[Paper Reading] One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer
One-Stage 3D Whole-Body Mesh Recovery with Component Aware Transformer
link
时间:CVPR2023
机构:粤港澳大湾区数字经济研究院(IDEA) && 清华大学深圳国际研究生院
TL;DR
使用一个纯Transformer结构模型(名为OSX)直接预测Body/Hand/Face的参数,避免了之前各模型分开预测后融合复杂的问题。
Method
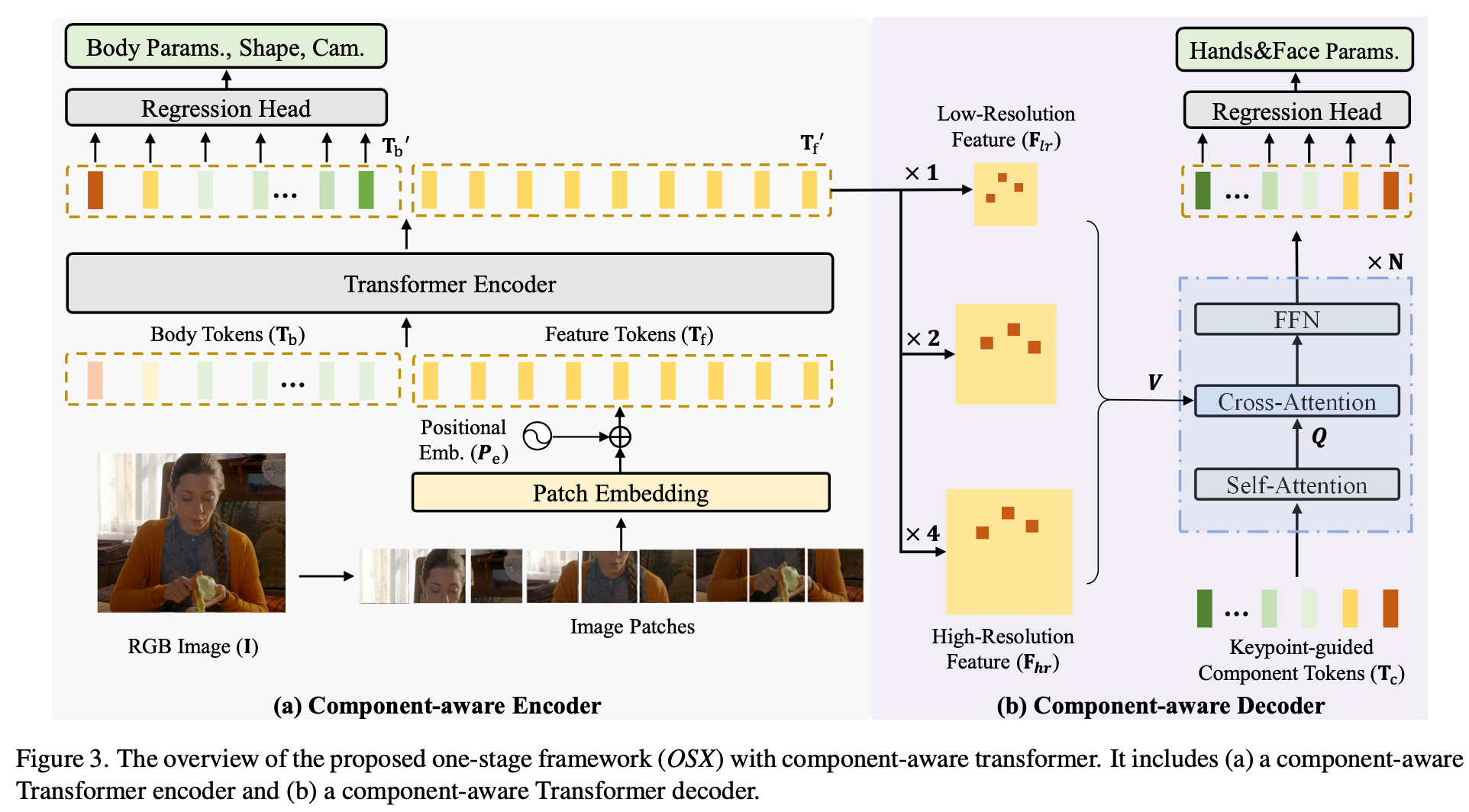
Component-aware Encoder
将初始化的Body Tokens与Vit抽取的image feature sequence整体作为input sequence,取过多层Transformer Encoder预测sequence,其中body token的成分增加regression head用来预测身体参数,其中image feature的成分\(T_f^′\) 作为全局特征输入给Component-aware Decoder。
Component-aware Decoder
将Global feature \(T_f^′\) reshape回spacial维度,并Deconv出多尺度feature \(T_{hr}\),利用\(T_f^′\)预测出hand_box与face_box,使用ROI Align在多尺度feature上分别crop出hand与face特征。
