[Paper Reading] UniAD: Planning-oriented Autonomous Driving
Planning-oriented Autonomous Driving
link
时间:23.03
机构:Shanghai AI Laboratory && SenseTime
TL;DR
将 感知、预测 以及 规划 模块整合成为一个E2E的网络结构。该工作是CVPR2023的Best Paper。
Method
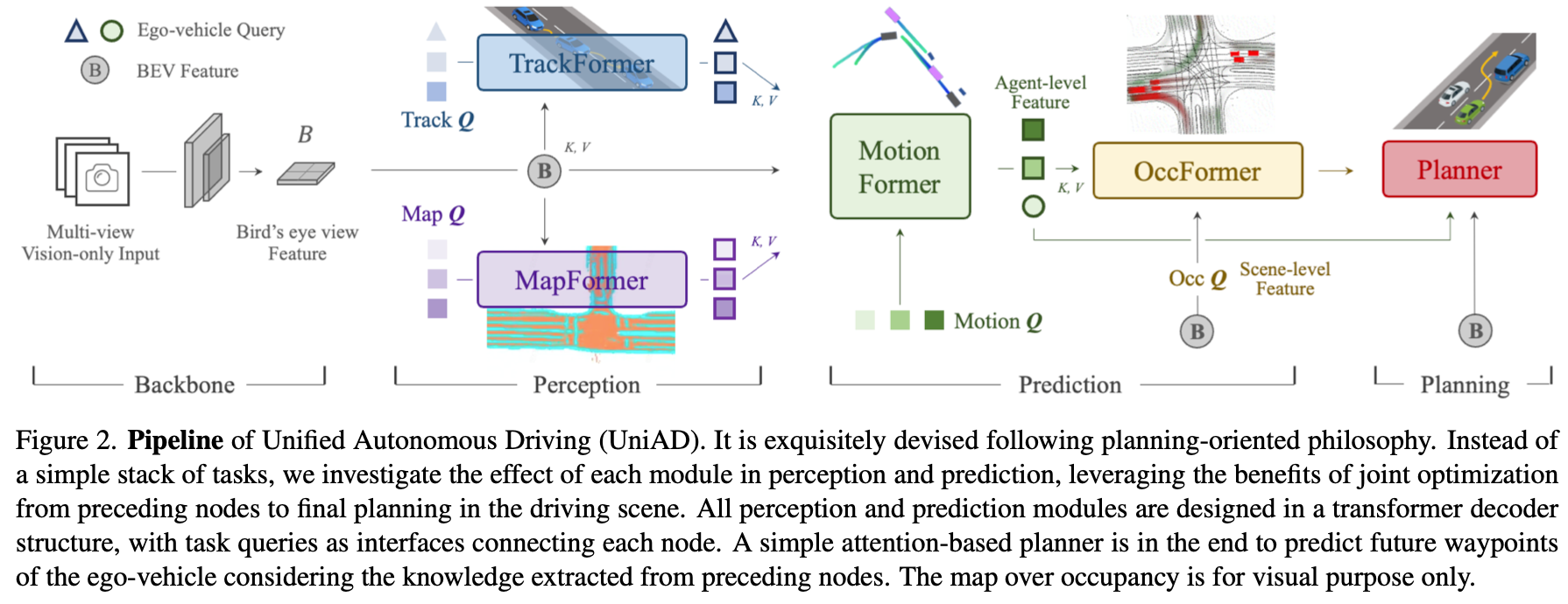
TrackFormer
可以参考MOTR来理解,MapFormer可参考来理解。
MapFormer
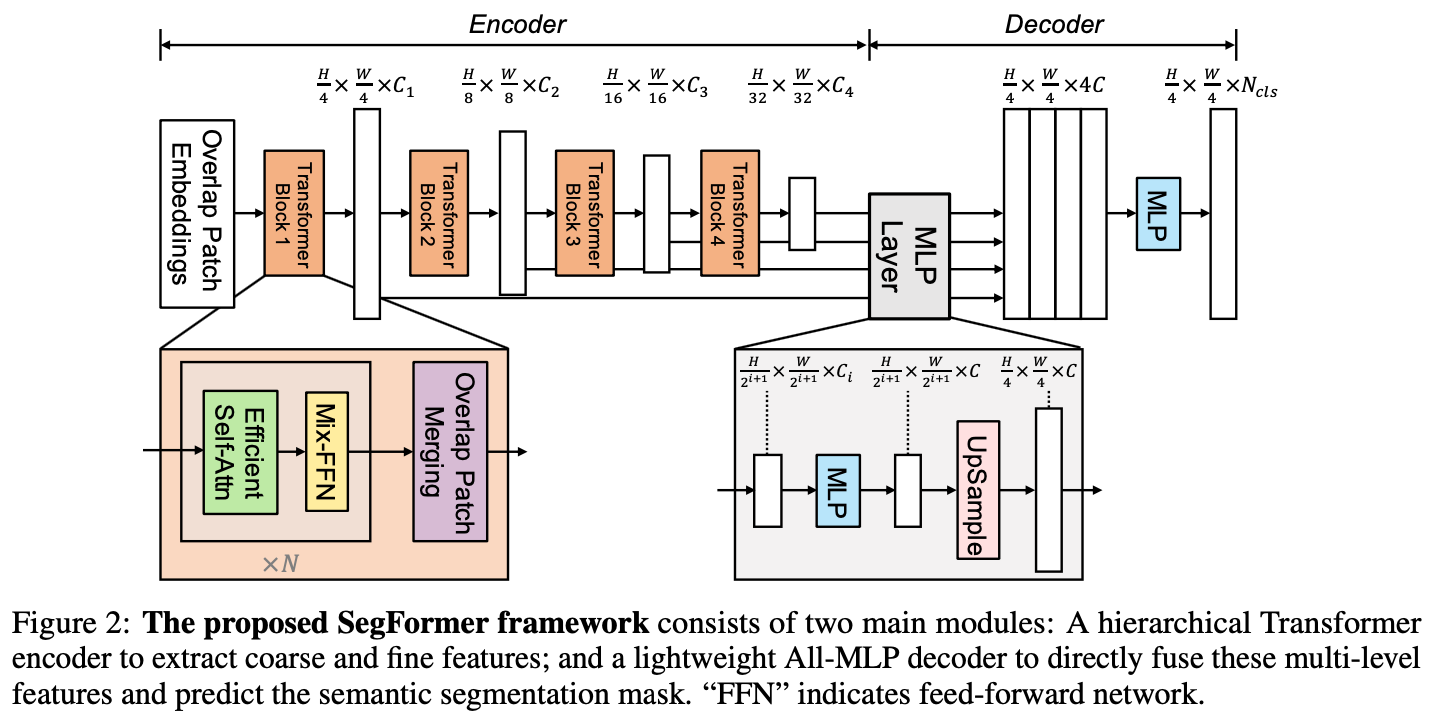
主要用来预测车道、分隔线、人行横道以及可行驶区别。做法可参考Segforme来理解,Segformer的结构图如下图所示。不同于ViT backbone,Segformer中使用的是MiT(Mix Transformer Encoder),MiT区别与ViT主要在两处:
Hierarchical Feature Representation
即利用Transformer抽取multi-scale的特征sequence,关键在于feature sequence特征下采样方法,Segformer使用了一种称为Overlapped Patch Merging的处理,简单来说就是将2x2邻域内特征合并为一个feat embedding。
Given an image patch, the patch merging process used in ViT, unifies aN ×N ×3patchintoa1×1×C vector. Thiscaneasilybeextendedtounifya2×2×Ci feature path into a 1 × 1 × Ci+1 vector to obtain hierarchical feature maps.
