[Paper Reading] Fusing Monocular Images and Sparse IMU Signals for Real-time Human Motion Capture
名称
link
时间:23.09
作者与单位:

主页:
https://github.com/shaohua-pan/RobustCap
TL;DR
融合IMU与视觉信号做动捕是新Topic,IMU能够弥补视觉不足(FOV外、极端遮挡、光照 等)。方法层面使用双分支来处理两套坐标系,即IMU在人体root坐标系下估计body pose,同时会将IMU信号转到Camera坐标系下与视觉信号融合。实验证明这种方法能够打败 纯视觉、纯IMU及其它两者融合的方案。
Method
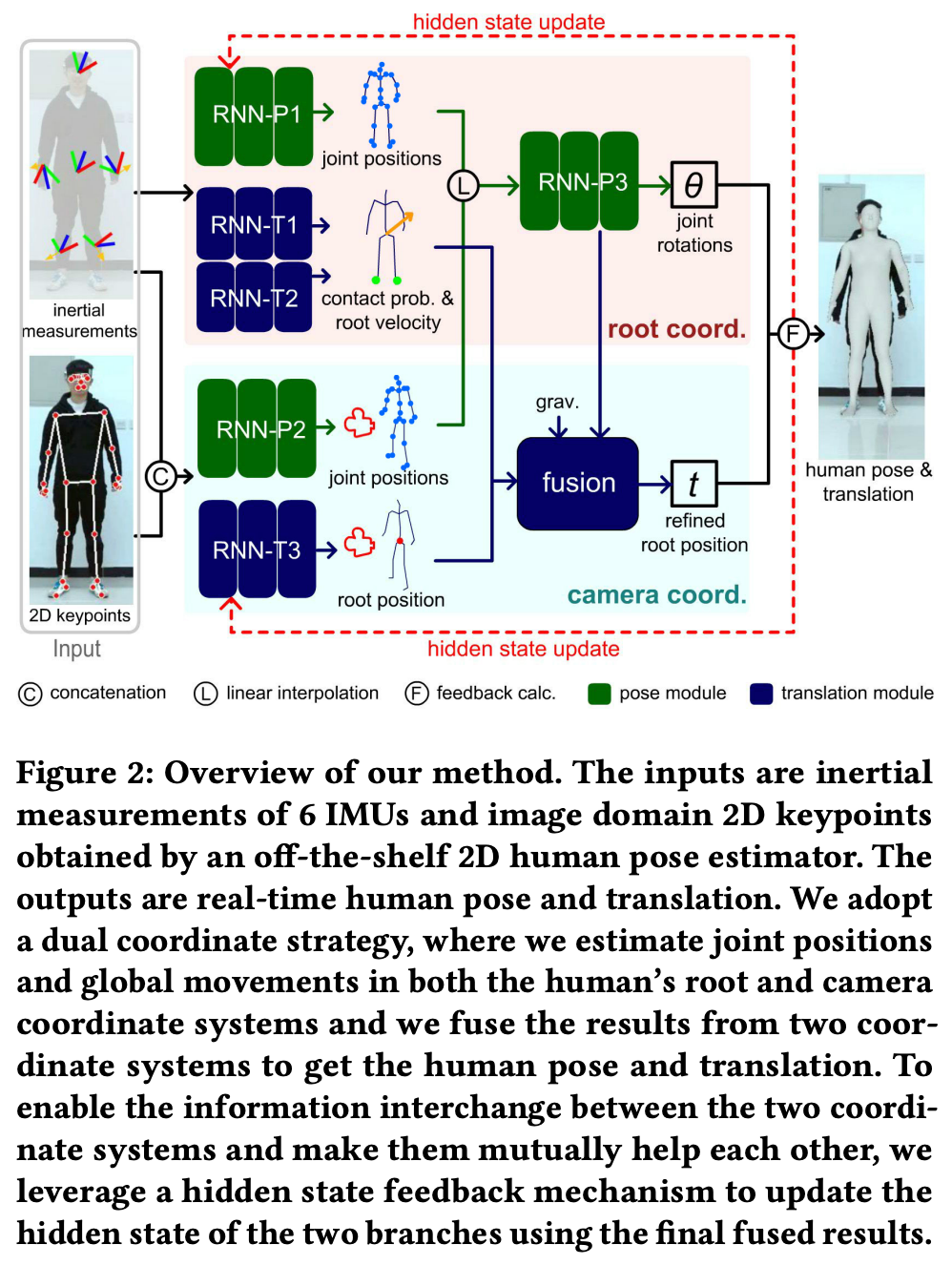
Local Pose Estimation
RNN-P1
输入6个IMU的rot与acc共12D的源数据,预测root坐标系下的相对joint坐标。
![]()
![]()
RNN-P2
结合视觉信息,预测camera坐标系下的相对坐标,Loss与上述相同。
![]()
\(x_c\)是Camera系下的IMU信息,由\(x_r\)从root系下转换而来。
\(P_{2d}\)是2D图像关节点(MediaPipe得出)变换至归一化平面点。
\(\sigma\)表示每个关节点置信度。
RNN-P3
用来融合两个坐标系下position,得到pose rotation。
step1:将camera系下\(p_c^e\)转到root系下,与\(p_c^e\)进行融合(直接用关节点置信度加权平均),再结合\(x_r\)预测joint rotations,Loss参考下面。

