[Paper Reading] DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
link
时间:2021(ICLR)
机构:Sensetime & USTC & CUHK
TL;DR
参考2D Deformable Conv,通过在Reference Point附近增加sample points,将DETR的收敛速度提升10倍,对于小目标效果也更好。
Method
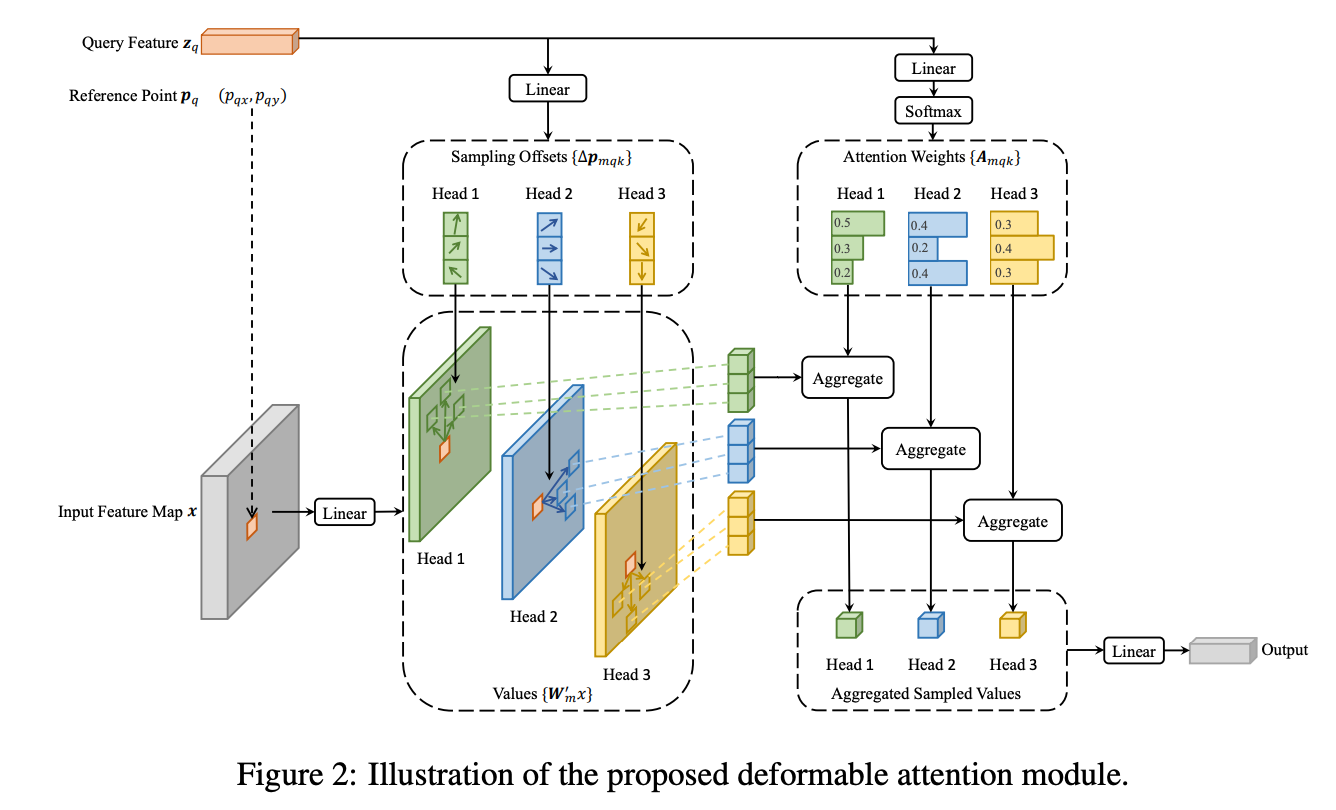
背景知识:参考 DETR
核心思路:
1.Sample Points而非全局Points:每个Query与FeatureMap做Attention过程,仅与FeatureMap部分特征Attention,而不像DETR那样全部spatial feature都Attention,好处是计算量可以明显小。具体做法是Key的维度变为原来的3x倍,其中1x是原来的key(与query乘积softmax之后作为加权因子),剩下的2x用来预测2D的offset