Keypoint-guided deformable attention decoder:input query是由[reference keypoint feature, pose positional embedding, and learnable embeddings]三部分累加而成,其中reference keypoints是由\(T_f^′\) 特征预测出来的初始值。
Decoder中的cross attention是一个deformable的版本,让query提取特征图中keypoints附近的特征(我的理解是避免全局范围都要query计算量太大)。
Loss
smplx部分Loss包括身体、手、脸的参数Loss,L_{kpts3D}文中没有详细说从哪里预测的。
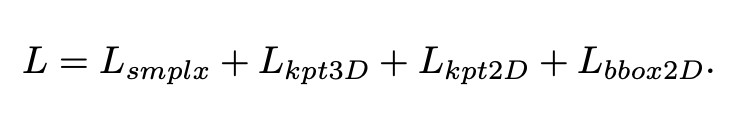
Code
https://github.com/IDEA-Research/OSX
Experiment
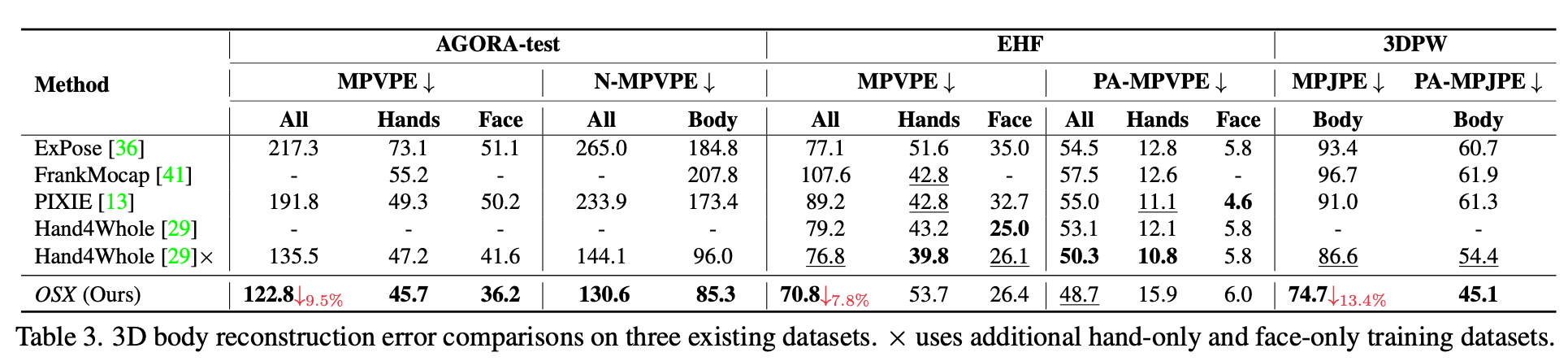
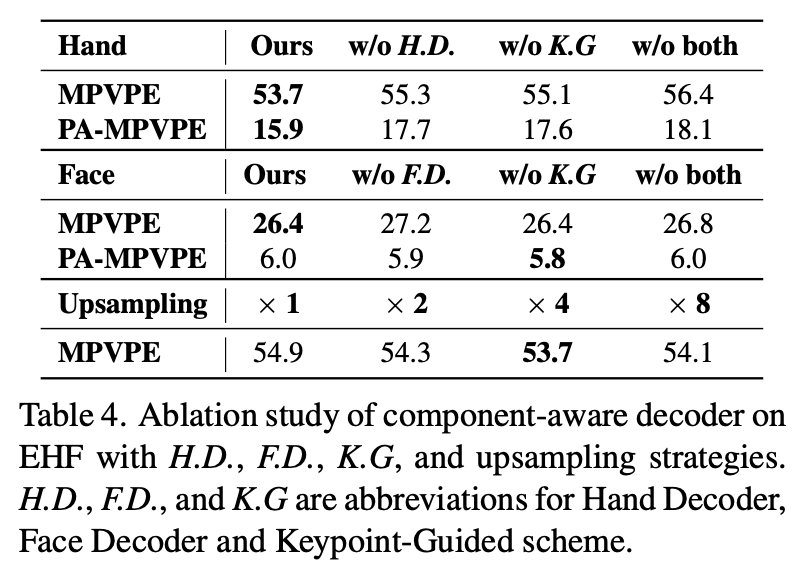
Ablation
总结与发散
无
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18383611

 浙公网安备 33010602011771号
浙公网安备 33010602011771号