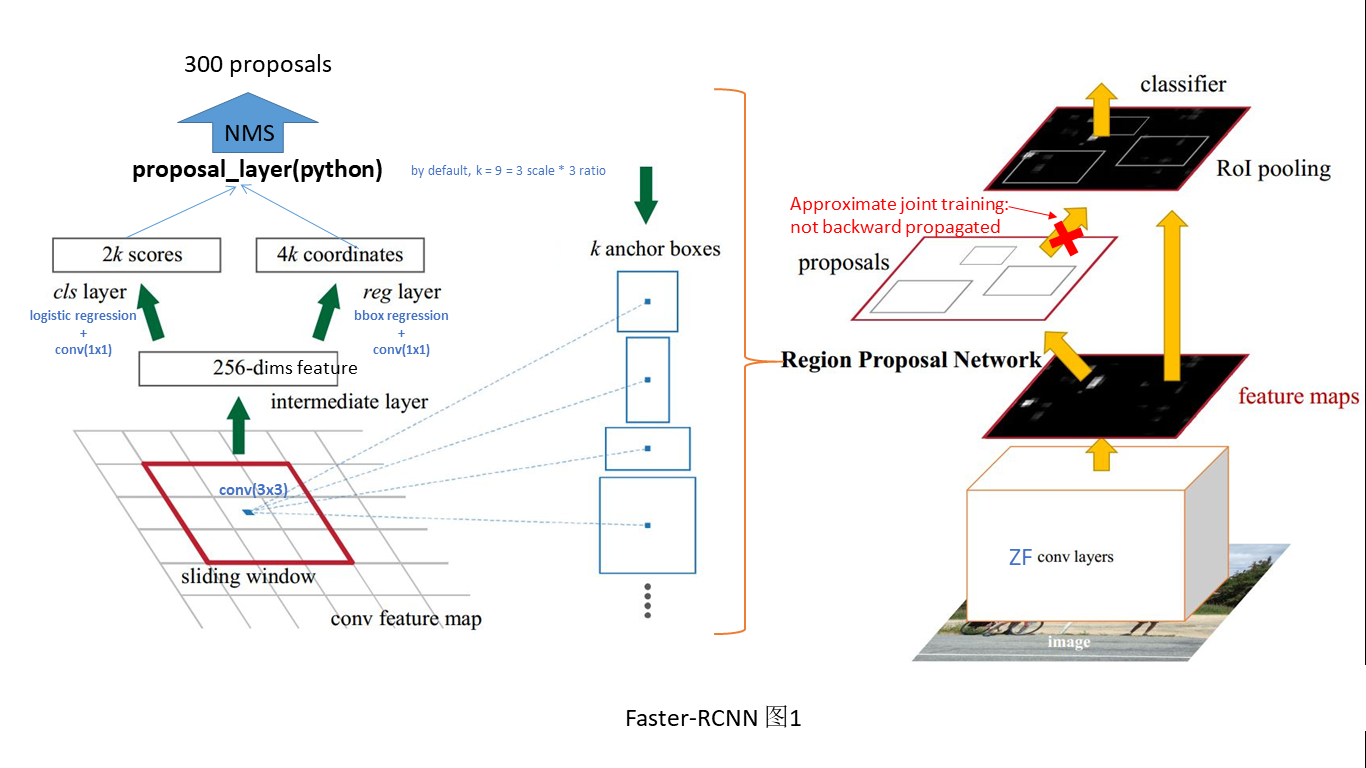
4.1 RPN探究
RPN测试过程
本文相对于之前的Region proposal系统的检测算法的核心创新就是提出了RPN网络从而低代价生成高召回率的建议框,但是RPN网络到底长什么样,如何实现的呢?以下内容对照Faster-RCNN图2进行解释:
RPN网络是一个全卷积网络,如图中绿线部分所示,在末端卷积层使用3x3卷积核提取特征图,再使用两个1x1卷积分别得到2k(k为anchor个数)分类特征与4k的回归边界框位置,将2k的分类特征经过softmax将特征整合为概率值。最后proposal_layer将边界框位置与概率经过非极大值抑制后,映射到末端卷积层之后就可以ROI池化,其余过程与Fast-RCNN一样。整个过程参见Faster-RCNN图2。
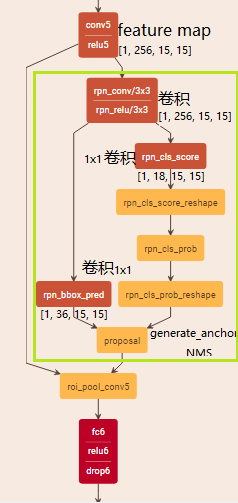
RPN训练过程
看到这里有个困惑: 为什么经过1x1的卷积核就能生成所需要比例与尺寸的anchor?
