[Paper Reading] GAIA-1: A Generative World Model for Autonomous Driving
GAIA-1: A Generative World Model for Autonomous Driving
GAIA-1
时间:23.09
机构:Wayve
TL;DR
本文介绍一种生成世界模型,该模型利用视频、文本和动作输入来生成逼真的驾驶场景,同时提供对自身车辆行为和场景特征的细粒度控制。
Method
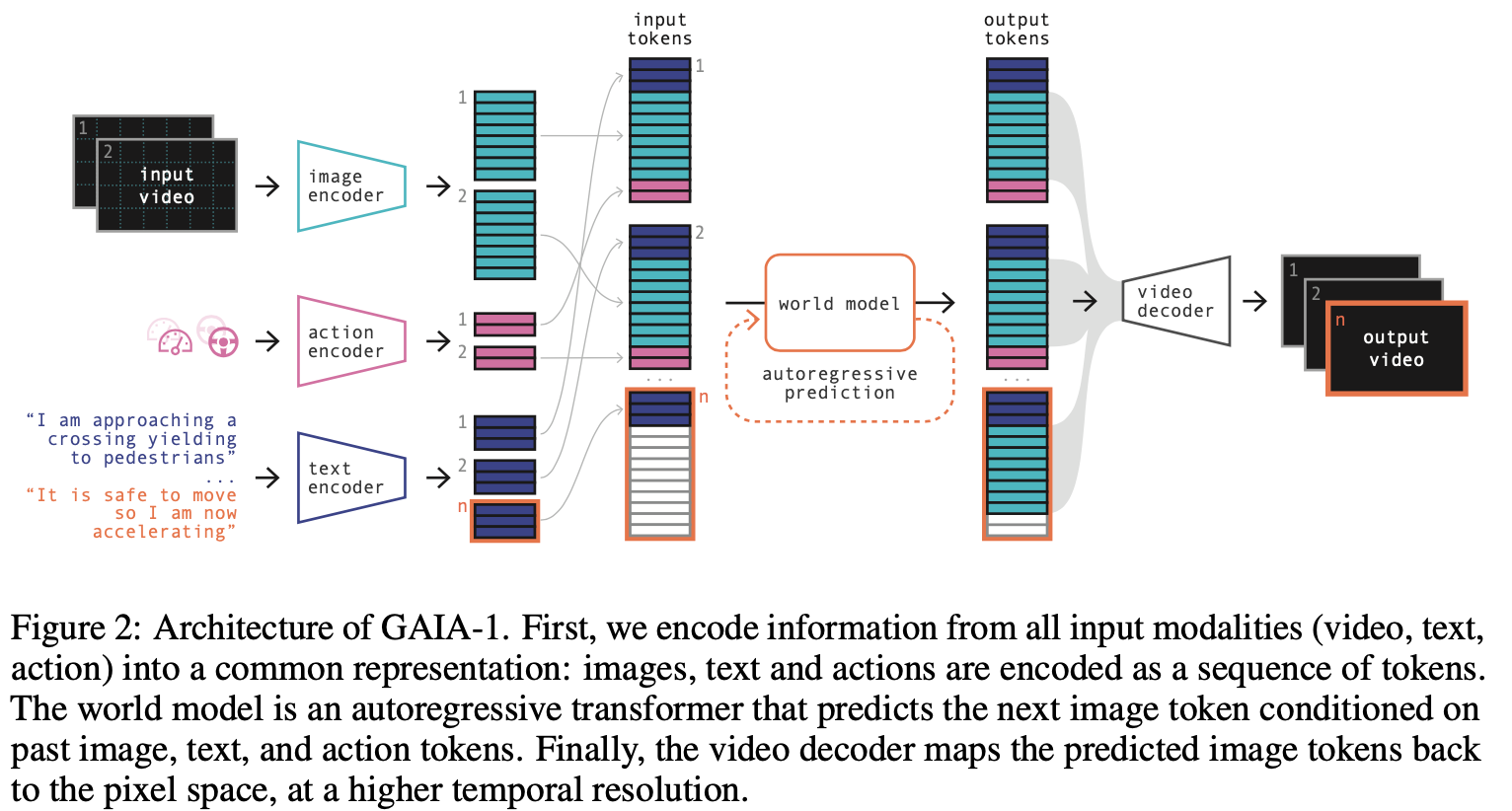
模型输入
训练过程输入video/text(参考上图示例)/action(速度、路线曲率)
Image Tokenizer

可以参考VG-GAN以及上面三个Loss项来理解Image Tokenizer的训练(引用[28]就是VQ-VAE),不过为了让Image Tokenizer有更强的语义信息,还另外增加了Dino特征的监督。参考下图,Dino特征监督后语义信息更强。

