[Paper Reading] Scene as Occupancy
Scene as Occupancy
link
时间:23.06
机构:Shanghai AI Lab && SenseTime && CUHK
TL;DR
提出使用3D Occupancy来表征3D物理场景,相对于3D检测框,3D Occ可提供更细粒度细节。提出OccNet一种多目级连的时序模型,运动规划碰撞率降低15%~58%。创新性:be the first to investigate occupancy as a general descriptor that could enhance multiple tasks beyond detection.
Method
整体Pipeline如下图所示,BEV Encoder使用的BEVFormer,获取BEV特征后经过Cascade Voxel Decoder得到Occupancy Descriptor特征,在该特征上接Head预测下游任务结果。
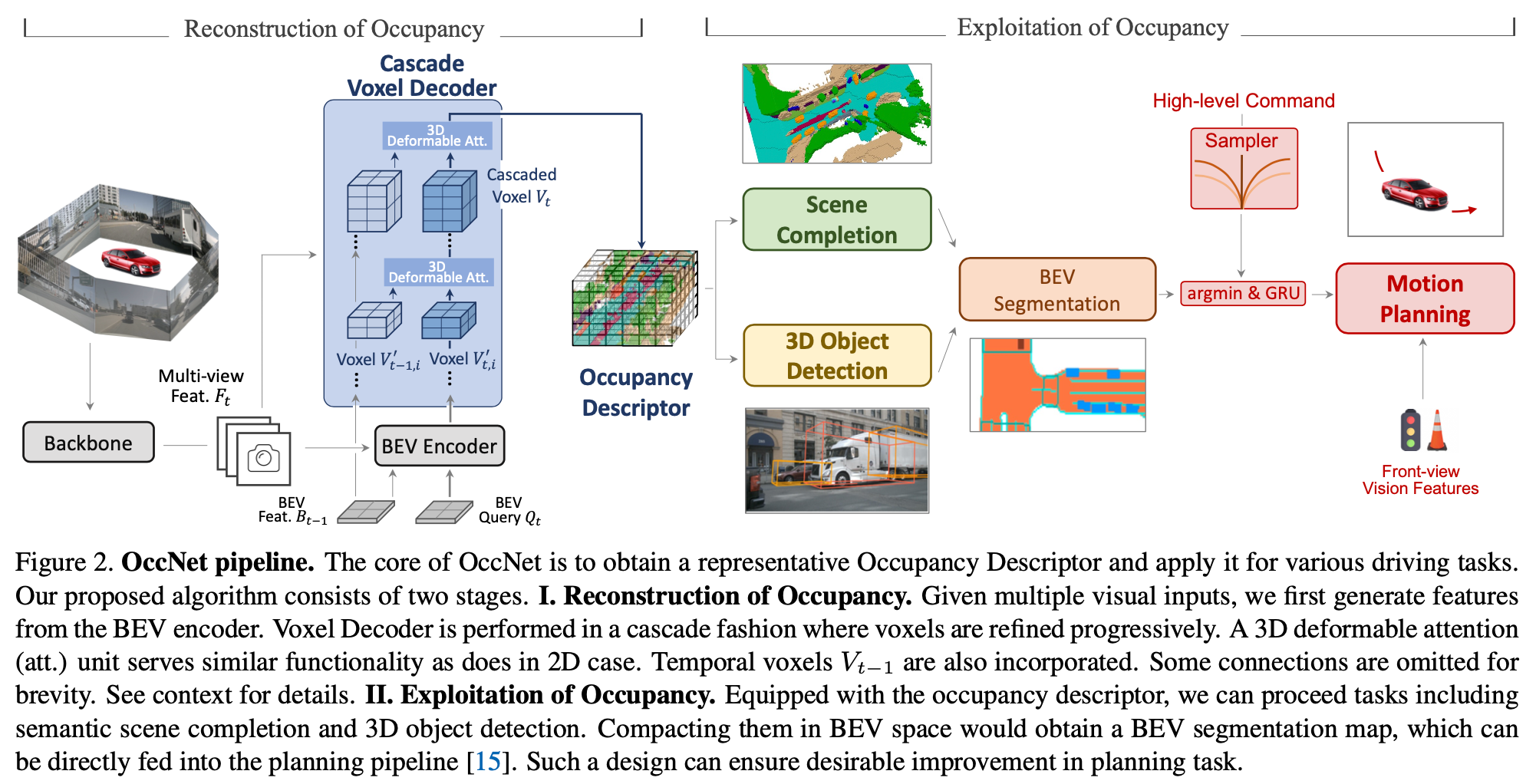
Cascade Voxel Decoder
Voxel based Temporal Self-Attention
使用车身位姿将历史voxel feature转换到当前坐标系下得到voxel feature \(V'_{t-1, i}\), 再与当前帧\(V'_{t-1, i}\)做Self-Atten,由于计算量比较大,使用3D deformable Atten来降低计算量。
3D Deformable Attention
定义如下公式,其实是将本来全局范围的attention收缩到K个点范围内,这K个点的相对位置是类似于2Ddeformable学习出来的。

Voxel-based Spatial Cross-Attention
参考BEVFormer中的spatial cross-attention的做法,主要是根据3D格点位置去2D feature上采样特征。
Exploiting Occupancy on Various Tasks
Semantic Scene Completion:针对每个voxel都预测一个类别与速度。
3D Object Detection:拍成BEV特征,使用DETR那种固定query数的方法预测3D目标。
BEV segmentation:拍成BEV特征,预测segmentation map。
Motion Planning:将BEV segmap处理成0-1 map,根据输入sampled trajectories在该map上计算cost,根据cost来选定运动轨迹。
Experiment
建立了一个OpenOcc的Benchmark,相对于其它Benchmark差别如下图。

