[Paper Reading] Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
link
时间:CVPR2024
机构:马普所 & Saarland Informatics Campus & Google & University of Pennsylvania
TL;DR
使用第一人称RGB单目鱼眼相机进行全身动捕的算法,融合了FisheyeVit & 3D Heatmap & HandTracking & Pose Diffusion等模块。
Method
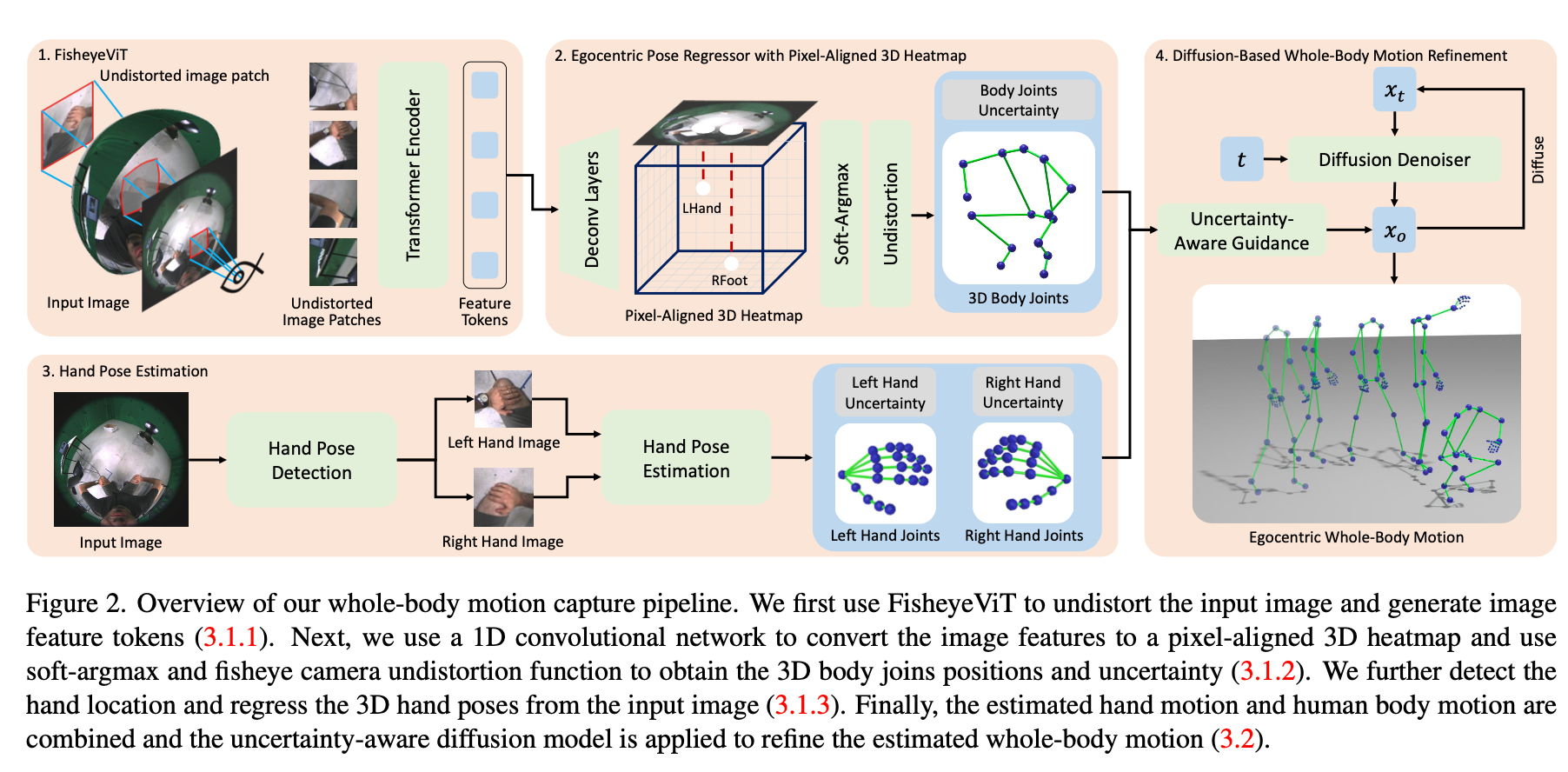
BodyPose
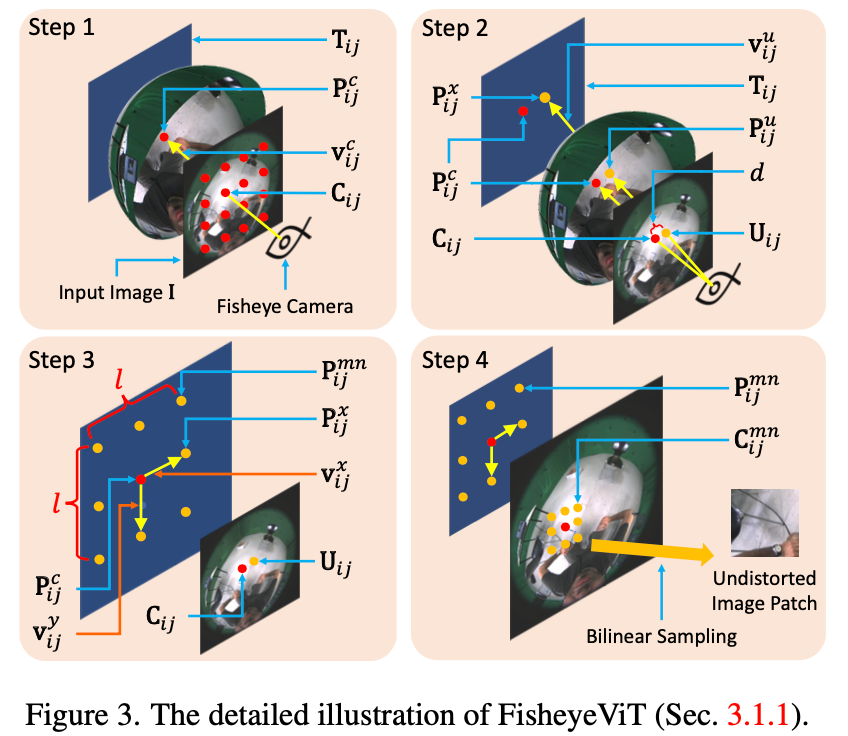
FisheysVit
类似于Perspective Crop的做法,首先根据Vit的PatchSize在鱼眼图上选取一系列中心点阵(如Step1中红点阵)。根据每个中心点,即为每个目标小图中心点,根据小图尺寸lxl去原图中采样点。实际实现过程可用查表法进行加速,同时该模型是在一个非去畸变的模型基础上进行Finetune而来。相关工作可以参考Perspective Crop。

Pixel-Aligned 3D Heatmap
其实就是用3D Heatmap来预测(u, v, d)而非(x, y, z),而uvd转为xyz可使用相机模型来转换。
Q: 预测骨骼点之后,怎么得到SMPL参数?
骨骼点到关节的映射:首先,将预测的骨骼点映射到SMPL模型的关节上。
关节位置的优化:使用优化算法(如非线性最小二乘法)来最小化关节位置和预测骨骼点之间的误差。
SMPL参数提取:SMPL模型的参数包括身体的形状参数(如性别、身高、体重等)和姿态参数(如关节角度)。通过优化过程,可以提取出这些参数。
Egocentric Hand Pose Estimation
Hand Detection使用HRNet直接在鱼眼图上做,Hand Pose Estimation使用Crop出的小图直接预测3D Hand Pose。
Q:HandPose Estimation仅使用小图如何预测全图6DoF?
