
[Paper Reading] Sapiens: Foundation for Human Vision Models
名称
link
时间:24.08
机构:Meta RealityLabs
TL;DR
放出一个human-centric视觉任务的fundation model,该模型在3亿样本(Humans-300M)上进行无监督预训练,实验证明在human-centric视觉任务(2d pose估计/深度估计/body-part-seg等)效果相对于没有预训练有明显提升。
Method
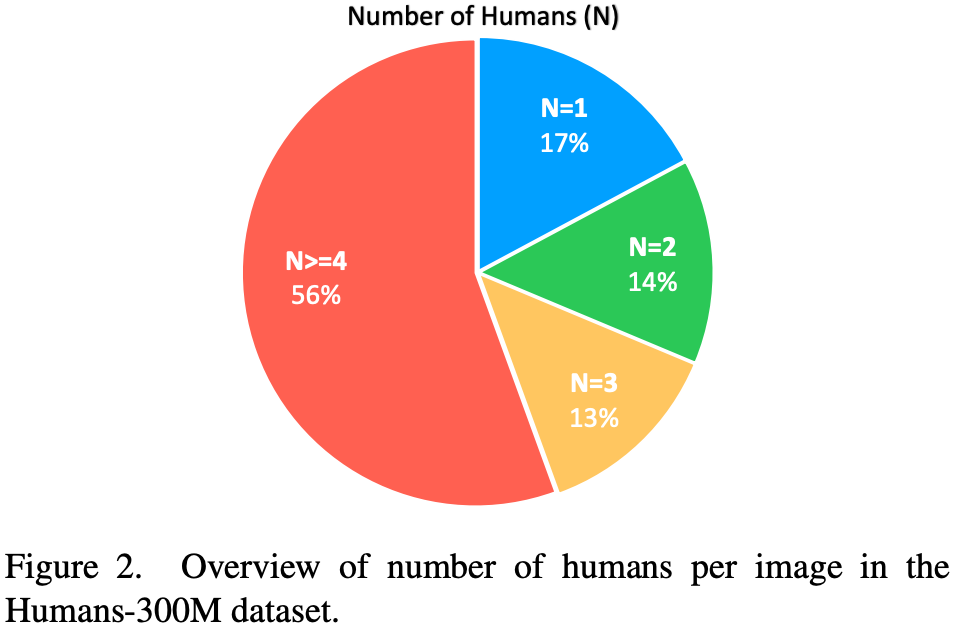
Human300M数据集
收集1B数据,使用Human Detector过滤留下高分样本。第一人称视角数据。大多数据图像中为多人样本。
Pretrain
MAE
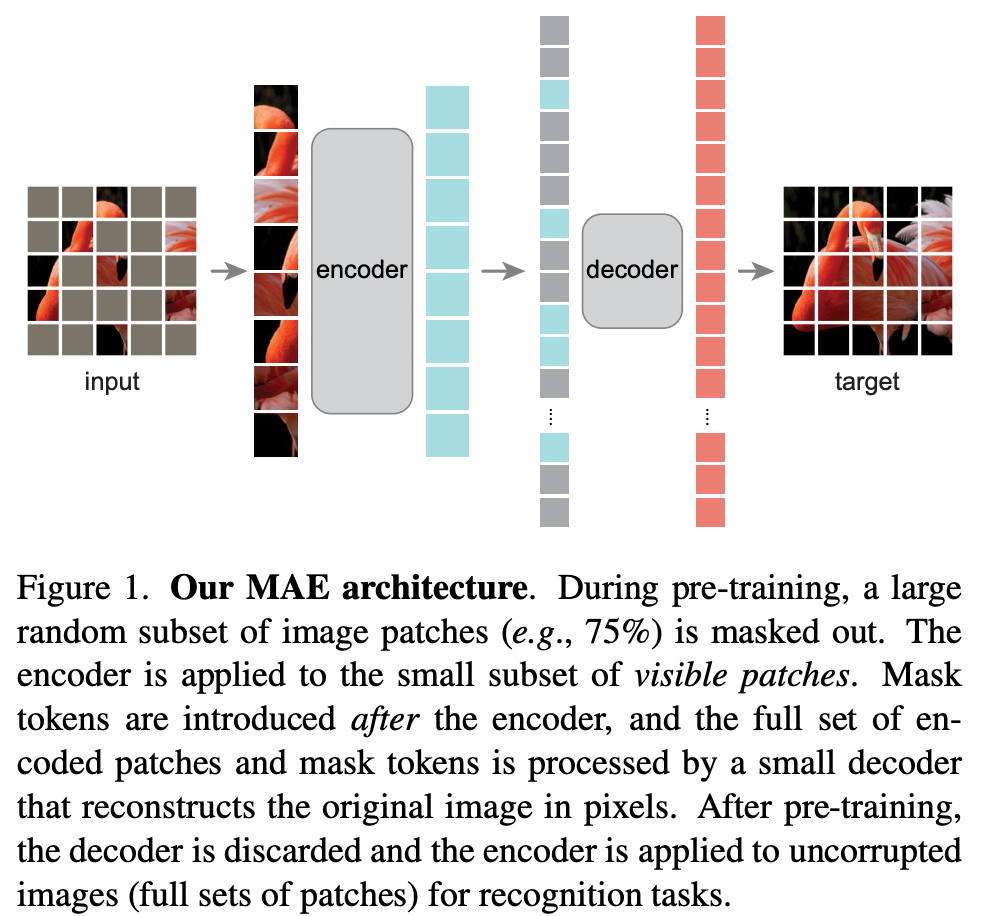
Pretext-Task上效果

