[PaperReading] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
link
时间:21.06
作者与单位:fairseq

作者相关工作:
被引次数:2741
主页:https://github.com/facebookresearch/fairseq/blob/main/examples/hubert/README.md
TL;DR
自监督学习的语音表征学习有两个难点:a) 同一个词汇中有多个音素;b) 音素是变长的,没有明显的分割边界;本工作提出的HuBert(HiddenUnit)预训练算法,利用离线的聚类算法,使该任务能像Bert一样预训练。效果超越wav2vec 2.0。
Method
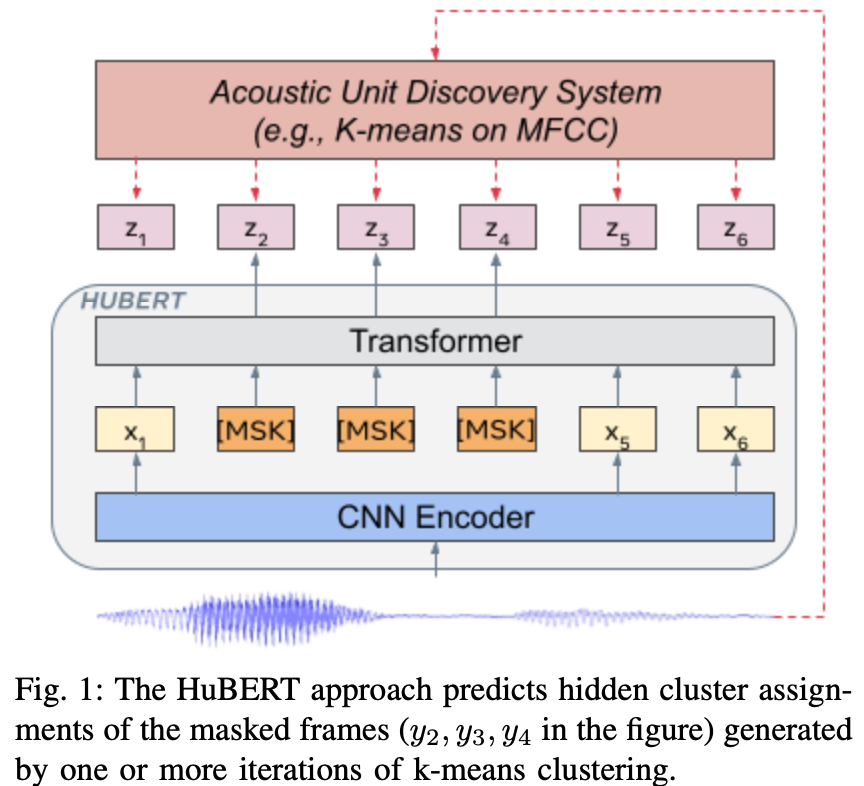
Learning the Hidden Units for HuBERT
输入一帧语音基本单元,通过过聚类算法(eg. k-means)得到Hidden Unit(聚类的类别)