=> 猜测手腕6DoF是在Body Pose那部分做的,这里的Hand Pose注重手指20DoF的还原。
Diffusion-Based Motion Refinement
将Body Joints与Hand Joints的Uncertainty Score作为Guidance输入Diffusion Model中,以预测出的Joints作为初值迭代t次,得到Refine之后的结果。
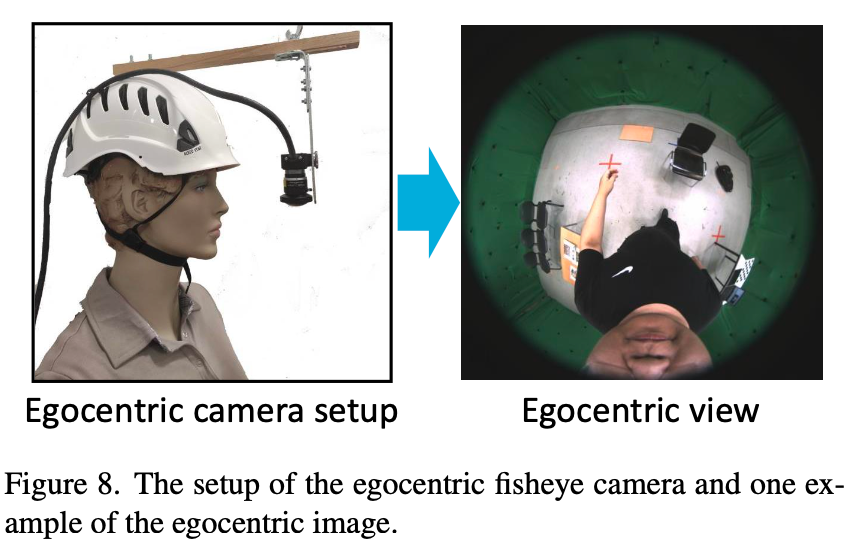
EgoWholeBody Dataset数据集
使用blender仿真而来,Camera的摆放如下图。数据集分为两个部分:Part1共70W帧,具有丰富的Body Pose。Part2共17W帧,注重手部姿态的丰富性。
这里所说的鱼眼图是如下这种摆放所拍出来的。
Code
参考文章pdf以及代码egowholemocap.py,Q1:预测骨骼点之后,怎么得到SMPL参数?Q2:HandPose Estimation仅使用小图如何预测全图6DoF? Q3:模型Loss是什么设计的?Q4:模型输出的shape是什么?
在提供的代码 egowholemocap.py 和相关文件中,我们可以看到这是一个用于人体姿态估计和手部姿态估计的系统。以下是针对您的问题的回答:Q1: 预测骨骼点之后,怎么得到SMPL参数?
在人体姿态估计中,SMPL(Skinned Multi-Person Linear model)是一种流行的3D人体模型,它通过一组参数来描述人体的形态和姿态。预测骨骼点后,通常需要以下步骤来获得SMPL参数:
骨骼点到关节的映射:首先,将预测的骨骼点映射到SMPL模型的关节上。
关节位置的优化:使用优化算法(如非线性最小二乘法)来最小化关节位置和预测骨骼点之间的误差。
SMPL参数提取:SMPL模型的参数包括身体的形状参数(如性别、身高、体重等)和姿态参数(如关节角度)。通过优化过程,可以提取出这些参数。
在代码中,RefineEdgeDiffusionHandsUncertainty 类可能涉及到从预测的骨骼点恢复SMPL参数的过程,但具体实现细节需要查看该类的实现代码。
Q2: HandPose Estimation仅使用小图如何预测全图6DoF?
手部姿态估计(HandPose Estimation)通常需要预测手部的3D姿态,即6自由度(6DoF),包括位置、旋转和缩放。即使使用小图进行预测,也可以通过以下方法来预测全图的姿态:
上下文信息:即使只使用手部的小图,模型仍然可以从中学习到手部的姿态信息,因为手部的关键点和姿态变化具有一定的模式。
多尺度预测:模型可能使用多尺度特征图来捕捉不同级别的细节,从而提高预测的准确性。
回归或分类:手部姿态估计通常采用回归方法直接预测关键点的位置,或者使用分类方法预测关键点之间的相对角度。
在代码中,RefineEdgeDiffusionHandsUncertainty 类可能包含了预测手部姿态的逻辑,但具体如何从一个小图预测全图的6DoF,需要进一步查看该类的实现细节。
Q3: 模型Loss是什么设计的?