Global Translation Estimation
多模态预测root position及融合
RNN-T1
预测是否踩地,参考TransPose
RNN-T2
预测root点速度,通过积分来获得root position,参考TransPose
RNN-T3
用来通过视觉2D点预测camera坐标系下的root position
最终,根据置信度融合视觉与IMU的root position
![]()
Hidden State Feedback Mechanism
主要解决初始动作捕捉的问题(RNN模型中的hidden state对于不同初始姿态使用相同的hidden state),这是不合理的。这里提出的不同模态的hidden state信息交互来缓解这类Badcase。
这篇文章里面的 Hidden State Feedback Mechanism章节主要在用什么方法,解决什么问题?
FromChatGPT(这篇文章里面的 Hidden State Feedback Mechanism章节主要在用什么方法,解决什么问题? ) 这篇文章中的“Hidden State Feedback Mechanism”章节主要介绍了一种用于增强双坐标策略中两个分支的方法,解决的问题是在极端输入情况下如何提高运动捕捉的准确性和鲁棒性。具体来说,这个方法通过在两个坐标系统之间交换信息,使得在一种信号(视觉或惯性)不可靠时,另一种信号可以对结果进行校正和补充。该机制主要包含以下几个关键点:
双坐标策略的局限性:在双坐标策略中,两个分支(一个基于视觉信号,另一个基于惯性测量单元IMU信号)独立运行,没有相互之间的信息交流。这可能导致在某些情况下,如视觉信号不可用或IMU信号漂移时,单独的分支无法提供准确的运动捕捉结果。