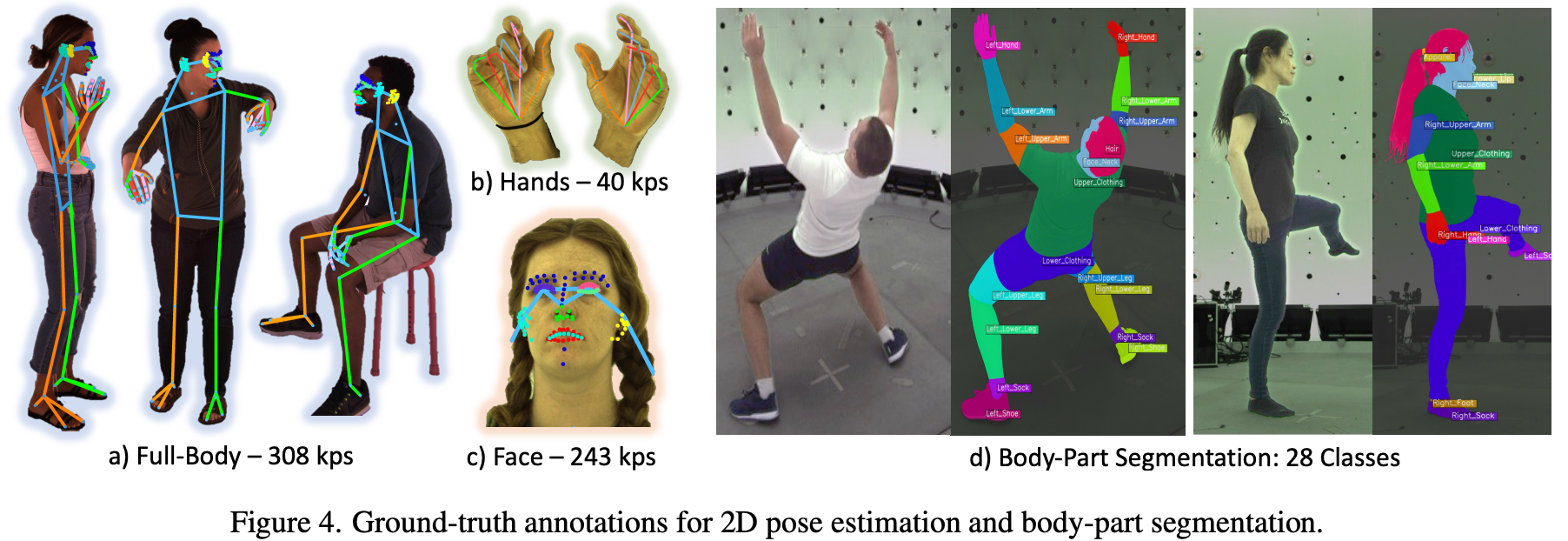
下游任务
使用少量高清数据进行Finetune,每类任务用比较经典的方法,例如 PoseEstimation使用ViTPose。

Q&A
数据集与训练方法是否开源?
有没有证明 linear eval的效果
Experiment
与其它数据预训练对比
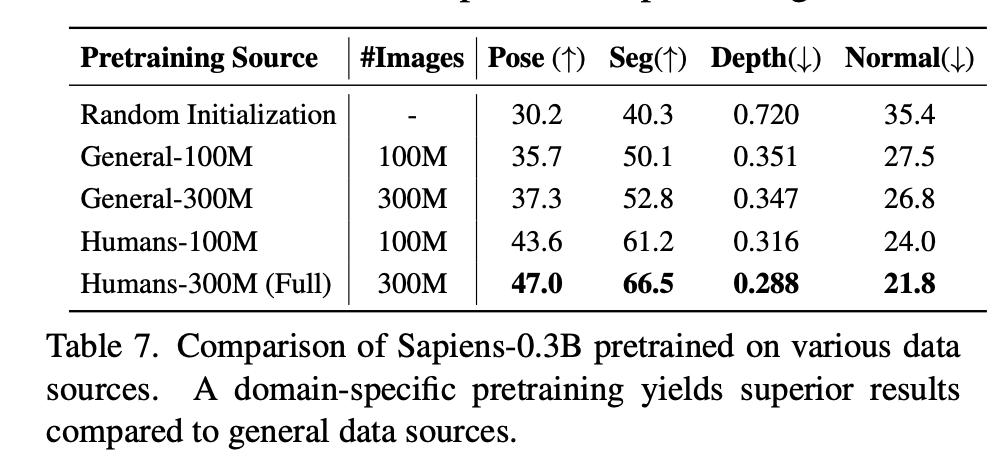
不同数据量预训练对于Normal Estimation任务的提升

总结与发散
数据量较少时,预训练还是有比较大作用的。
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18397126

 浙公网安备 33010602011771号
浙公网安备 33010602011771号