[Paper Reading] CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
名称
link
时间:23.03
机构:Baidu/华科
TL;DR
提出CAPE(CAmera view Position Embedding),主要创新:1) 在local-camera坐标系下建模3d position embedding而非global-camera系,使得3d position embeding与相机参数无关。2) 融合前后帧时序信息提升效果。
Method
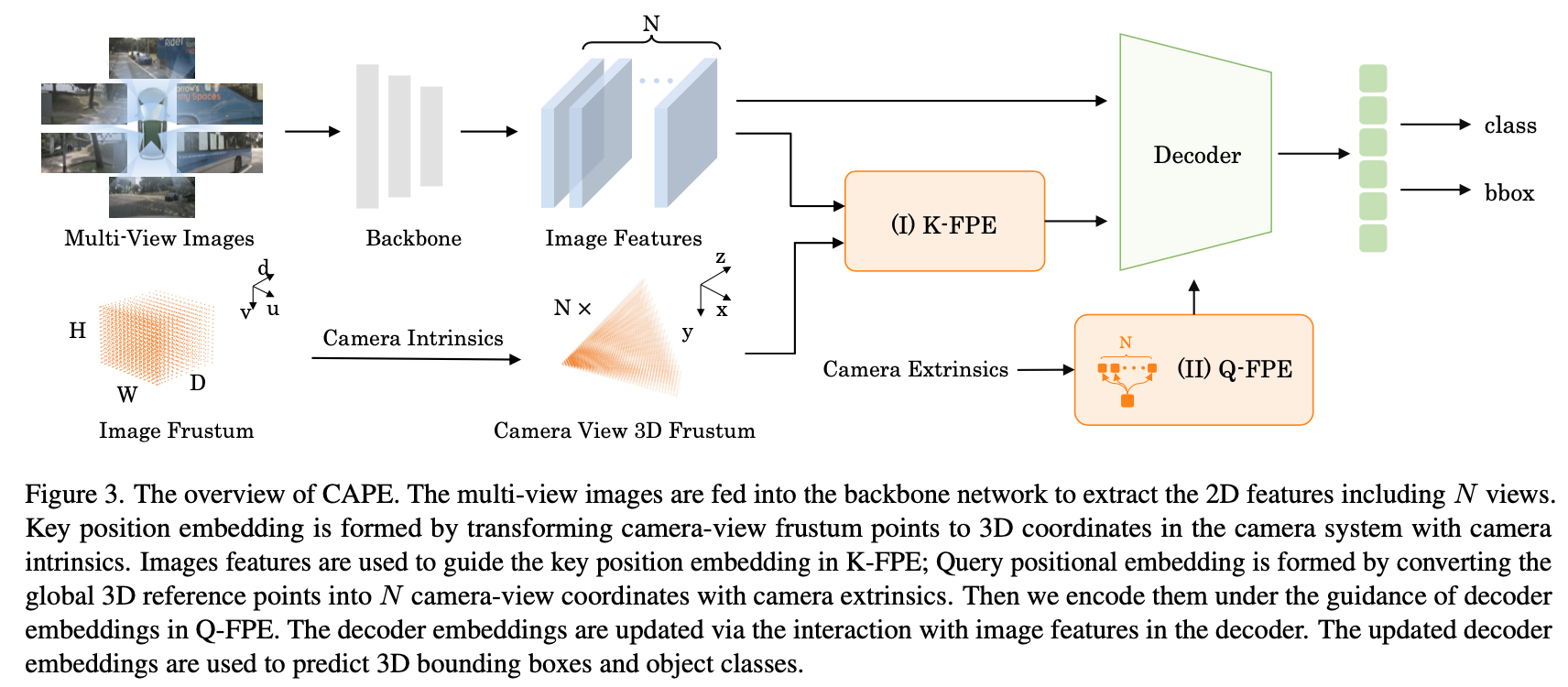
Key Position Embedding Construction
图像2D点坐标 -> 内参 + depth_bin -> 3D点 -> MLP Layers -> Key Position Embedding
Query Position Embedding Construction
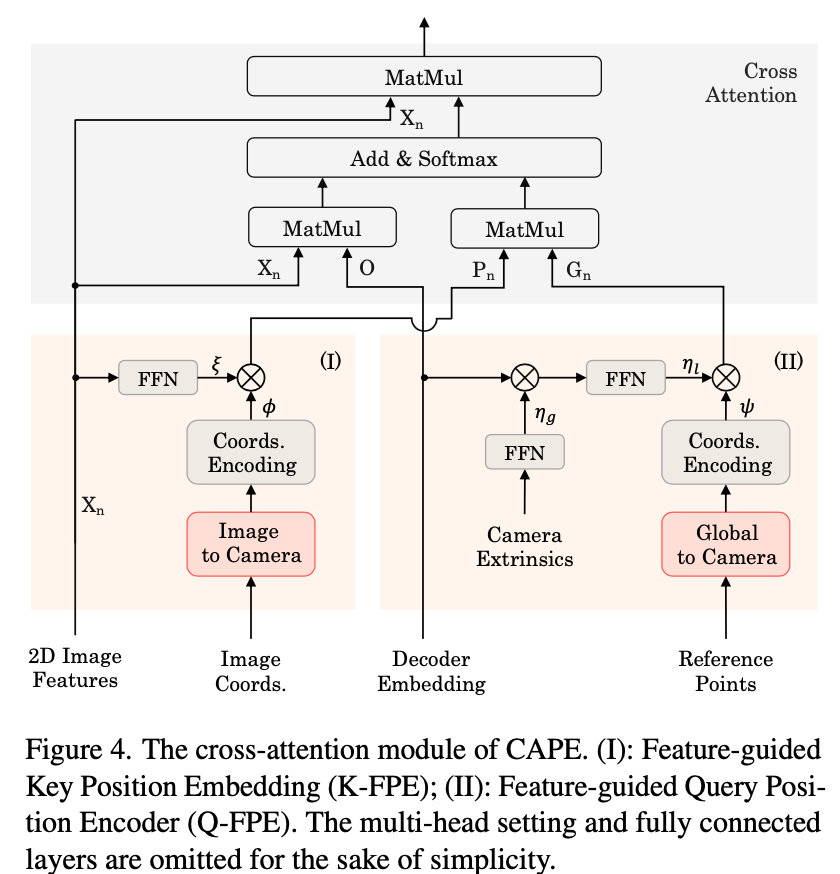
Decoder Embedding与Reference Points均为learnable,为别代表global系下position embedding与local系下的position embedding。使用bilateral attention来融合两种坐标系的embedding。
什么是bilateral attention mechanism?具体实现上与常规的attention有什么区别
双向注意机制(Bilateral Attention Mechanism)是一种增强型的注意力机制,旨在更全面地捕捉输入数据的特征。与常规注意力机制的不同之处在于双向注意同时处理数据的两个维度或方向。常规注意力机制
