[Paper Reading] DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
DRIVEVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
DriveVLM
时间:24.02
机构:Tsinghua University && Li Auto
TL;DR
当前自动驾驶落地的主要难点是解决各种长尾的复杂路况。本文提出DriveVLM算法,利用VLM来增强智驾的场景描述、场景分析、层级规划能力,同时为了克服VLM计算量大的问题,又提出DriveVLM-Dual的算法,能够混合DriveVLM与传统端侧智驾系统相结合。
Method
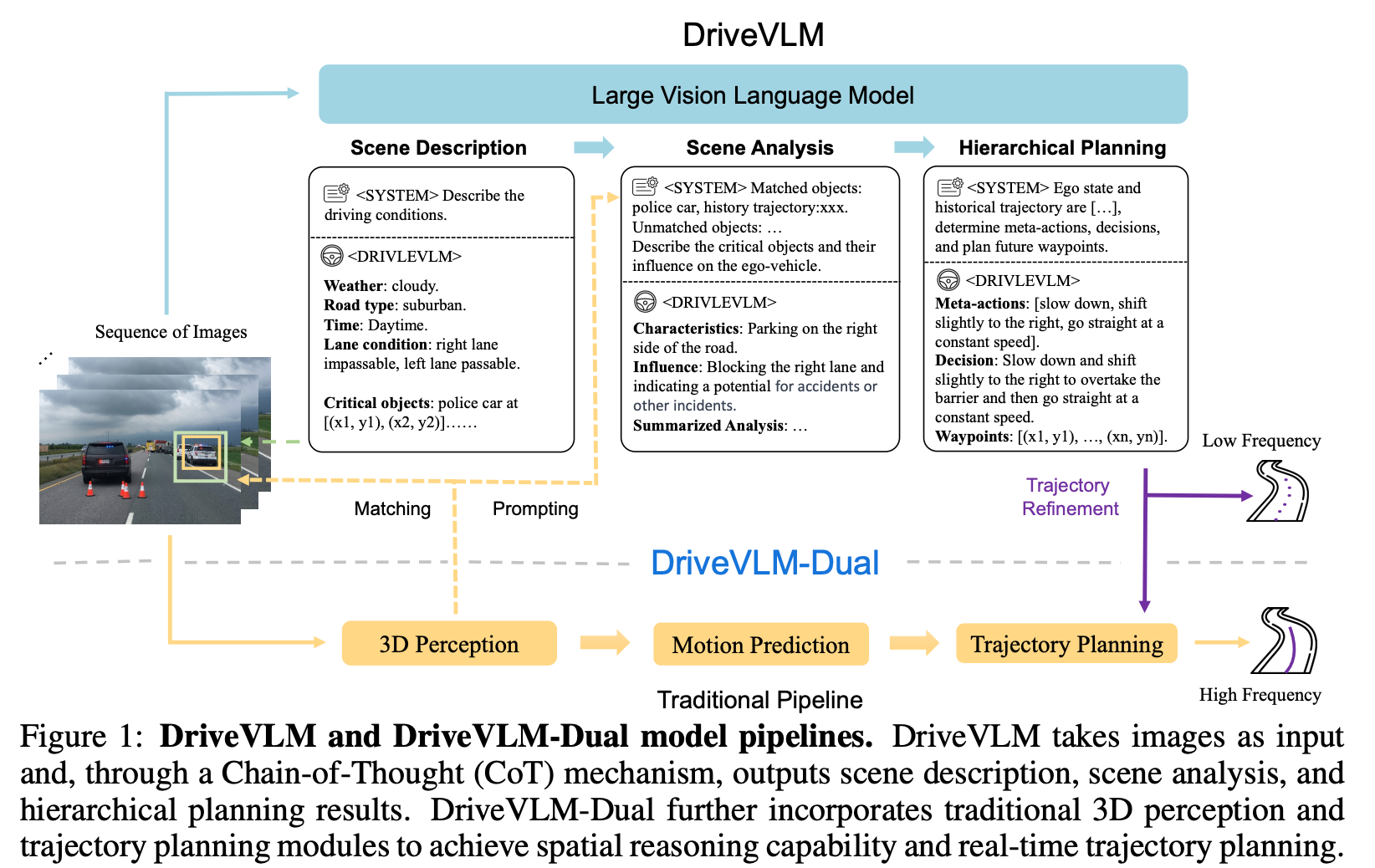
DriveVLM的核心方法包括以下几个创新点:
链式思考模块:集成了场景描述、场景分析和分层规划三个关键模块。