World Model
图像序列抽成token sequence之后,用自回归Transformer来训练,训练视频数据由25Hz降采样至6.25Hz。
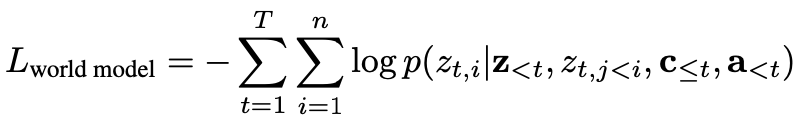
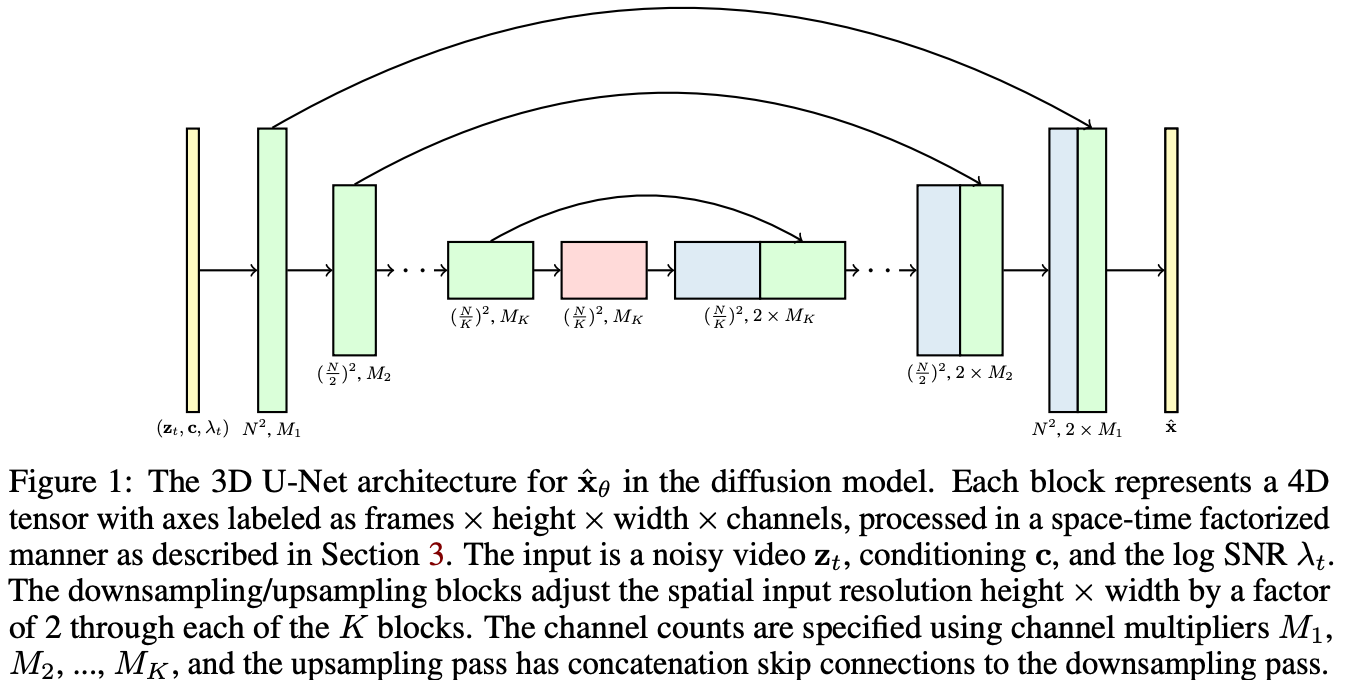
Video Decoder
使用一个3D UNet将image tokens还原为视频(参考 Video Diffusion Model),训练过程直接将Image Tokenizer抽出的token sequence拿来还原,推理时使用Worl Model生成的token sequence来还原。
实际训练过程是MultiTask训练,增强Autoregressive video generation泛化性。

其它细节
数据:4.7k小时的训练数据,4.2亿的图像。
| Model | Model Size | Training Time |
|---|---|---|
| Image Tokenizer | 0.3B | 32 A100训练4天 |
| World Model | 6.5B | 64 A100训练15天 |
| Video Decoder | 2.6B | 64 A100训练15天 |
推理过程是先生成6.5hz N帧的tokens序列,再上采样到25hz。

Experiment


总结与发散
类似于大语言模型,WorldModel能够从训练视频中压缩概括一些基本规律,在推理时根据Prompt信息预测出合理的场景图像。
相关链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18279765

 浙公网安备 33010602011771号
浙公网安备 33010602011771号