在常规注意力机制中,通常关注一个单一维度的信息。比如在自然语言处理中,关注每个单词的上下文相关性,实现方式常见于Transformer模型中的自注意力(Self-Attention)。
双向注意机制的区别
双向注意机制扩展了这一概念,涉及以下实现特点:
多维度信息捕捉:
同时关注两个不同维度的信息。例如,在图像处理中,既关注空间信息(位置)又关注通道信息(特征类型),确保重要的空间位置和通道特征都被有效捕捉。
信息融合:
将来自不同维度的信息进行融合,以便更全面地表示输入数据。
可能采用不同的加权方式或融合策略来实现这一点。
增强特征表达:
通过双向信息的交互,提高模型在复杂任务上的表现。
实现上的差异
计算过程:双向注意机制通常会引入额外的计算步骤来处理不同方向的信息,并可能涉及更复杂的合并或加权策略。
模型架构:相比于单一维度的注意力,双向注意可能需要在模型结构中引入新的模块或层来支持多维度交互。
通过这些改进,双向注意机制能够比常规注意力机制更有效地捕捉复杂数据中的重要特征,适用于需要捕捉多维度信息的任务。
Key/Query Position Embedding两者结合关系参考下图
temporal modeling

Q: ego-motion matrix是学出来的,还是系统输入的?
系统输入的,参考下文
Different from previous methods that either warp the explicit BEV features using ego-motion [11, 19] or encode the ego-motion into the position embedding [25], we adopt separated sets of object queries for each frame and encode the ego-motion to fuse the queries.