All-MLP Decoder
参考Segformer架构图右下解,即通过Upsample(类似于CNN特征的处理)上采样到统一分辨率(W/4, H/4)。
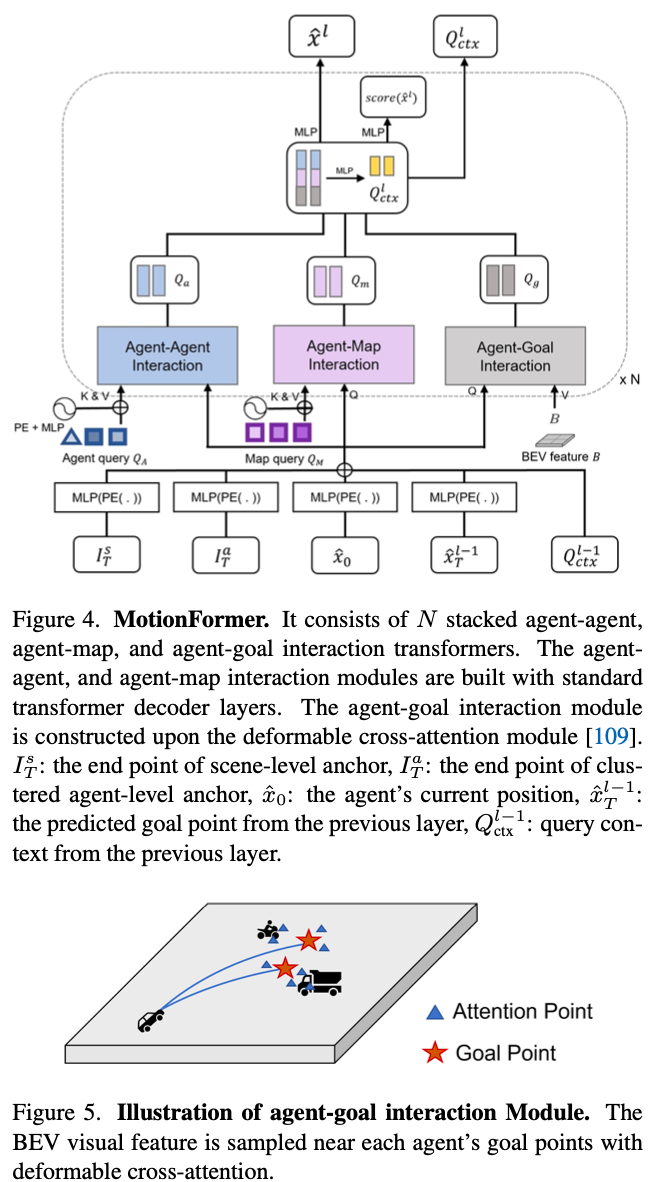
MotionFormer
如下图所示,重点需要理解Agent-Goal Interaction,每个目标会有6条候选轨迹,在每个轨迹中有4个点。通过agent query与轨迹中采样出的24点之间关系来确定最终需要预测的轨迹。
Occupancy Prediction
t帧时序窗口(包括当前帧与未来帧)预测instance级别occupancy,输入包括稠密特征\(F^{t-1}\)以及来自之前模块的稀疏特征{物体特征\(Q_A\), 物体位置\(P_A\)以及运动信息motion query \(Q_X\)}

Planning
将turn left, turn right and keep forward等运动编码为指令query(command embeddings),将planning query输入BEV特征使得运动规划过程能考虑到周围环境信息。Loss方面一方面需要让预测的指令接近GT轨迹,另一方面需要指令对应的运动轨迹远离被占据的栅格(利用occupancy predictoin信息)。

Experiment
实验训练分为两步,第一步先训感知部分(TrackFormer, MapFormer),第二步再整体E2E训练。
与BEVFormer、LSS等经典方法对比,至少车道线上提升还是比较明显的。

总结与发散
下游的几个模块几乎都使用了BEV特征,是E2E训练的桥梁,所以perception部分很重要会提前训练收敛
实验工作量比较大,论文写得比较扎实
整体E2E是个有潜力的大方向,类似于RCNN->Faster-RCNN的进化
相关链接
https://zhuanlan.zhihu.com/p/642373931
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18228737

 浙公网安备 33010602011771号
浙公网安备 33010602011771号