Representation Learning via Masked Prediction
语音序列经过CNN抽取等长特征后,Mask掉特征序列中部分特征,使用Transformer预测Mask部分的Hidden Unit \(L_{m}\)以及unmask部分的Loss \(L_{u}\),再将两者通过超参加和。
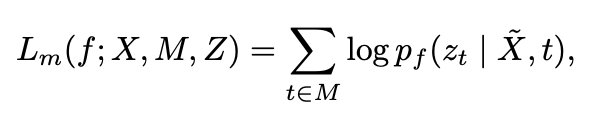
Learning with Cluster Ensembles
多个聚类算法产生多组标签效果更好,例如,k-means使用多种k产生Label组合的Loss。
Implementation
https://github.com/facebookresearch/fairseq/blob/main/examples/hubert/README.md
Experiment
预训练数据:60,000h音频
k-means打标: 960h跑k-means
- 不同时长数据集对比,都略优于wav2vec2.0
![]()
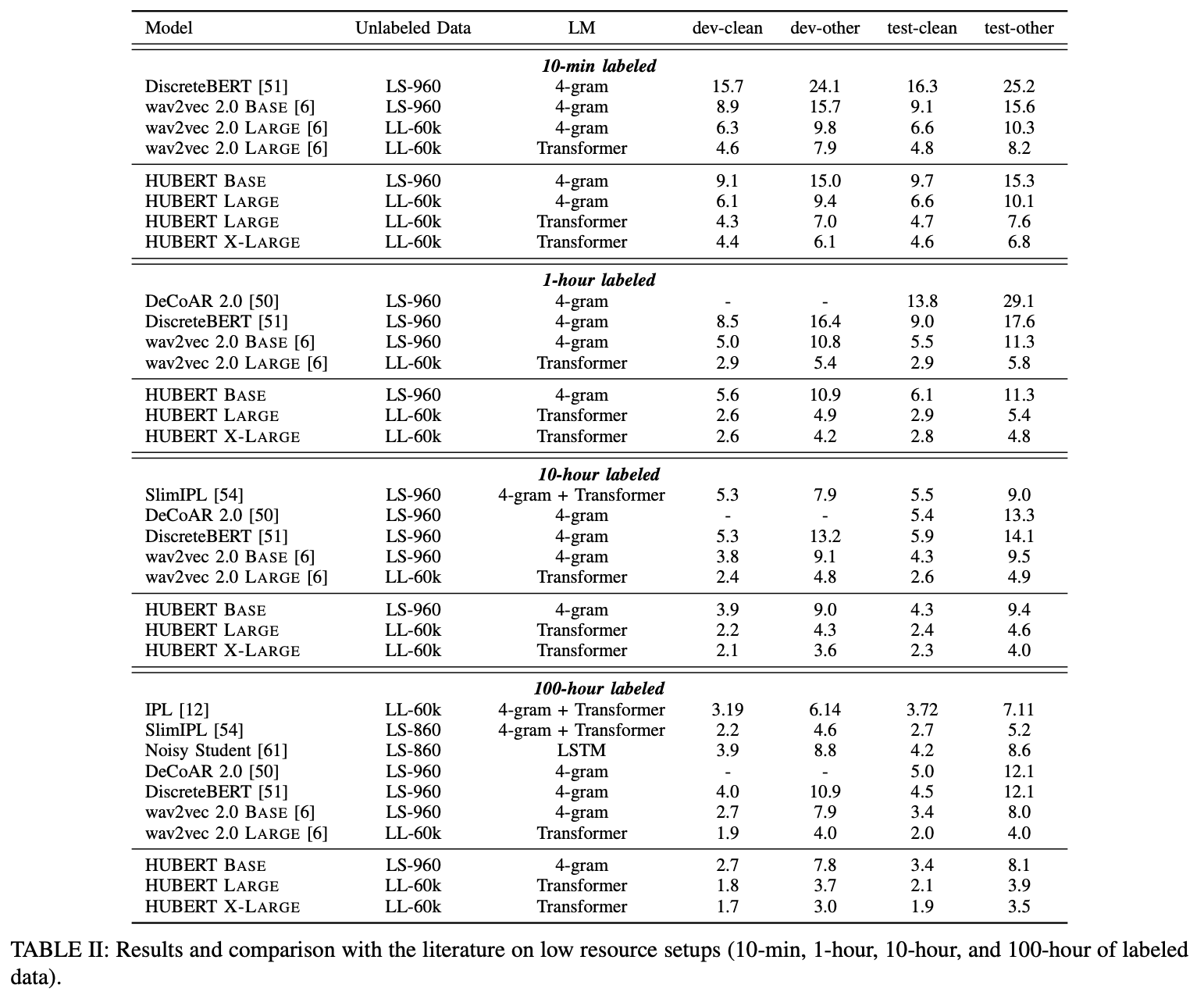
备注:指标为WER (word error rate),通过计算预测序列与GT序列之间编辑距离获得。
-
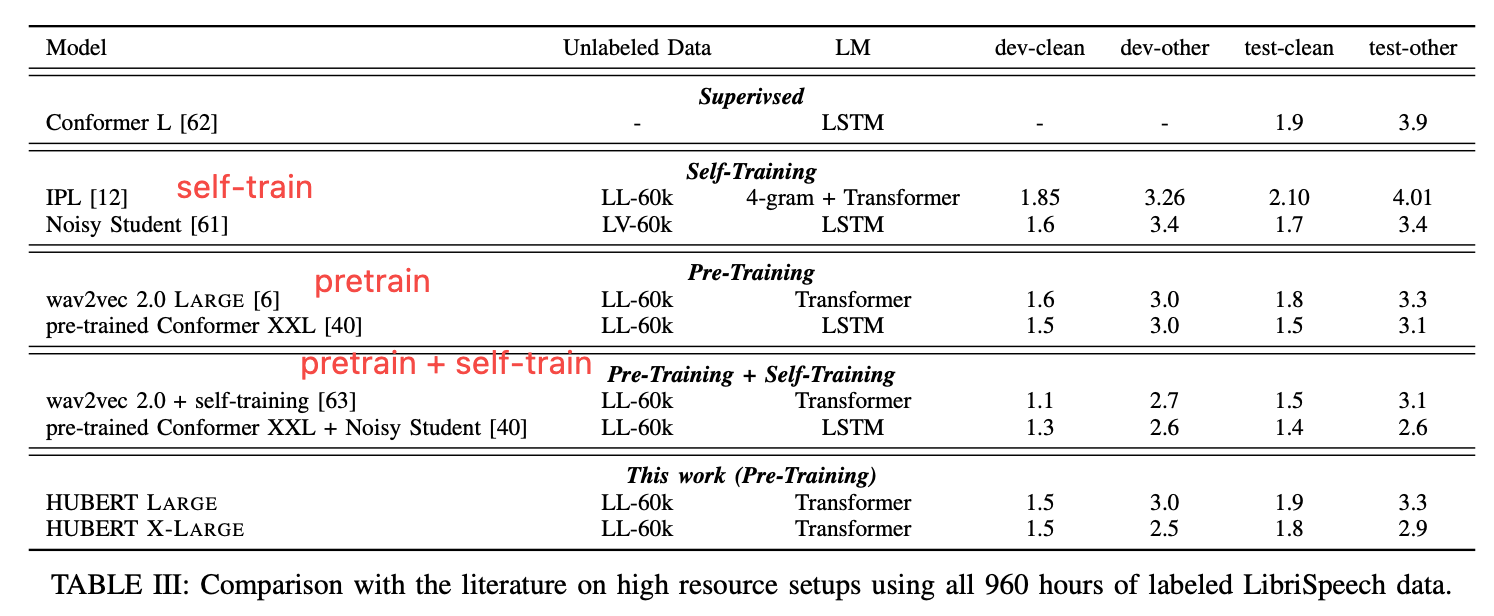
打平wav2vec,不如prtrain + self-train,但还没结合self-train
![]()
-
调整聚类超参
![]()
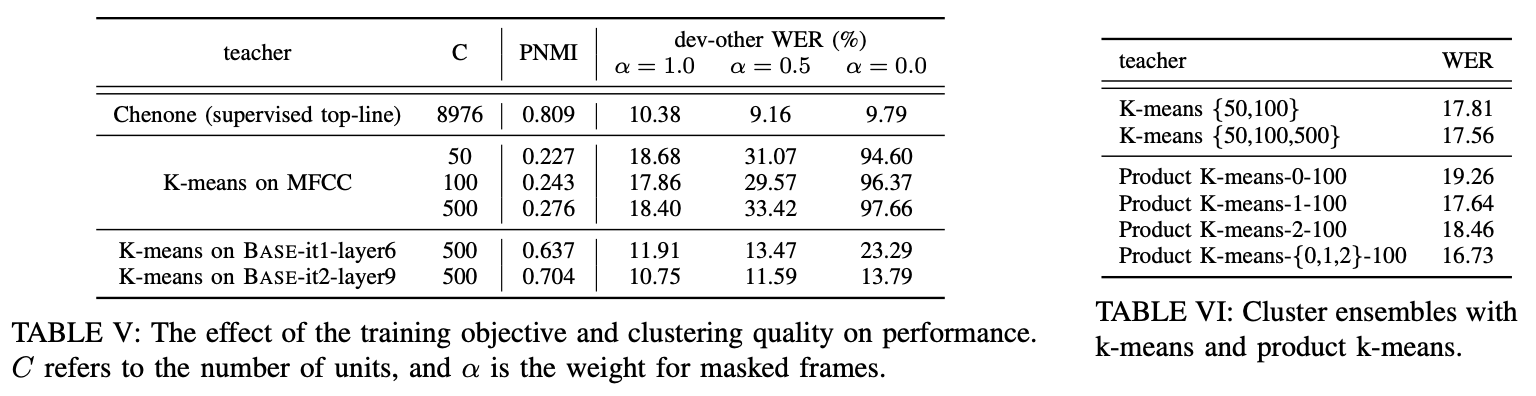
效果可视化
无
总结与思考
无
相关链接
引用的第三方的链接
Related works中值得深挖的工作
DiscreteBERT、wav2vec 1.0/2.0
ASR:Automatic Speech Recognition
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18582991

 浙公网安备 33010602011771号
浙公网安备 33010602011771号