[Paper Reading] Multi-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
目录
Multi-modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving
link
时间:CVPR2022
作者与单位:

相关领域:3D Human Pose Estimation、autonomous vehicles
作者相关工作:人脸识别
https://scholar.google.com/citations?user=Cc4I1vYAAAAJ&hl=en
被引次数:39
主页:无
TL;DR
自动驾驶场景的3D人体姿态估计数据量少,并且与其它场景无法复用数据。本文提出一种使用Lidar + Camera模态作为输入,利用2D标签作为弱监督信号,来估计3D人体姿态的方法。效果方面比纯视觉提升22%,比纯Lidar模型提升6%。
Method
算法架构
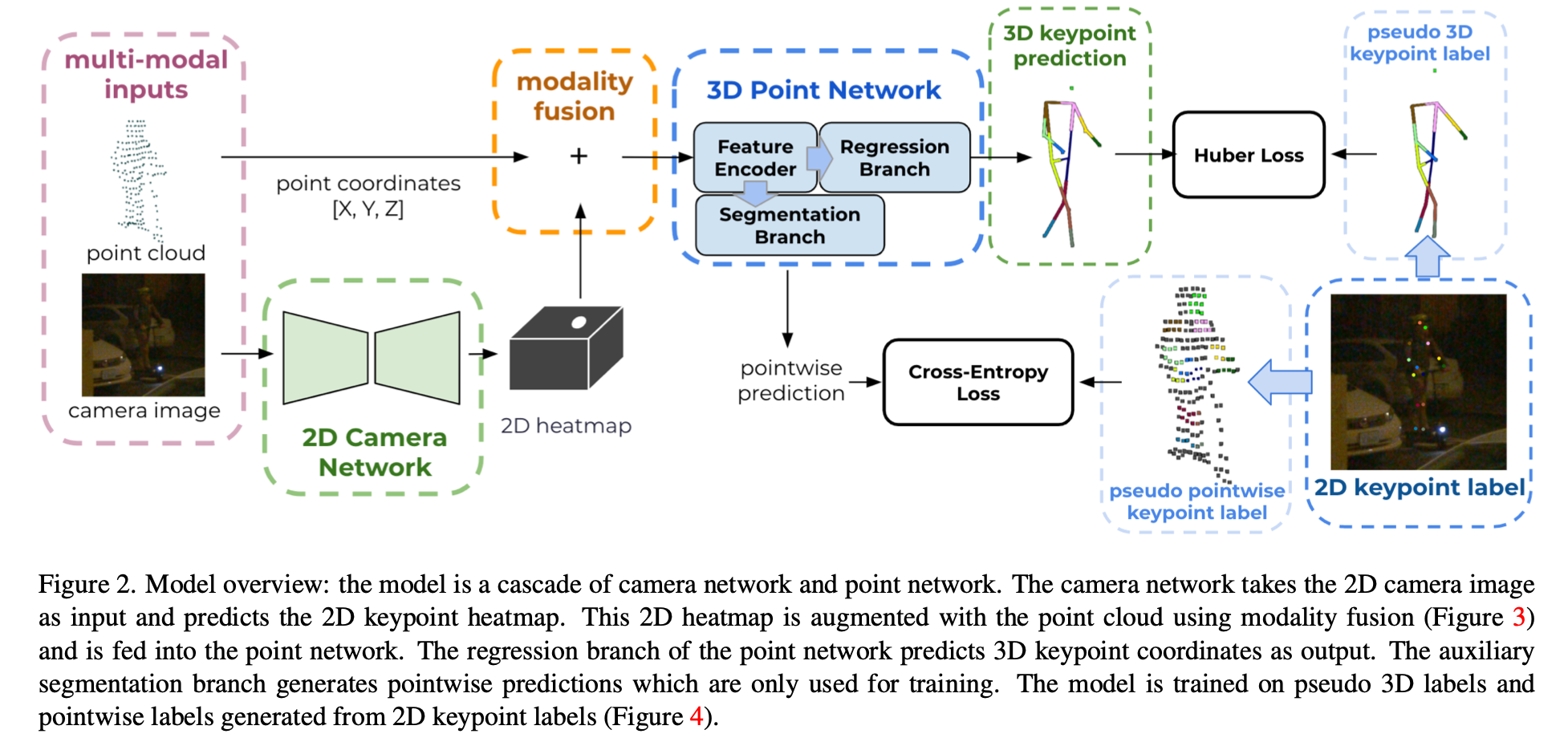
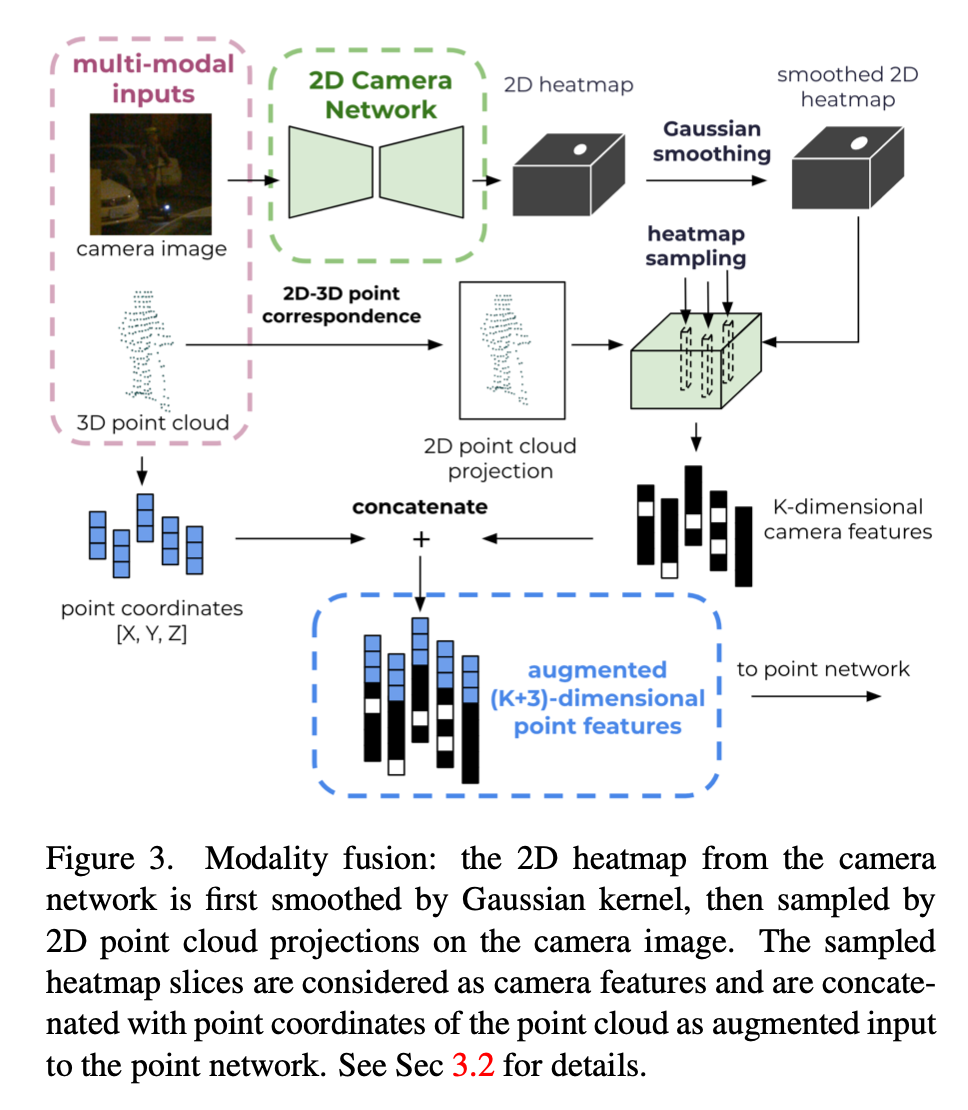
Modality Fusion of LiDAR and Camera
将3D点云Project为2D点,利用这些点位置在图像heatmap上grid_sample出图像特征点,再与对应的3D点云Concat,获得两种模态融合的特征。
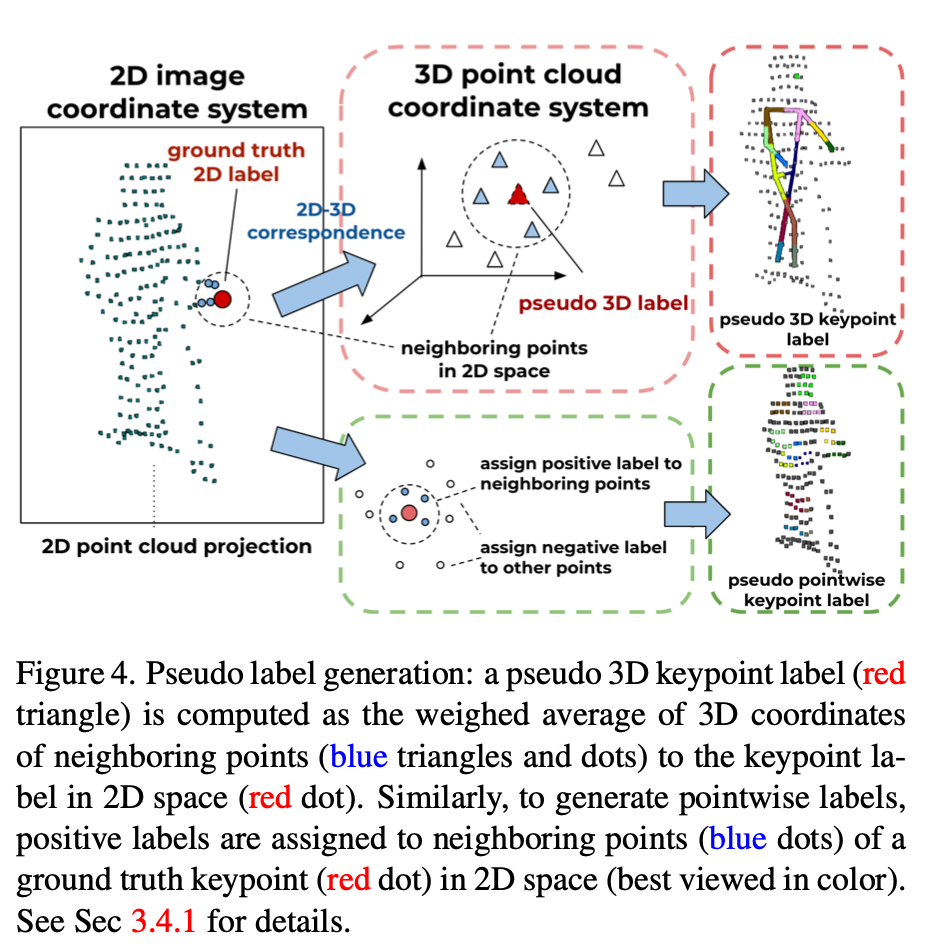
Auxiliary Pointwise Segmentation Branch
主要解决两个问题:
- 有2D点Label,如何获取3D点Label?
- 点云中的3D点,哪些是某个Joint的正样本?哪些是负样本?=> 用来作为点云Segmentation的GT。