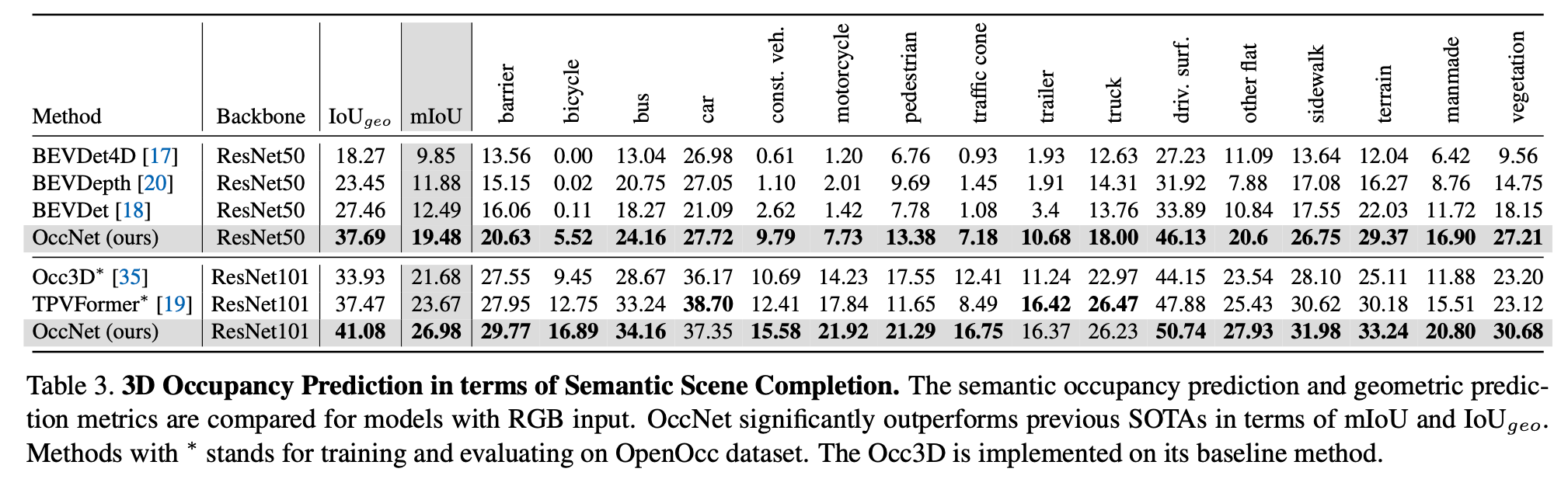
在OpenOcc明显超越其它方法。
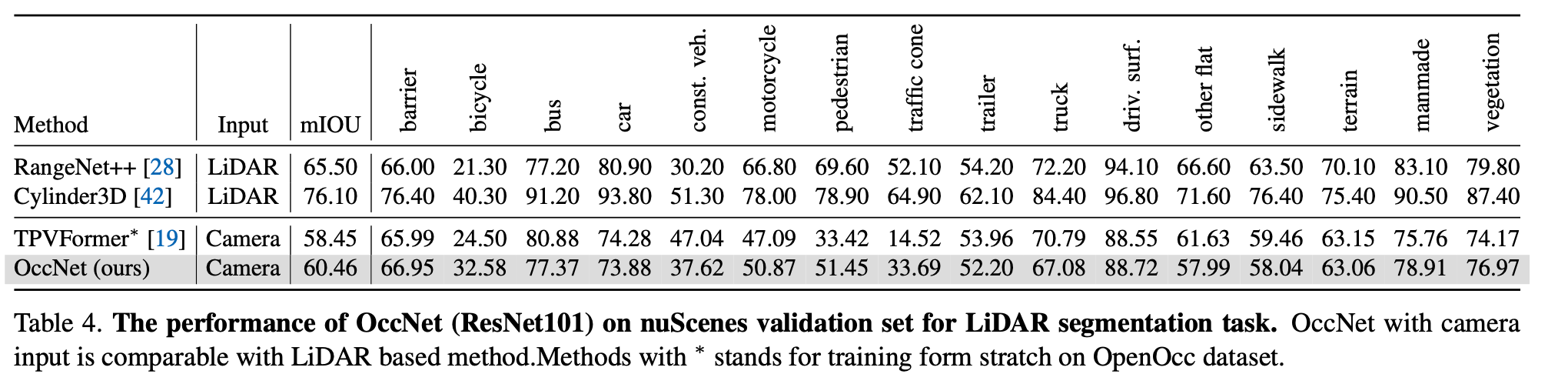
在nuSence上优势明显,接近Lidar-based方法了。
总结与发散
BEV与OCC的区别:
BEV是平面的特征空间,OCC是3D的特征空间
BEV与OCC的联系:
OCC是基于BEV特征增加高度维度加工出的特征空间
OCC主要是为了解决高度问题引入的特征空间,但感觉这么做ROI有些低(计算量变复杂了很多,但只是针对少数形状奇异的人车或者障碍物有特殊用处)。
相关链接
link
https://github.com/OpenDriveLab/OccNet
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18206539

 浙公网安备 33010602011771号
浙公网安备 33010602011771号