[Paper Reading] Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
link
时间:24.08
机构:Waymo & University of Southern California
TL;DR
提出一种使用混合模态token来训练transformer,名为transfusion,是一种生成式AI模型。主要工作使用了2T的tokens结合语言模型的next token prediction以及diffusion训练了一个7B的模型,实验证明在图像与文本领域都有很好的效果。
比如,图像生成方面超过DALLE2与SDXL,文本生成达到Llama1的水平。
Method
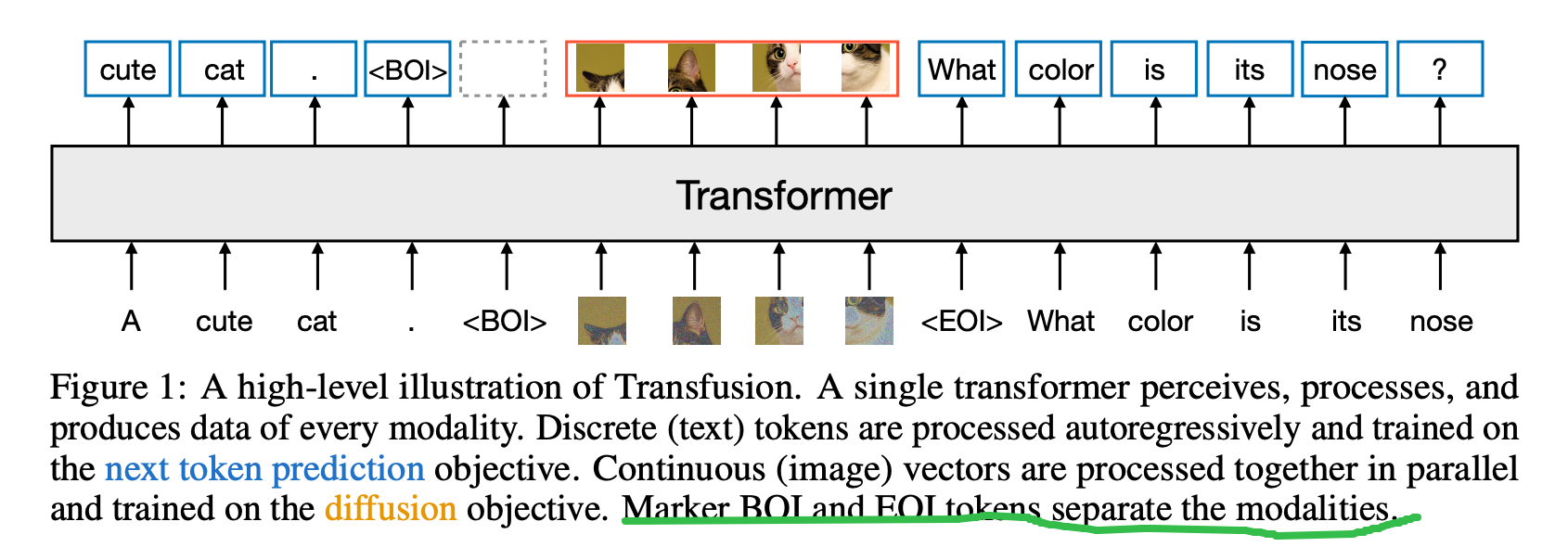
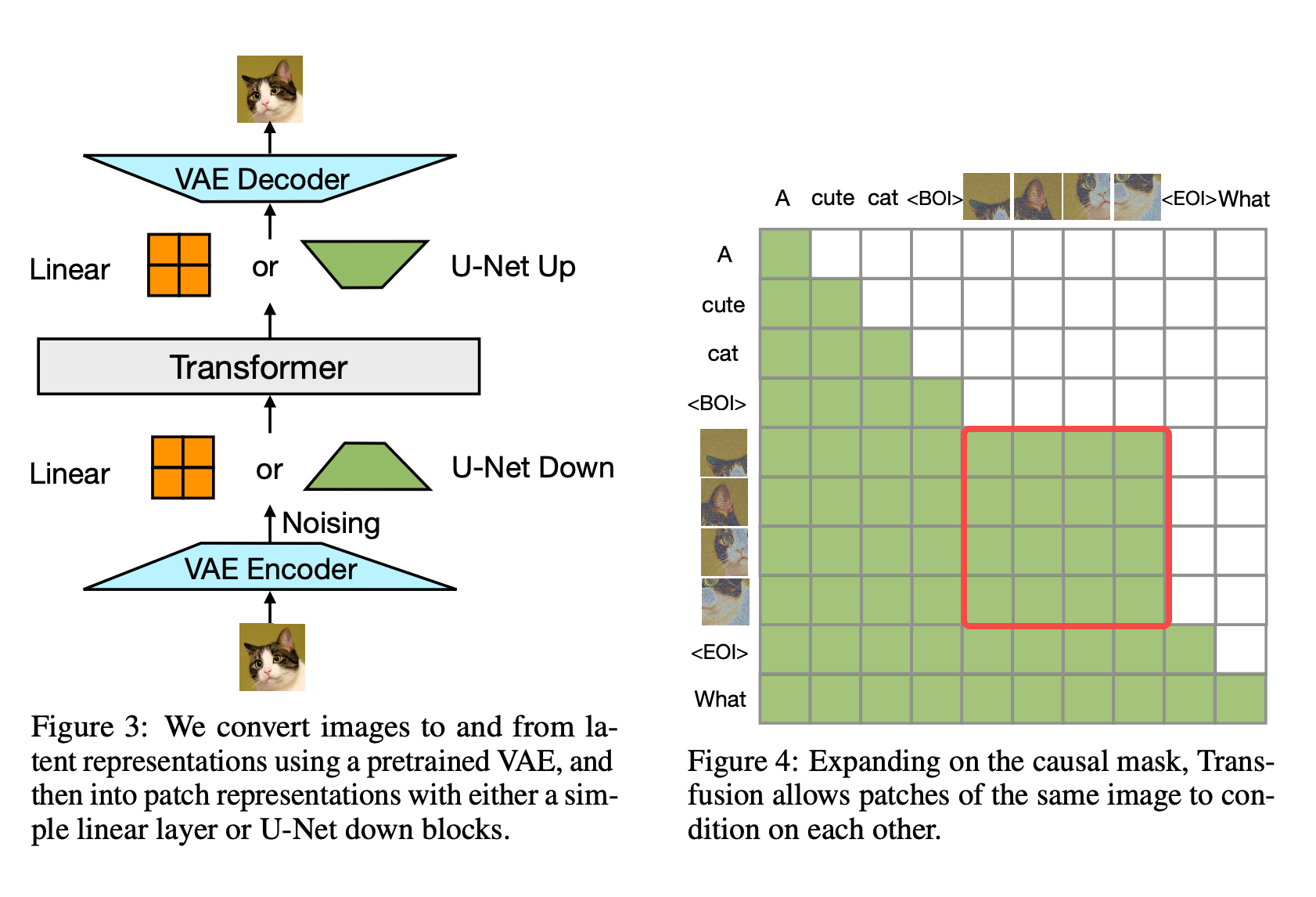
方法解读
- token准备:text模态被tokenize为token,image经过VAE Encoder编码为feature再通过Linear或者UNet提取image token(推测实际用的时候还是保留spatial信息的feature map,再输入diffusion model)。