Q:与PETR有主要区别?
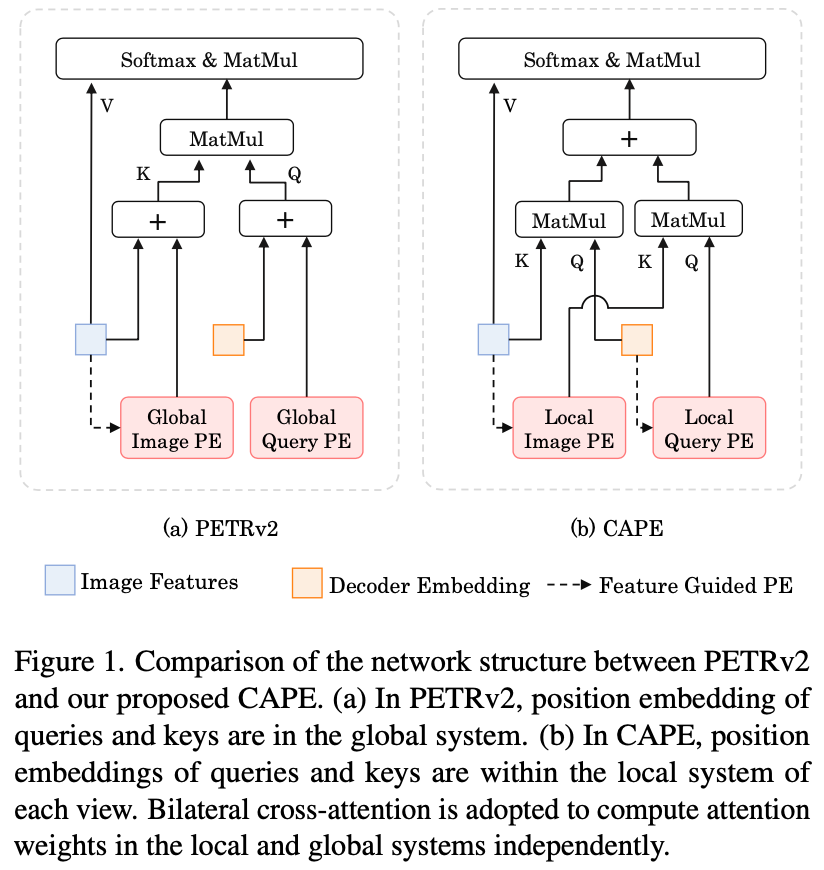
- PETR的PE与Query PE都是在global space在预处理时就使用完毕(相机参数使用在图2D点->Camera3D点->世界3D点的转换过程)
- CAPE是global与local PE混合使用的(主打local PE),相机内参在Key