模型的损失函数(Loss)设计取决于模型的具体任务和结构。在人体姿态估计中,常见的损失包括:
回归损失(如均方误差MSE):用于直接预测关键点位置的任务。
Heatmap损失:如果模型输出是关键点的热图,可能会使用热图损失来训练模型。
标签平滑损失:在关键点检测中,为了提高模型的泛化能力,可能会使用标签平滑技术。
在代码中,损失函数的设计可能在模型定义的文件中,例如 RefineEdgeDiffusionHandsUncertainty 类的实现文件。需要查看该文件来了解具体的损失函数设计。
Q4: 模型输出的shape是什么?
模型输出的形状(shape)取决于模型的架构和任务。在人体姿态估计中,常见的输出形状包括:
关键点坐标:[N, K, 2] 或 [N, K, 3],其中N是批次大小,K是关键点数量,2或3表示每个关键点的(x, y)坐标或加上分数。
热图:[N, K, H, W],其中H和W是热图的高度和宽度。
在代码中,run_diffusion 函数中的 diffusion_results 变量可能包含了模型的输出。通过查看该函数中的处理逻辑,可以确定模型输出的具体形状。例如,pred_motion_result 变量可能包含了预测的骨骼点或其他相关输出,其形状可以通过查看相关代码来确定。
Experiment
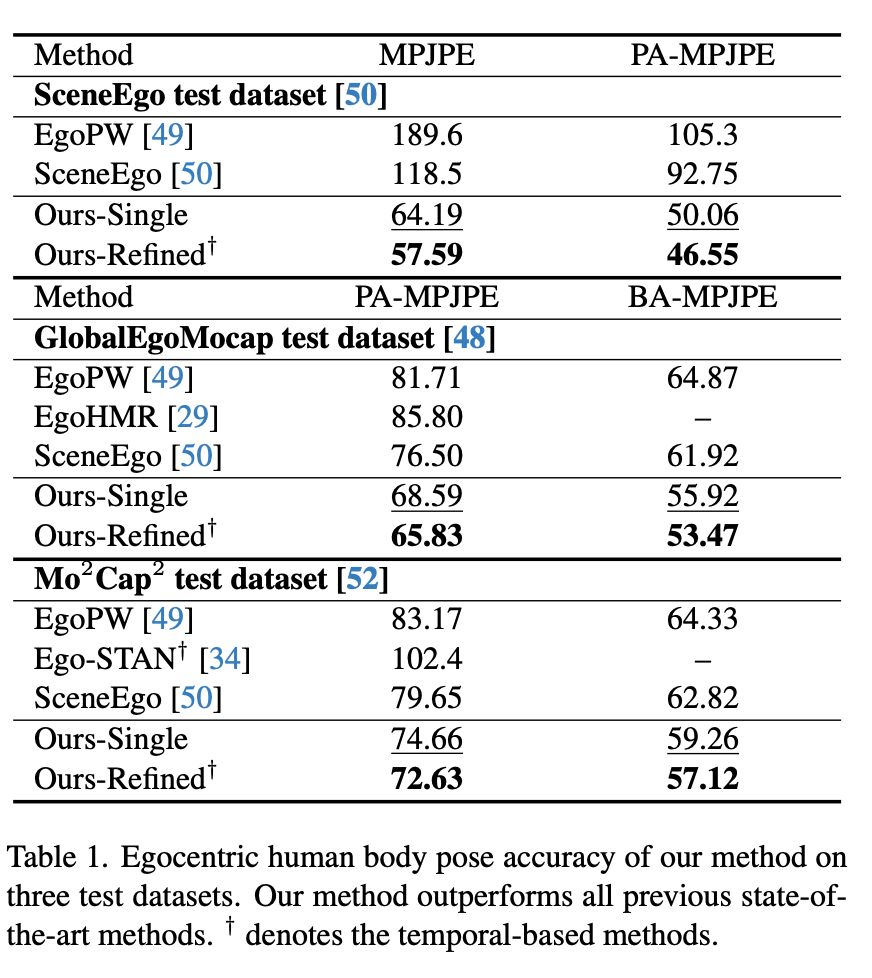
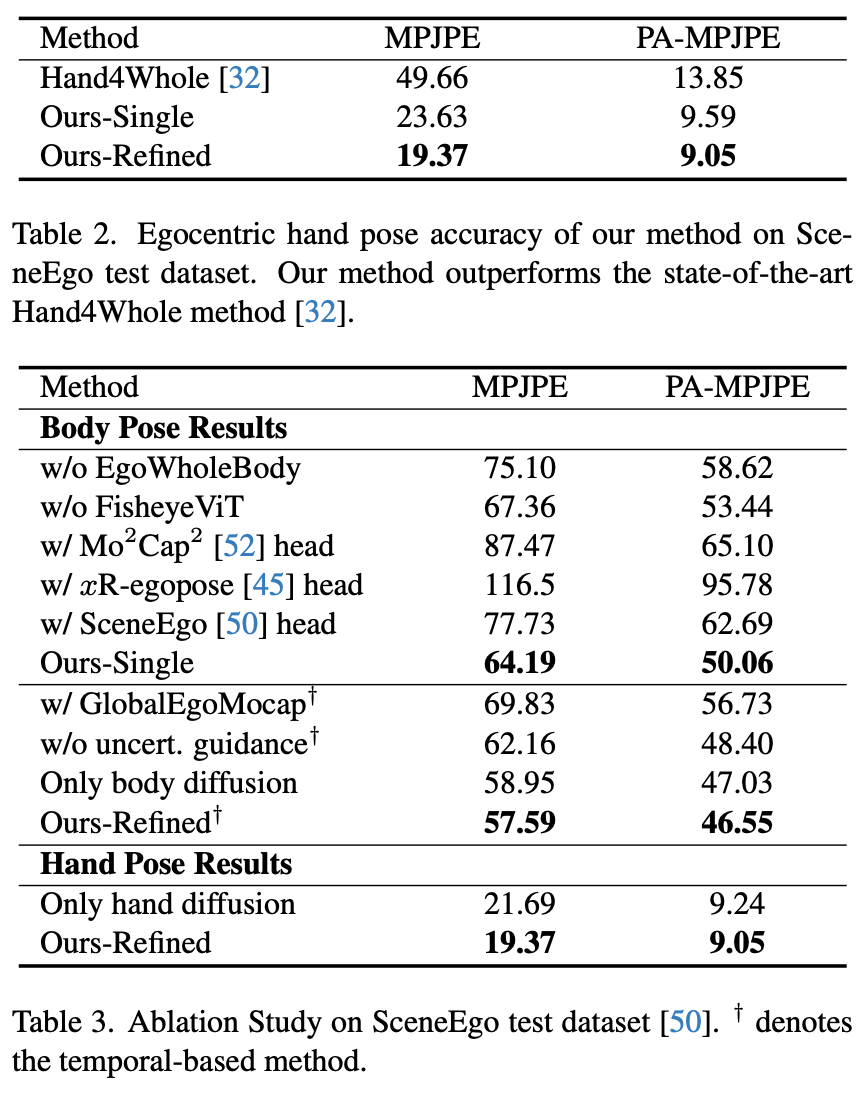
Ablation: 有无Diffusion参考Ours-Single与Ours-Refined之间结果差异。
总结与发散
去畸变Patch结合Vit的思路比较有趣
相关链接
https://people.mpi-inf.mpg.de/~jianwang/projects/egowholemocap/
https://github.com/jianwang-mpi/egowholemocap
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18376825

 浙公网安备 33010602011771号
浙公网安备 33010602011771号