[Paper Reading] ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models
link
时间:23.11
机构:Standford
TL;DR
提出ControlNet算法模型,用来给一个预训练好的text2image的diffusion model增加空间条件控制信息。作者尝试使用5w-1M的edges/depth/segmentation/pose等信息训练ControlNet,都能得到比较好的生成效果。为下游文生图使用者提供了极大的便利。
Method
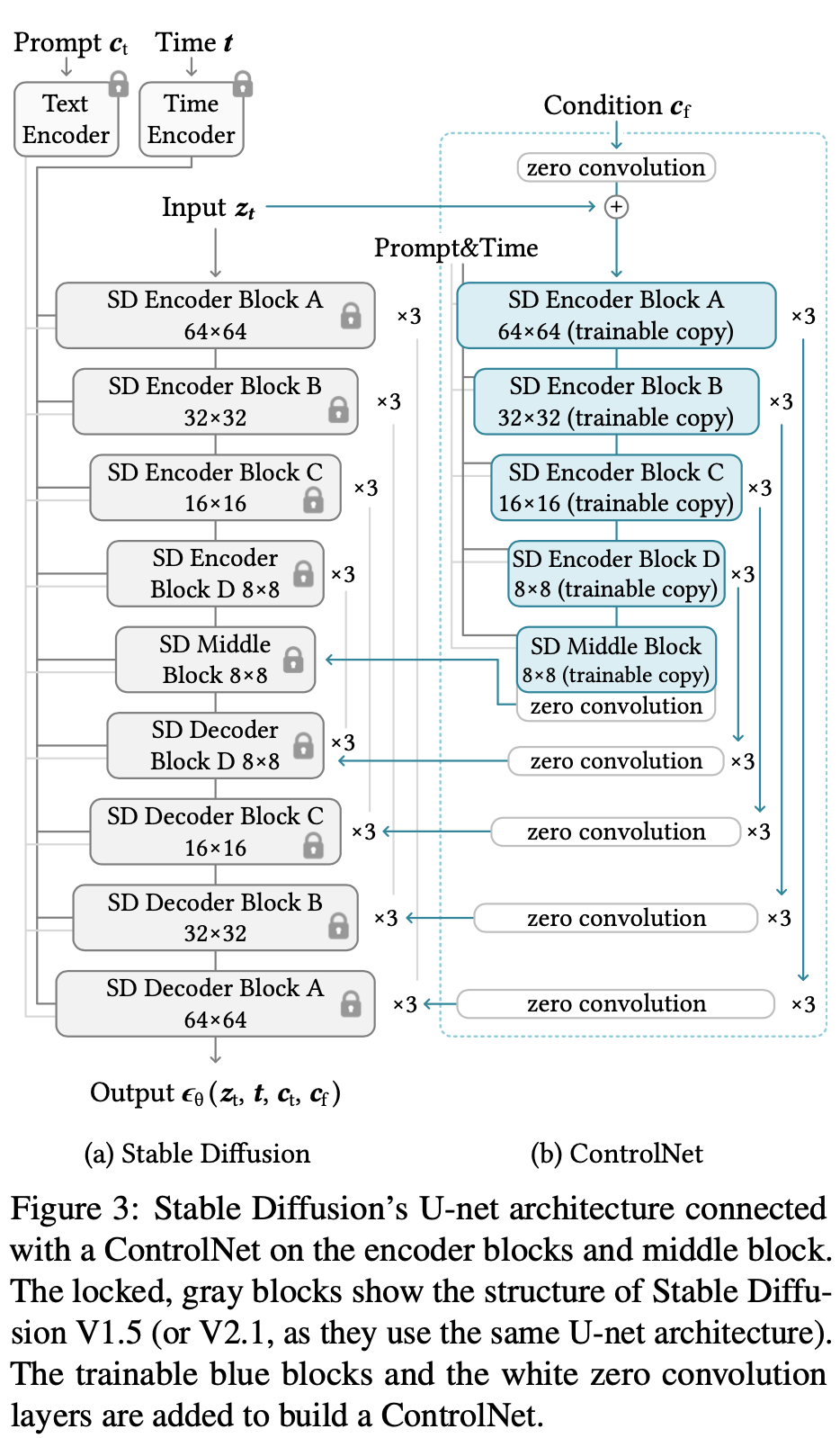
- ZeroConv
FreezeNet与ControlNet模型是在Decoder部分融合特征的,ControlNet Decoder都是从ZeroConv初始化的,根据下面公式来看,从ControlNet连入FreezeNet的特征一开始是全零所以融合到Freeze模型上不影响原始效果。
![]()
- 这么设计的好处:
效果方面:
a) 保留了原始Encoder的参数。b) Decoder是ZeroConv相当于让ControlNet逐步学习参与进来。
性能方面:FreezeNet不需要backward,提升速度与降低显存
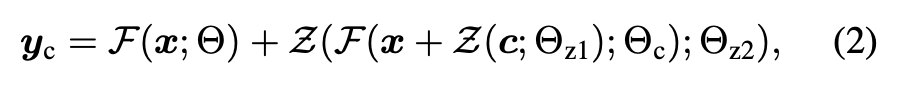
As tested on a single NVIDIA A100 PCIE 40GB, optimizing Stable Diffusion with Control- Net requires only about 23% more GPU memory and 34% more time in each training iteration, compared to optimizing Stable Diffusion without ControlNet.
- Condition \(c_f\)
将depth/pose/edge图,通过4层stride=2的可学习卷积抽取出的特征 - Q:ZeroConv如何反传梯度?
根据\(y=wx + b\),只要x不为0(输入x是从ControlNet Encoder抽取出来的特征),就可以得到y反传到w的非0梯度,那么经过一个iteration的更新之后,zero_conv的参数就会更新为非0。
CodeReading
config: https://github.com/lllyasviel/ControlNet/blob/main/models/cldm_v21.yaml
从ControlNet相对于LDM架构图变化来看,主要区别:a) LDM中UNet被copy出一份作为ControlNet,并将原UNet完全Freeze住;b) 新UNet(称为ControlNet)的前4个stage + middle stage是可学习的,Decode对应后面Stage为ZeroConv;c) ControlNet输出特征会融合至原UNet中;
从config yaml中来看,主要多了ControlLDM、ControlNet以及ControlledUnetModel三个模型。其中,ControlLDM是原来LatentDiffusion的位置,里面包裹了ControlledUnetModel(被Freeze的原UNet,但能融合control特征)、ControlNet(新UNet用来encode控制特征)
ControlLDM
继承自原LatentDiffusion,额外定义ControlNet,重载apply_model