仔细看了一遍整个测试过程的prototxt与源码,卷积前后并没有设置anchor的形状与尺寸的参数,为什么经过两个1x1的卷积核之后生成的就是所设计的9种anchor呢?
答案需要从训练过程说起:
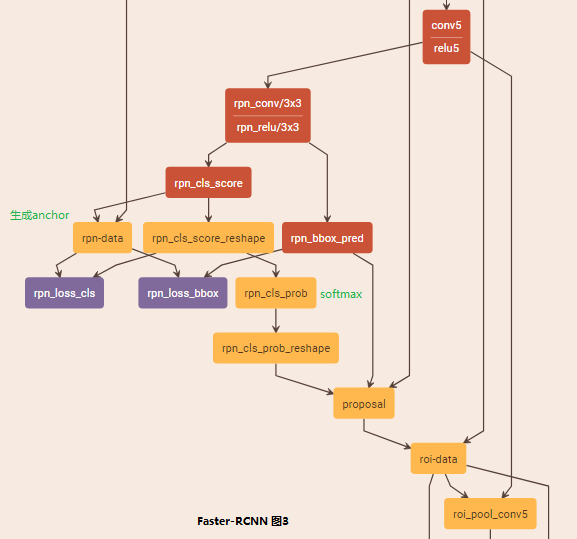
Faster-RCNN图3为RPN网络的训练结构示意图,与测试过程不同的是增加了GT标签与loss函数。其中,pn-data层接收GT标签数据,并且将输出的结果和预测到边界框位置及概率计算RPN损失函数,由anchor_target_layer.py文件实现。
layer {
name: 'rpn-data'
type: 'Python'
bottom: 'rpn_cls_score'
bottom: 'gt_boxes'
bottom: 'im_info'
bottom: 'data'
top: 'rpn_labels'
top: 'rpn_bbox_targets'
top: 'rpn_bbox_inside_weights'
top: 'rpn_bbox_outside_weights'
python_param {
module: 'rpn.anchor_target_layer'
layer: 'AnchorTargetLayer'
param_str: "'feat_stride': 16"
}
}
再看anchor_target_layer.py中,初始化过程中调用genertate_anchors函数生成九种anchor,前传过程中前anchor转换为真正的GT的anchor监督预测的结果。
class AnchorTargetLayer(caffe.Layer):
"""
Assign anchors to ground-truth targets. Produces anchor classification
labels and bounding-box regression targets.
"""
def setup(self, bottom, top):
layer_params = yaml.load(self.param_str_)
anchor_scales = layer_params.get('scales', (8, 16, 32))
self._anchors = generate_anchors(scales=np.array(anchor_scales))
self._num_anchors = self._anchors.shape[0]
self._feat_stride = layer_params['feat_stride']
。。。
def forward(self, bottom, top):
# Algorithm:
#
# for each (H, W) location i
# generate 9 anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the 9 anchors
# filter out-of-image anchors
# measure GT overlap
所谓种什么瓜,结什么果,因为训练过程中每个特征图上生成的(2k + 4k)个值是由GT的anchor位置与概率来监督产生loss的,那么模型收敛后自然预测的是参考9种anchor的预测结果。
4.2 Faster-RCNN训练过程
(1) 交替训练:
1). fine-tune RPN on Imagenet.
2). 用RPN生成的建议框来训练Fast-RCNN.
3). RPN共享Fast-RCNN卷积层,fine-tune RPN网络.
4). fine-tune Fast-RCNN
(2) 近似连接训练:
直接按照一个合并的网络训练,但是Fast-RCNN反向传播过程不传向RPN网络,依靠RPN网络自身loss反向传播
4.3 Inference过程
(1) 基础网络部分作者使用用ZF(17fps)与VGG(5 fps)
(2) 建议框NMS到300个就能达到很好效果。
(3) 生成建议框后,ROI池化是在末端卷积特征层上进行的。
4.4 缺点
基于region proposal系统方法通病,需要分别对每个ROI进行识别与精定位,相当于得到ROI之后,分别依次对每个ROI进行后续全连接层的处理。
Faster-RCNN比较明白的blog
还有一些细节可以参考
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/6784781.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号