[Paper Reading] Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
名称
Single-to-Dual-View Adaptation for Egocentric 3D Hand Pose Estimation
时间:CVPR2024
机构:The University of Tokyo
TL;DR
多目3D hand pose estimation数据比较难标注,作者核心思路是先训练单目模型,利用无监督的方法适配到双目场景,好处是 a.无需标多目数据; b.可以适应任何相机摆放方式。
Method
初始化R
有单目模型可预测\(J^{v1}\)与\(J^{v2}\),通过这两组点可解出相机Rotation的初始解。
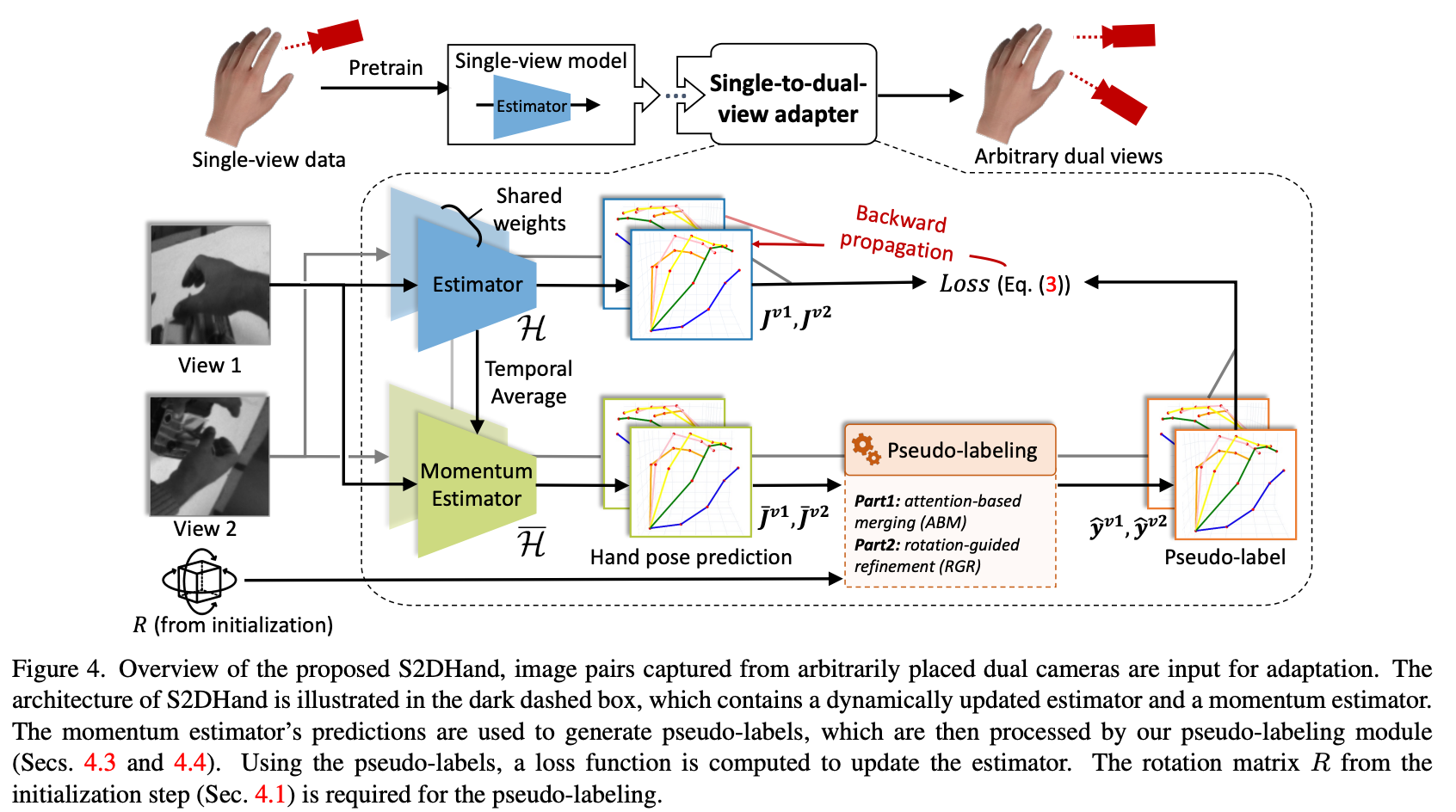
Single-to-dual-view adaptation
使用momentum model输出结果作为伪标签,监督Estimator的学习。
![]()
Pseudo-labeling
attention-based merging
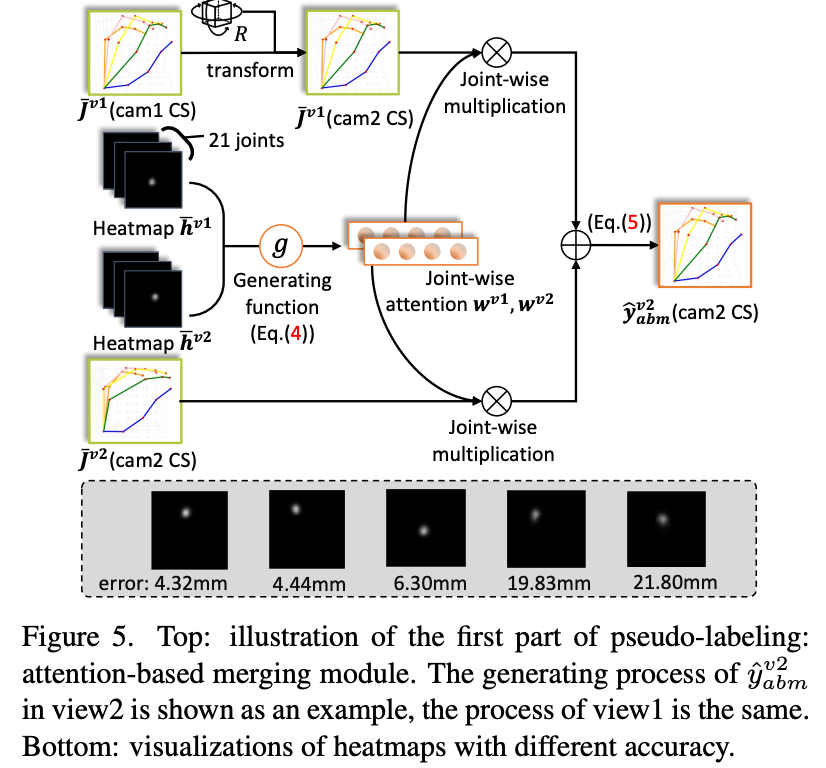
使用heatmap的score作为attention的权重。

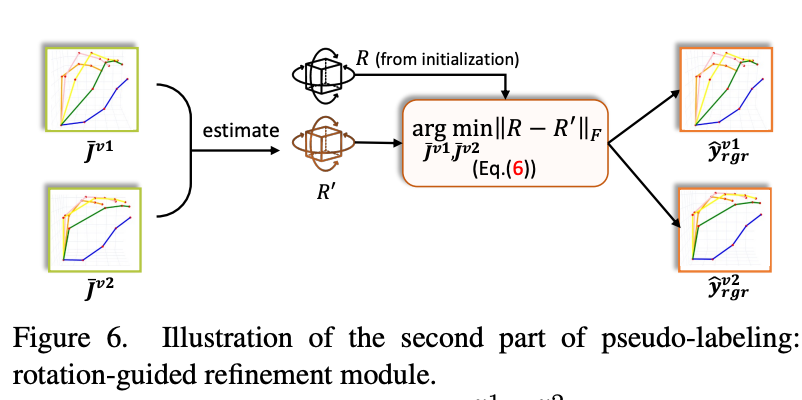
rotation-guided refinement