- 场景描述:使用语言描述驾驶环境(天气、路况),识别场景中的关键对象。
- 场景分析:深入分析关键对象的特征(static attributes, motion states, and particular behaviors)及其对自车的影响。
- 分层规划:从元动作(左转、加速 等控制动作)和决策描述到路径点逐步制定计划。
DriveVLM-Dual:结合了DriveVLM和传统自动驾驶系统的混合系统,通过整合3D感知和规划模块,提高了空间理解和高频规划能力。
Integrating 3D Perception:
DriveVLM由于延迟较大,对于空间与运动的理解能力不好,结合端侧的感知结果后可将Match到的关键对象的位置类别序列输入VLM中,以弥补这部分的劣势。
High-frequency Trajectory Refinement:
低频的DriveVLM与高频的端侧结果组合成为一个slow-fast双系统,slow系统的DriveVLM预测结果作为fast系统的初始结果,让Fast预测更好的结果。
方法框图说明:
DriveVLM接受图像序列作为输入,并通过CoT机制输出场景描述、场景分析和分层规划结果。
DriveVLM-Dual进一步整合了传统的3D感知和轨迹规划模块,以实现空间推理能力和实时轨迹规划。
任务定义

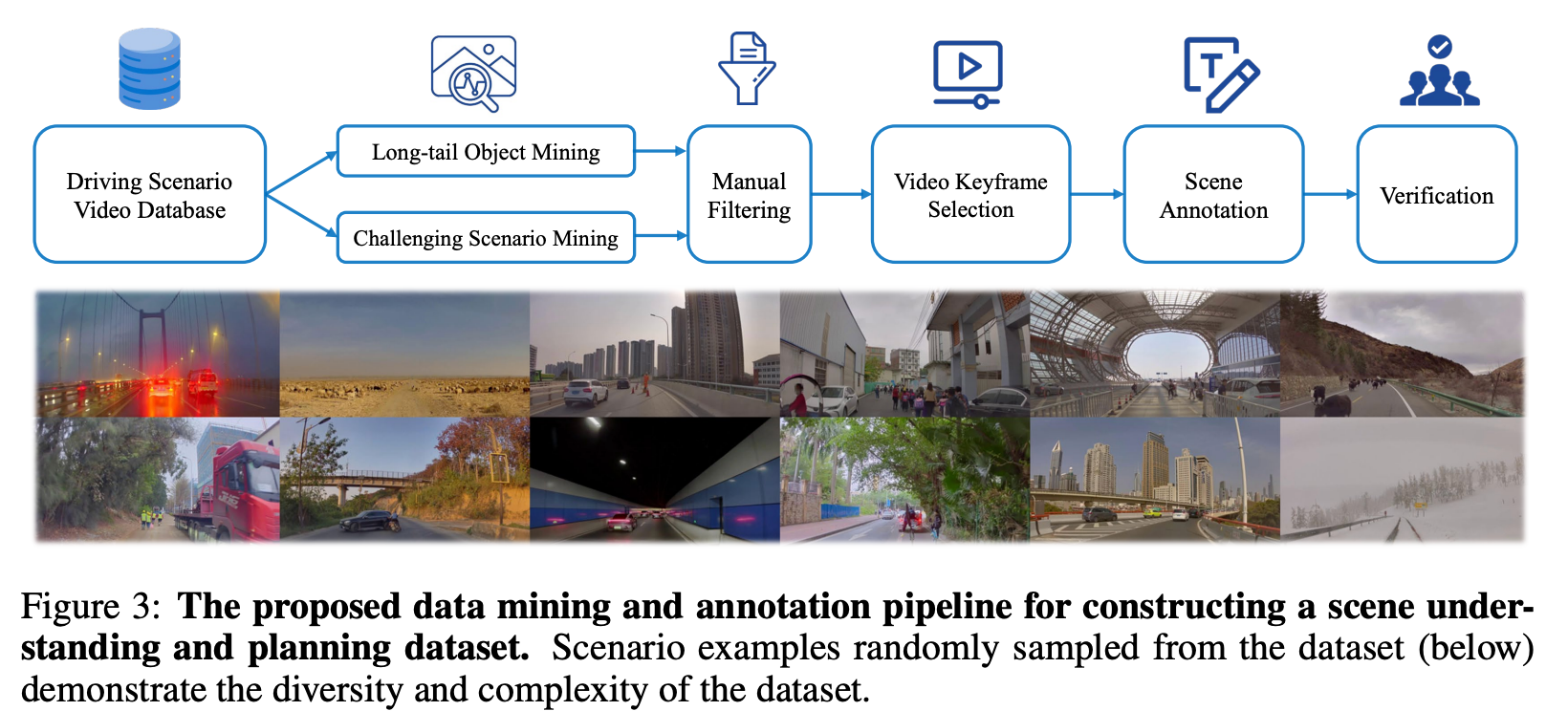
数据集构建
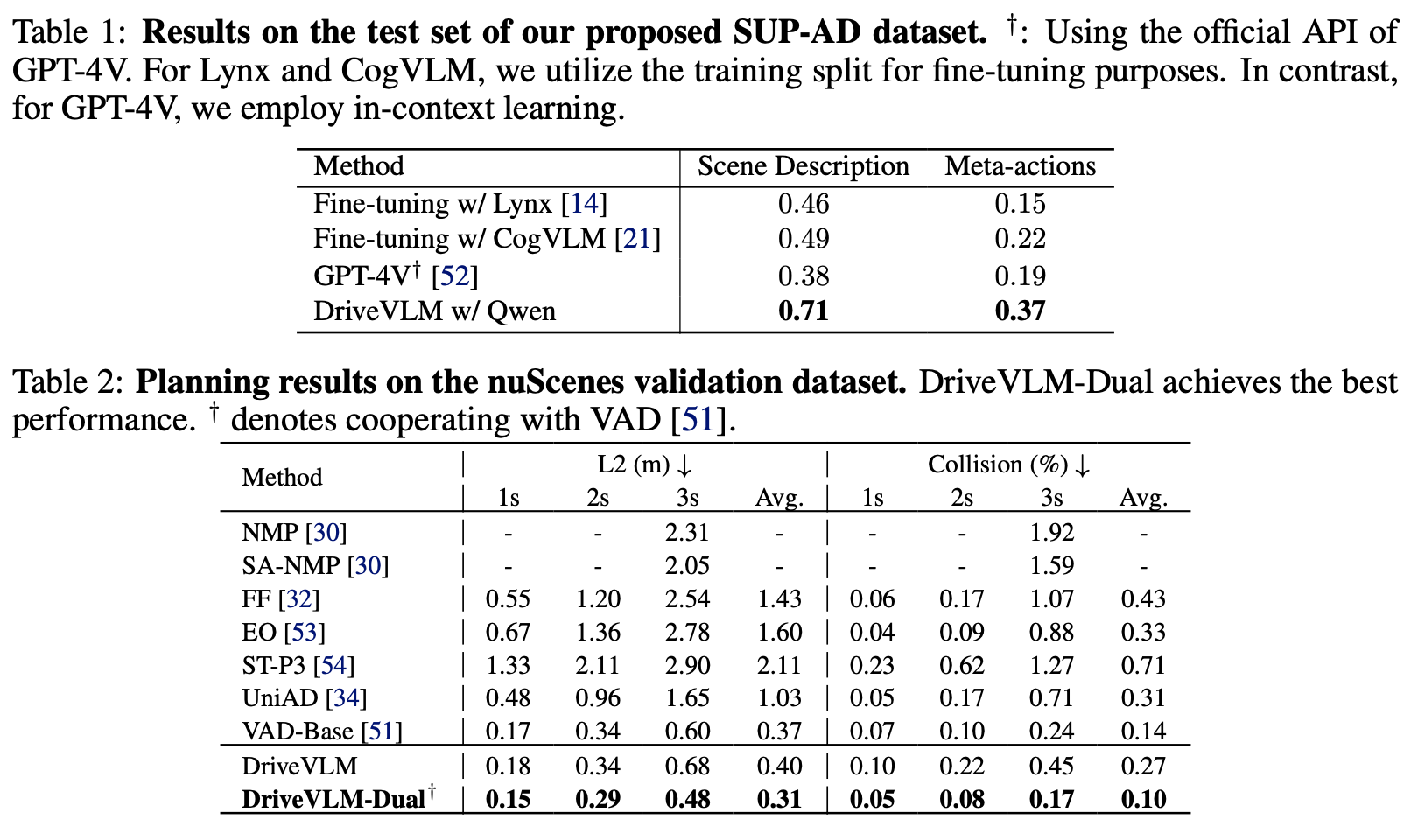
Experiment
使用通义千问的VLM作为BaseModel,参数量总共9.6B (visual encoder 1.9B, llm 7.7B, align 0.08B)
总结与发散
无
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18305461

 浙公网安备 33010602011771号
浙公网安备 33010602011771号