def apply_model(self, x_noisy, t, cond, *args, **kwargs):
assert isinstance(cond, dict)
diffusion_model = self.model.diffusion_model
cond_txt = torch.cat(cond['c_crossattn'], 1)
# controlnet抽取control特征
control = self.control_model(x=x_noisy, hint=torch.cat(cond['c_concat'], 1), timesteps=t, context=cond_txt)
control = [c * scale for c, scale in zip(control, self.control_scales)]
# control特征联同x_noisy、timestamps及cond特征一起输入LDM UNet中
eps = diffusion_model(x=x_noisy, timesteps=t, context=cond_txt, control=control, only_mid_control=self.only_mid_control)
return eps
ControlNet
模型参数加载于SD UNet预训练weights,参见:https://github.com/lllyasviel/ControlNet/blob/main/tool_add_control_sd21.py#L36
与原UNet区别:a) 模型构造函数中将decoder若干stage指定为zeros conv;b) 会将decoder多个stage的特征返回;
def forward(self, x, hint, timesteps, context, **kwargs):
t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
emb = self.time_embed(t_emb)
guided_hint = self.input_hint_block(hint, emb, context)
outs = []
h = x.type(self.dtype)
for module, zero_conv in zip(self.input_blocks, self.zero_convs):
if guided_hint is not None:
h = module(h, emb, context)
h += guided_hint
guided_hint = None
else:
h = module(h, emb, context)
outs.append(zero_conv(h, emb, context))
h = self.middle_block(h, emb, context)
outs.append(self.middle_block_out(h, emb, context))
return outs
ControlledUnetModel
原始UNet的变种,主要差异是可将control特征融合进来。
Experiment
在6133 iters的时候突然收敛了

可以用来生成数据

更多可视化样本

总结与发散
无
相关链接
https://zhuanlan.zhihu.com/p/660924126
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18377021

 浙公网安备 33010602011771号
浙公网安备 33010602011771号