PE的时候使用,外参在Query PE的时候使用。
![]()
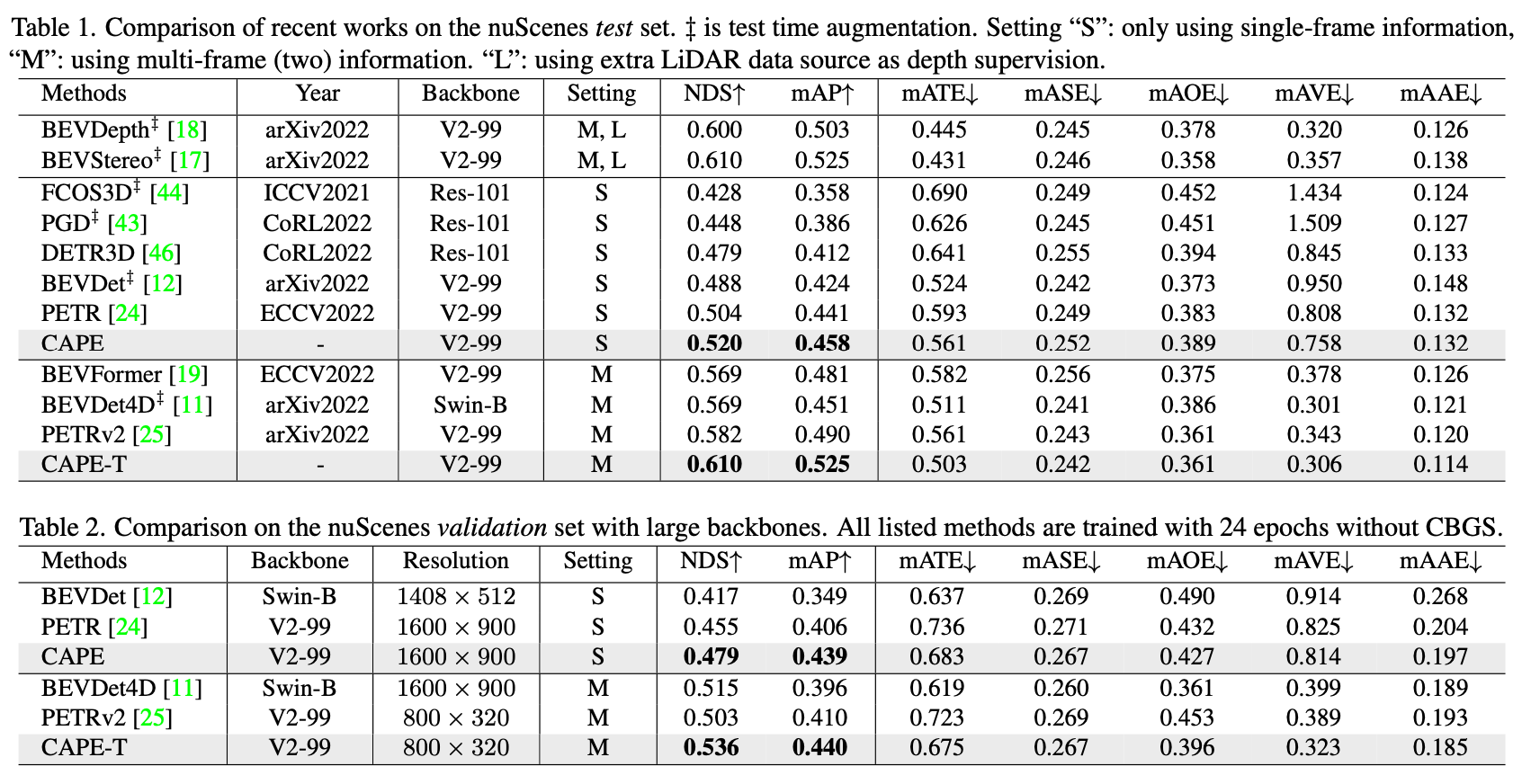
Experiment
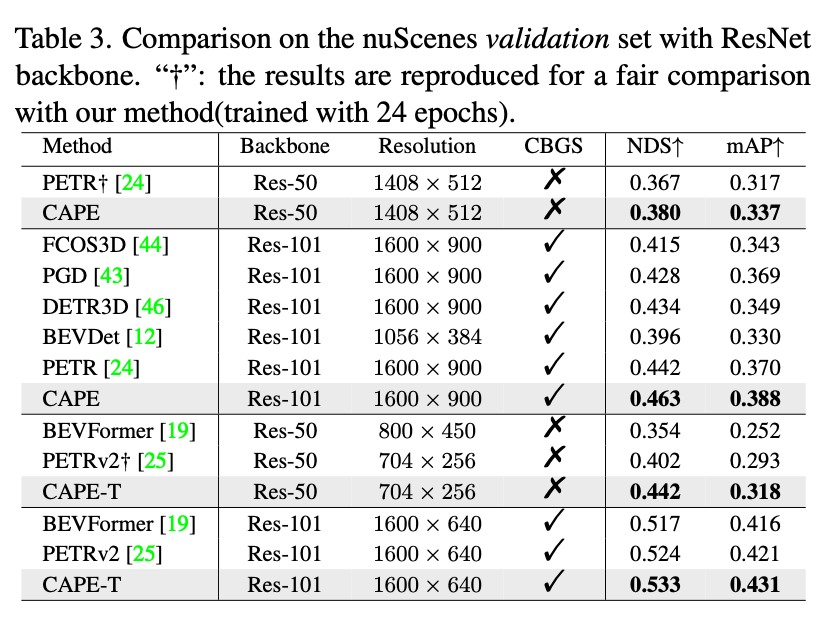
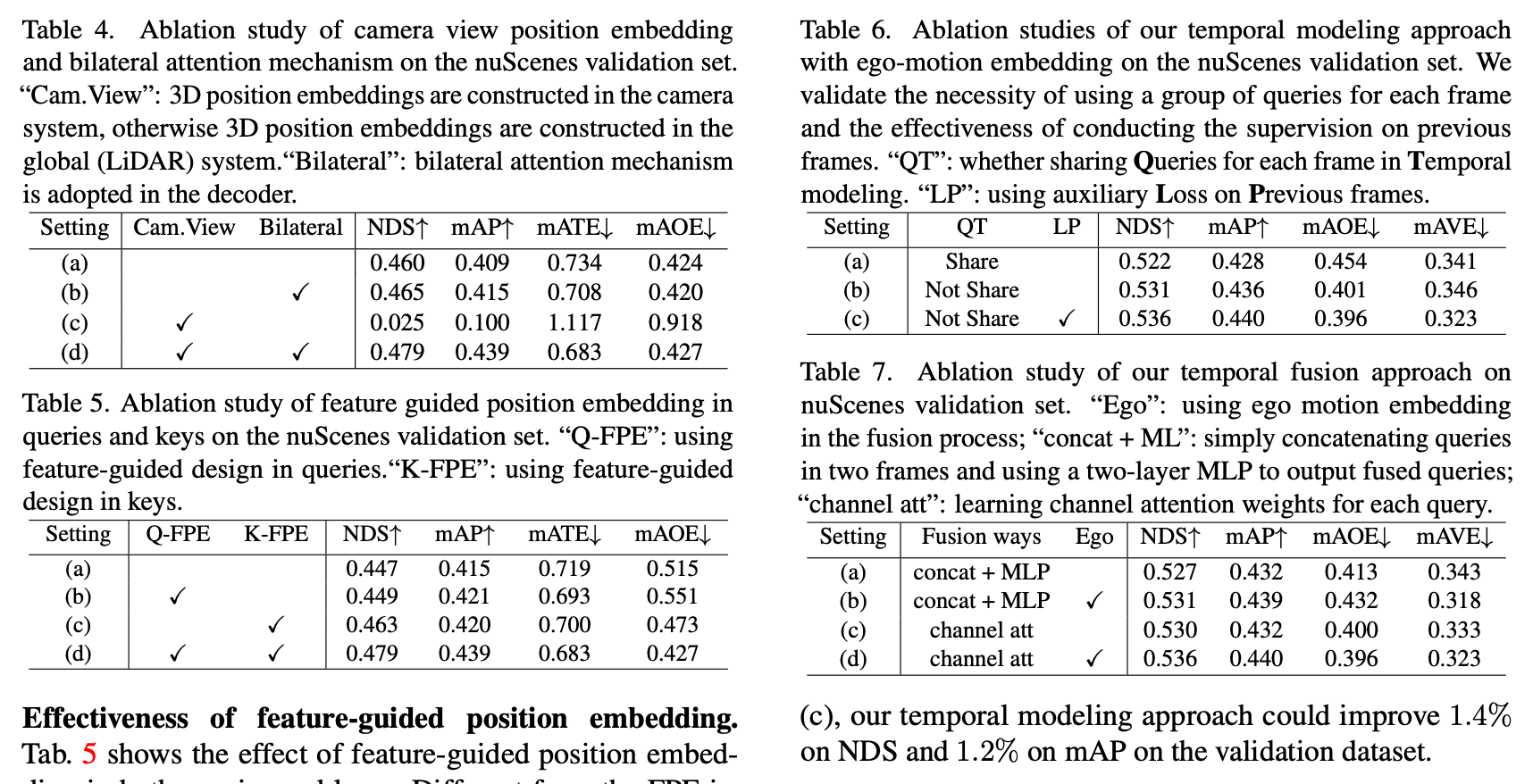
总结与发散
因为Key PE与Query PE都转到了Camera View下,所以称为CAPE(CAmera view Position Embedding)。
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18429785

 浙公网安备 33010602011771号
浙公网安备 33010602011771号