[Paper Reading] BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
link
时间:22.07
机构:Nanjing University && Shanghai AI Laboratory
TL;DR
利用Transformer的Attention机制融合时空特征信息,在nuScenes测试集上达到SOTA精度,同时在速度估计以及可见度低路况也有明显精度提升。
Method

BEV Queries
BEV是一个可学参数的Tensor,Shape为(W, H, C),其中W, H即为BEV平面的定义(单位是m,以车身为中心点),每个grid中有一个channel为C的可学向量。
SCA(spatial cross attention)
如下公式所示,BEV平面上每个cell可以沿着高度方向lift出\(Nref\)个3D refer points,\(P(p, i, j)\)就是将BEV下P点的第j个高度上投影至在第i个view的2D点坐标,再使用该2D点坐标提取图像特征信息并与BEV Query \(Q_p\)加权得到此处query出的特征。

Temporal Self-Attention
同上,利用车身motation 6Dof信息将上一帧feature对齐到当前bev空间(与Q同坐标系)得到\(B'_{t-1}\),使用\(Q_p\)与\(B'_{t-1}\)预测特征偏移\(p\),根据如下TSA公式计算attention特征。由于这种方法仅融合上一帧时序特征,计算量更小。

Q: 后续BEV上的特征是否还需要splat成为2D?
A: 根据公式中的\(\Sigma\)推测特征应该会沿着垂直方向求和,最终得到2D BEV平面上的特征。
Experiment
看实验结果TSA的作用很明显。
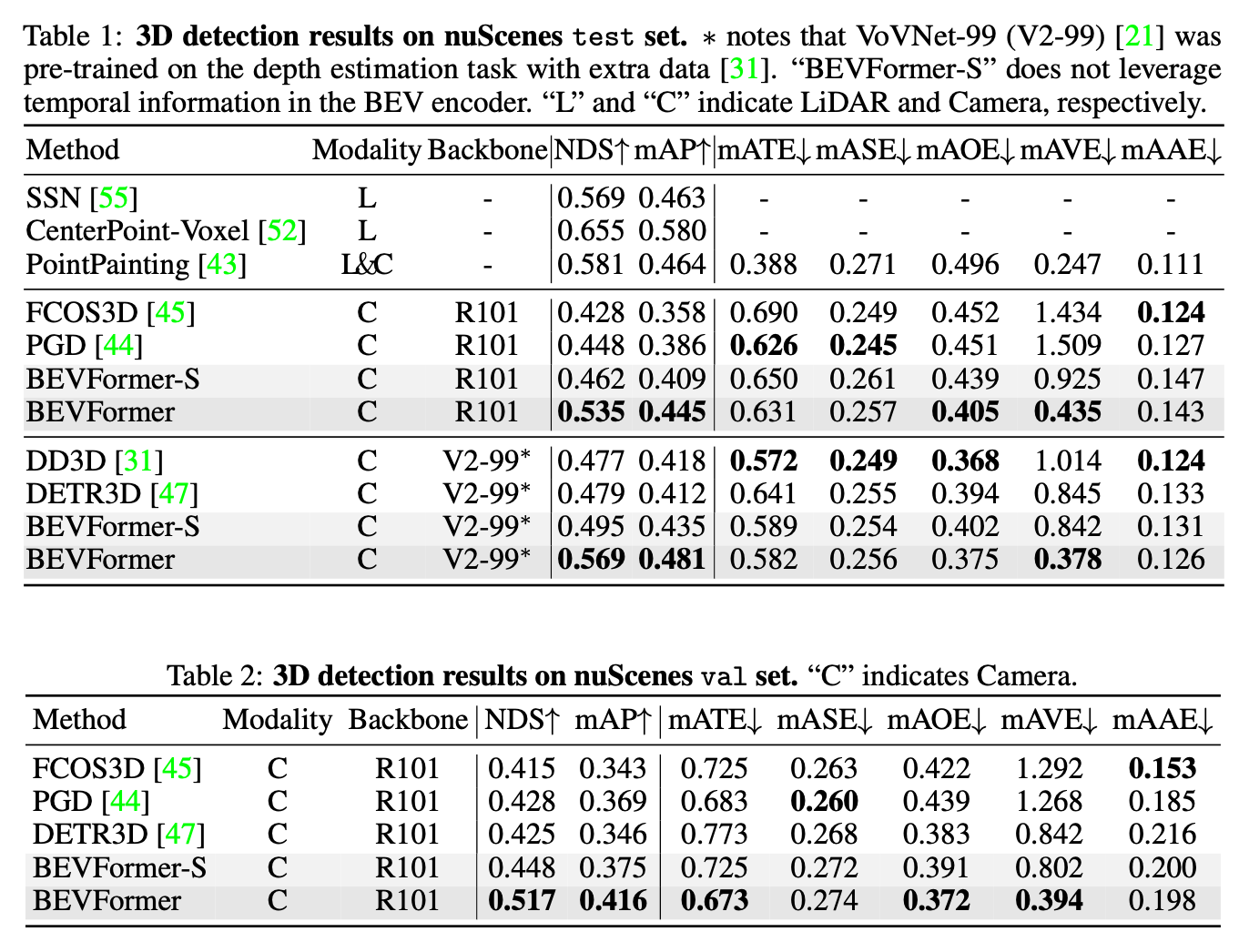
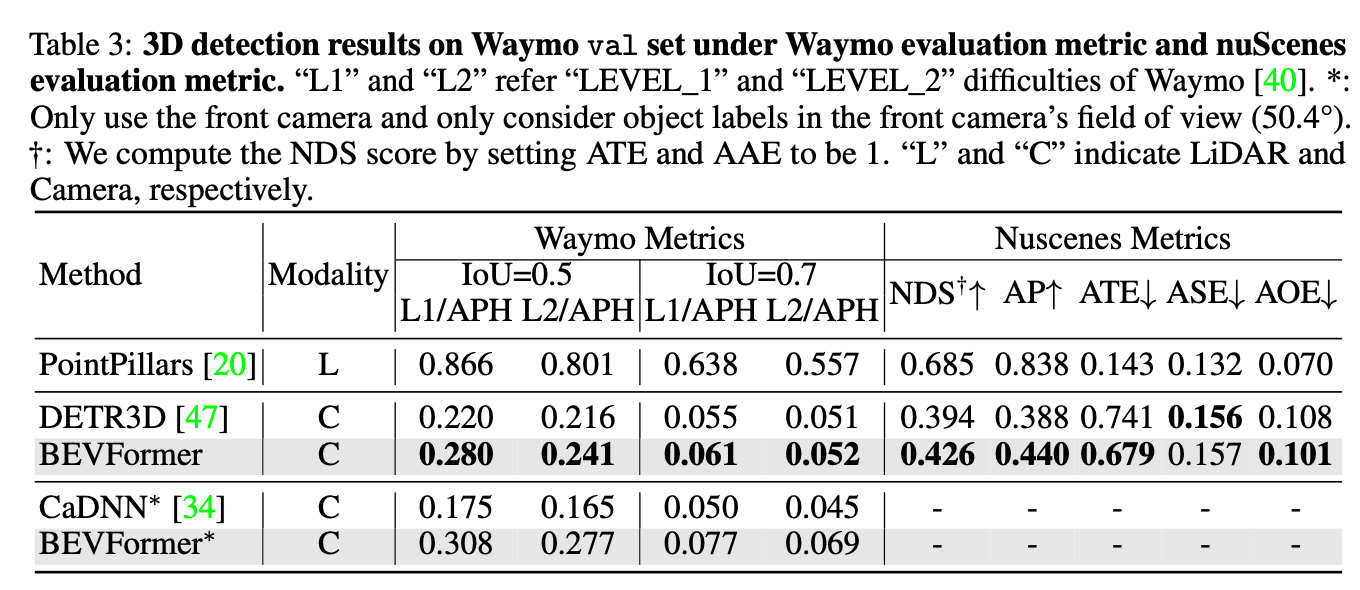
总结与发散
在BEV栅格中放Transformer的Query,利用几何关系去2D图像上Query对应特征,再填满BEV删格,整个过程更加E2E以及Transformer化。
相关链接
Code: https://github.com/zhiqi-li/BEVFormer
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18201780

 浙公网安备 33010602011771号
浙公网安备 33010602011771号