隐藏状态的初始化问题:对于基于RNN的模型,如果使用固定的初始隐藏状态,可能会导致在跟踪过程中出现误差,因为人的起始姿势可能不同,错误的初始状态会导致网络无法根据变化的输入信号正确调整其隐藏状态。
隐藏状态反馈机制:为了解决上述问题,文章提出了一种隐藏状态反馈机制。这个机制允许在两个坐标系统之间进行信息交换,使得在某个分支表现良好时,可以帮助另一个分支提高性能。
具体实现:对于RNN-P1(基于根坐标系的局部姿势估计),当视觉信号足够好时,可以使用从RNN-P2(基于相机坐标系的局部姿势估计)获得的关节位置来初始化RNN-P1的隐藏状态。对于RNN-T3(全局位置估计),当视觉信号不可用时,可以使用最终融合的结果来更新其隐藏状态,以减少视觉信号不可用时的漂移。
效果:通过这种机制,当视觉信号恢复时,系统可以立即恢复到合理且与之前输出一致的结果,避免了突然的变化,特别是在目标重新进入相机视野时。
总的来说,隐藏状态反馈机制通过在双坐标策略的两个分支之间动态地交换信息,提高了系统在面对极端情况时的鲁棒性和准确性。
Experiment
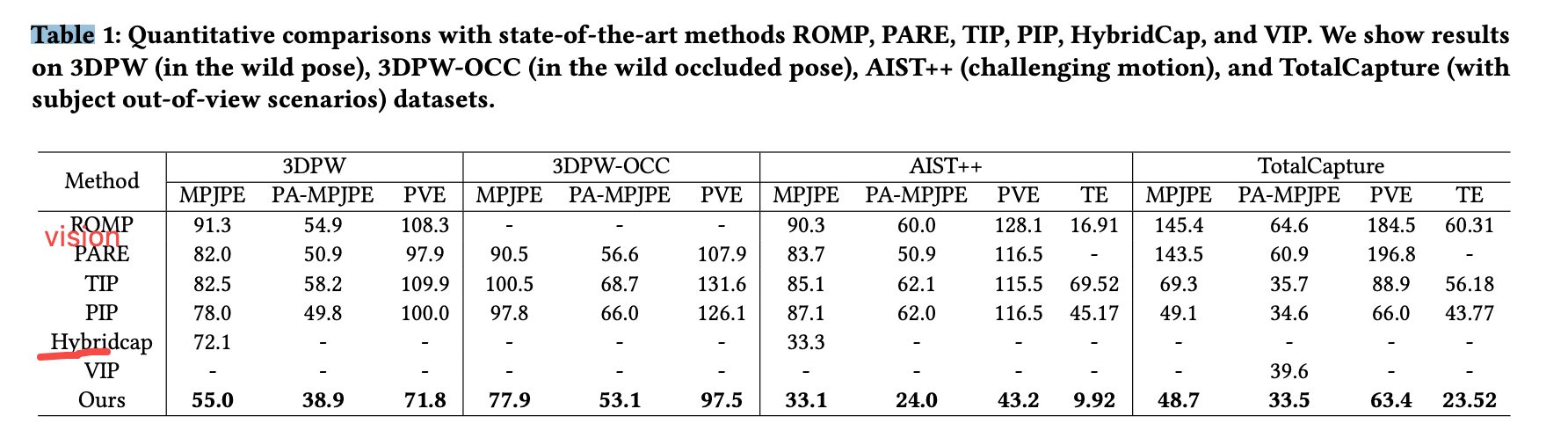
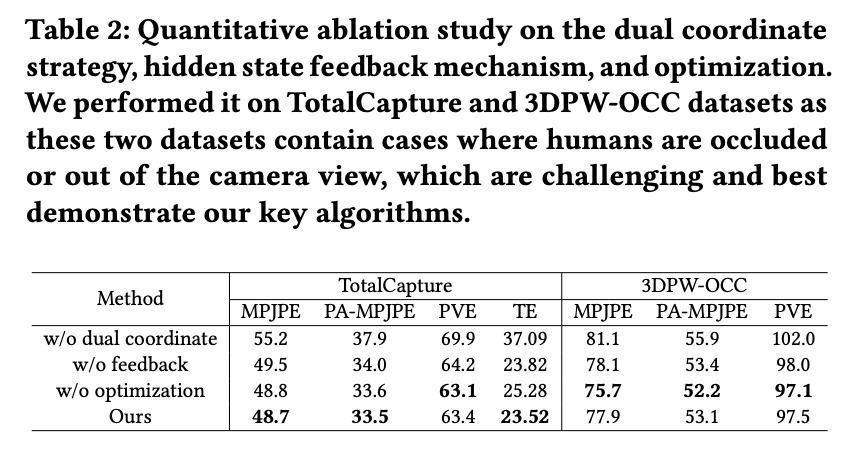
效果可视化

总结与发散
- 高低频率的融合没有重点介绍
- relative position与rotation与global的分开预测
相关链接
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18541715

 浙公网安备 33010602011771号
浙公网安备 33010602011771号