- Attention Mask:text使用mask将feature token屏蔽,而image token前后不需要屏蔽。推理过程text token部分是通过Auto-regressive模式逐个预测,而image token使用diffusion模式迭代T次输出后,再进行后续的text token regressive。
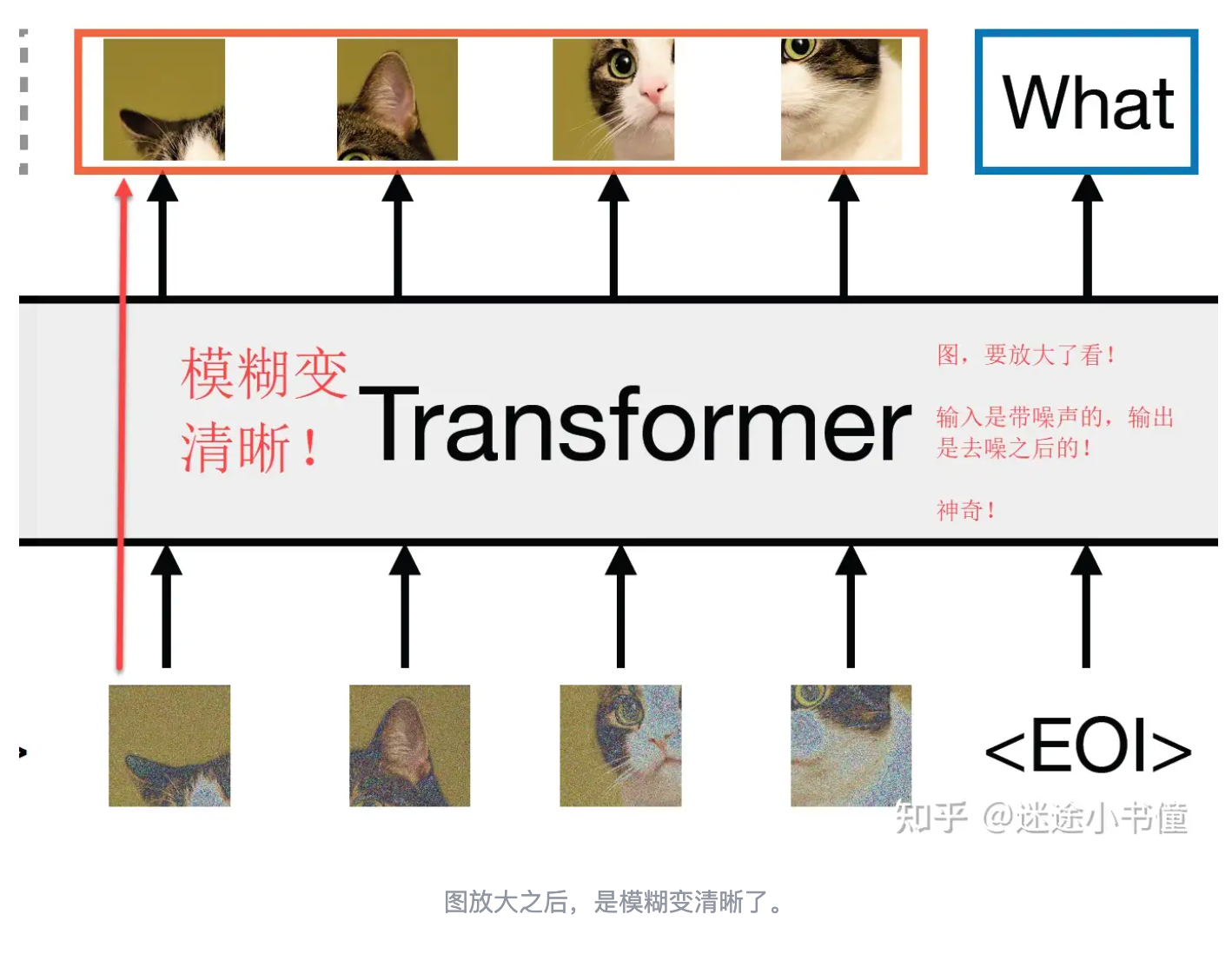
- 多模态Transformer:文本方面不解释了,image feature token经过Transformer是在不断生成噪声并对图像去噪,猜测使用DIT这种Diffusion模型,所以可以和text复用Transformer。参考这篇知乎文章也有可能是利用transformer直接seq2seq预测的(见下图)。