类似于初始化阶段的作法,用所有训练数据预测\(J^{v1}\)与\(J^{v2}\)来更新R。再使用更新后的R来算出新momentum model预测的Label。
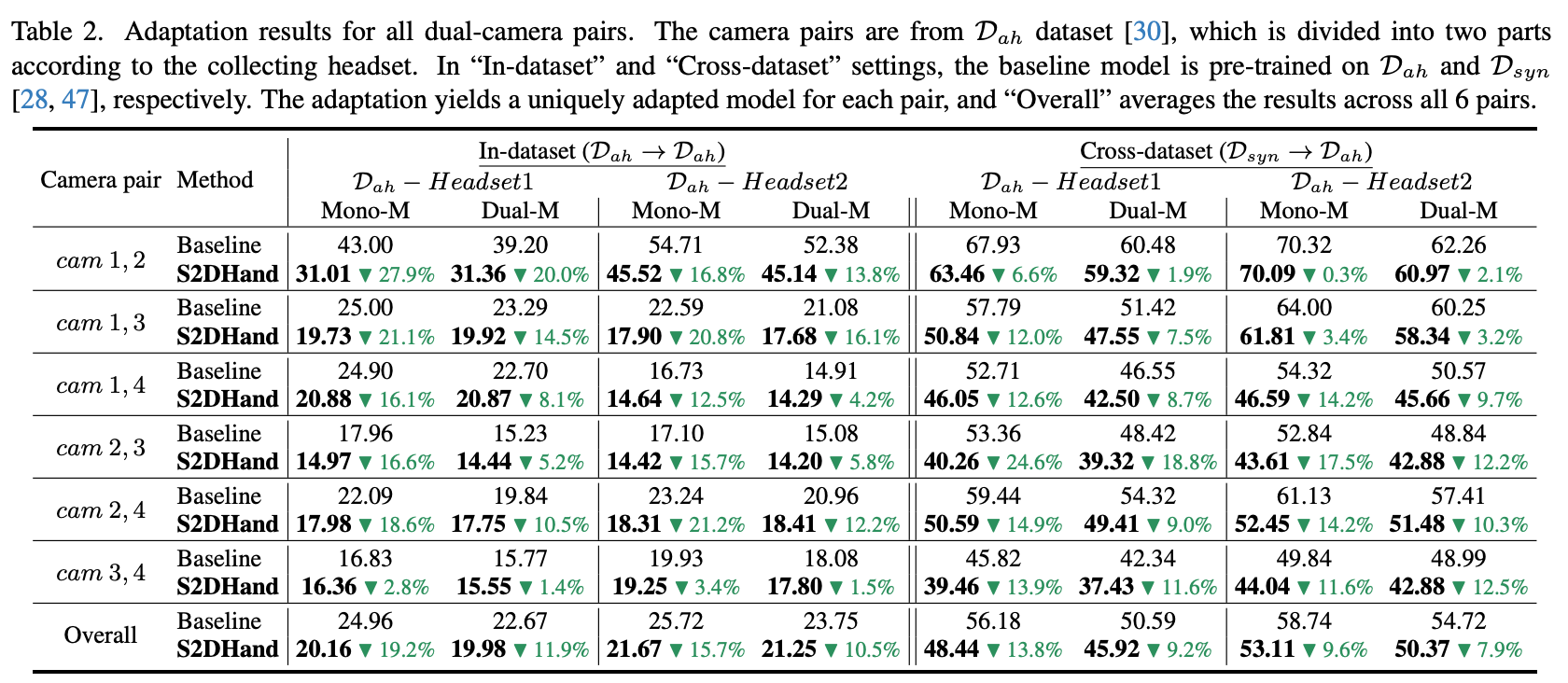
Experiment
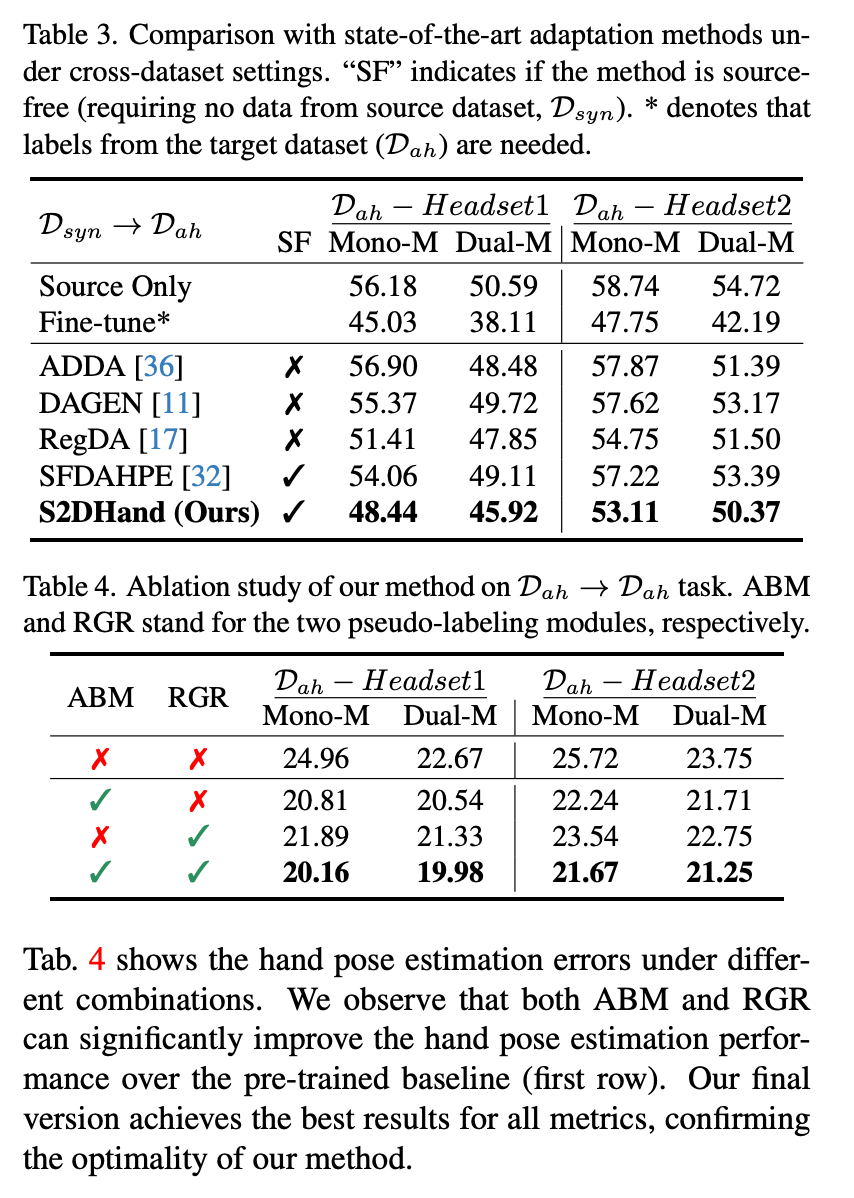
总结与发散
整体思路比较简单,出发点还算不错(1.多目无监督数据使用;2.不使用相机参数,自己适配出来)
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18363398

 浙公网安备 33010602011771号
浙公网安备 33010602011771号