核心处理思想是将点云投影到2D图像,与2D Label通过匹配机制来获取对应的3D的Label。
Implementation
使用Waymo Open Dataset,共19.7w行人。训练集本身有2D Label,测试集中2D Label是本工作中自己标注的。
Experiment
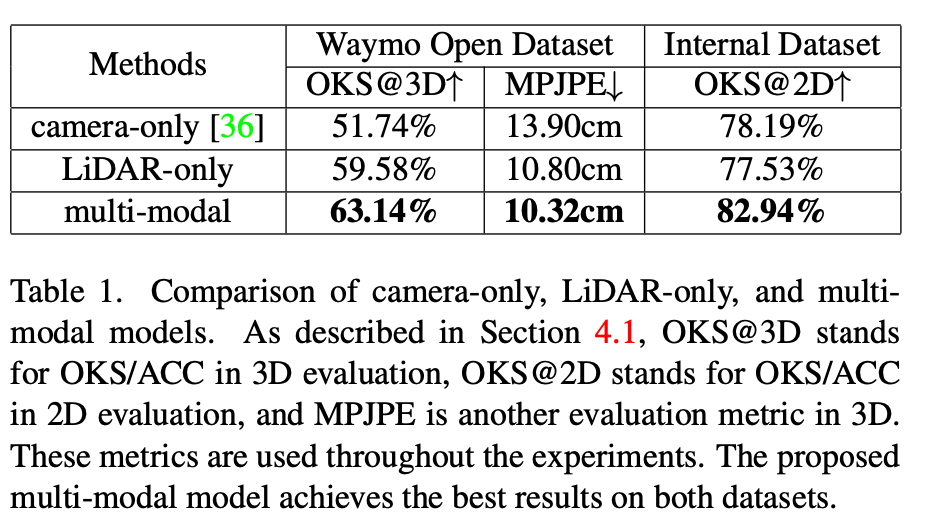
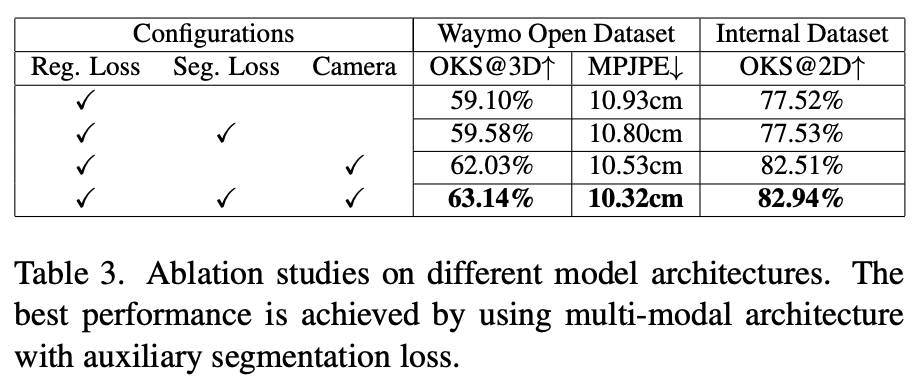
效果可视化
总结与思考
模态融合方式及2D Label构造3D Label的方式比较巧妙。
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18563782

 浙公网安备 33010602011771号
浙公网安备 33010602011771号