![]()
Loss
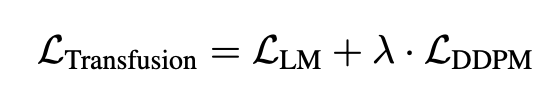
数据
- 2T tokens:1T text tokens,3.5B caption image pairs (1T为1万亿,1B为10亿,所以 1T=1000B)
Experiment
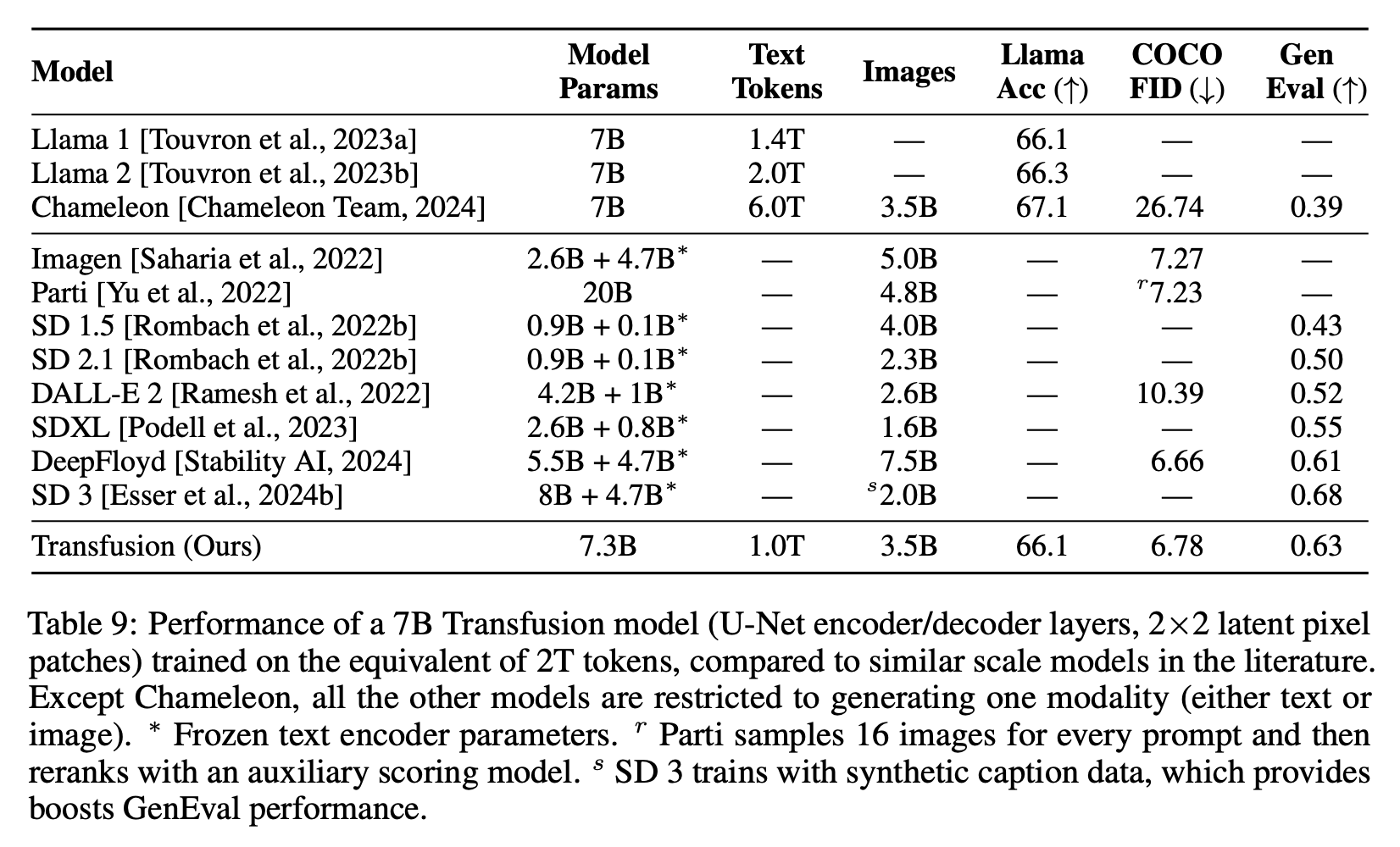
Ablation
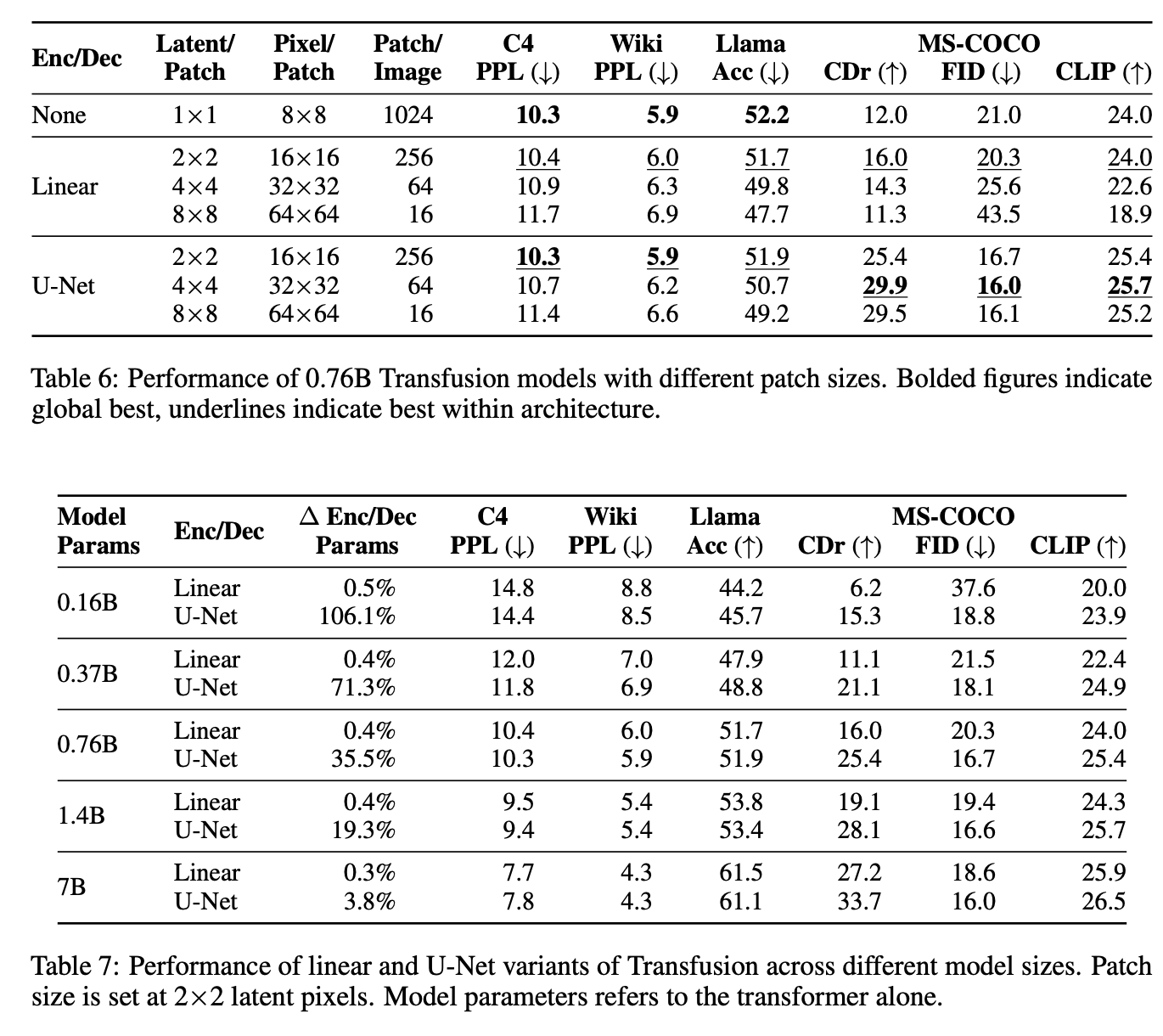
计算量分布

总结与发散
1.方法比较简单,训练出一个兼容两种token的Transformer可能比较难
2.两种模态可以一起输入后,应用场景会比较大提升
3.text数据量以及多样性应该比caption image pairs好得多
相关链接
https://zhuanlan.zhihu.com/p/716378337
https://www.zhihu.com/question/665151133/answer/3606964055
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18384838

 浙公网安备 33010602011771号
浙公网安备 33010602011771号