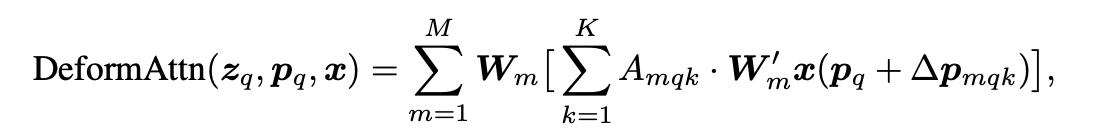
2.Multi-Scale:从CNN Backbone中取出多尺度特征(不使用FPN),各自使用Deformable Attention。
Code: https://github.com/fundamentalvision/Deformable-DETR
Experiment
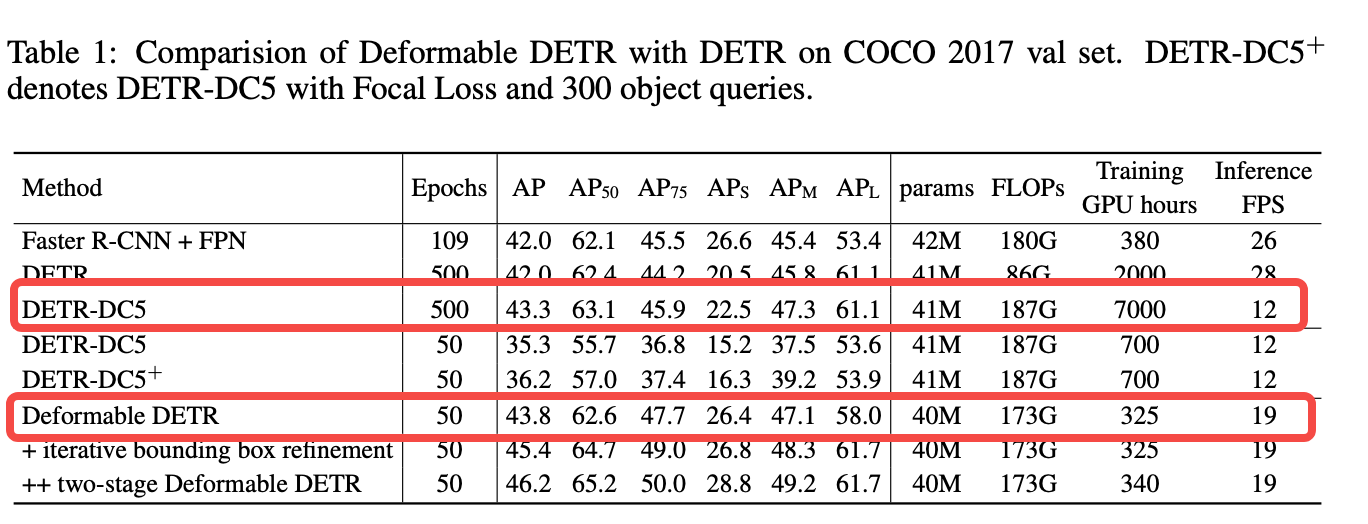
相对于原生DETR变慢,可能是Backbone计算量加太猛了,不过效果提升明显。
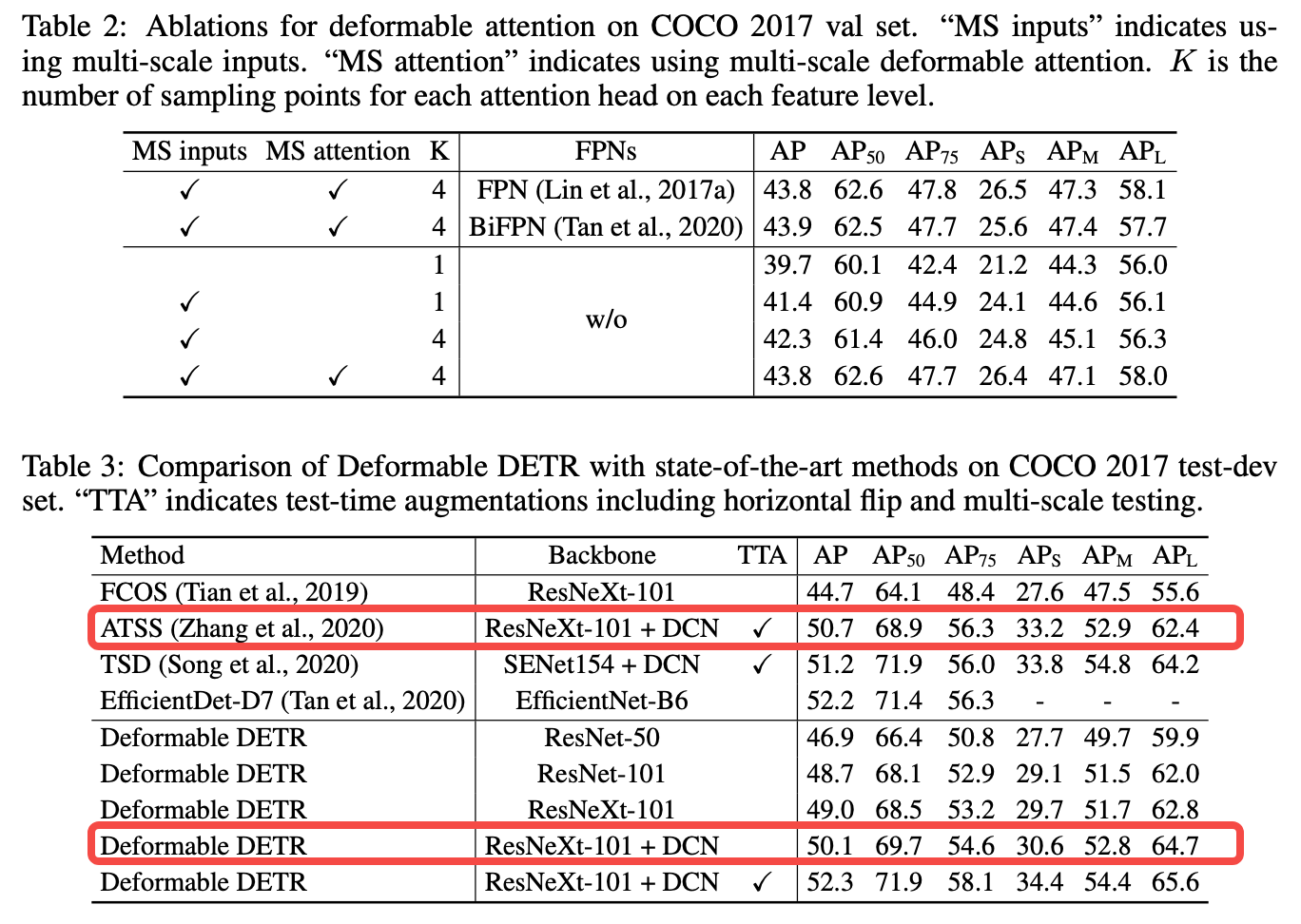
其实相对于传统非E2E的方法(例如 ATSS)也只是基本打平而已
总结与发散
无
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18347504

 浙公网安备 33010602011771号
浙公网安备 33010602011771号