[Paper Reading] PETR: Position Embedding Transformation for Multi-View 3D Object Detection
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
PETR: Position Embedding Transformation for Multi-View 3D Object Detection
时间:22.07
机构:Megvii
TL;DR
一种多目3D目标检测的方法,主体思想是将3D坐标信息编码到2D图像特征,产生3D awared features,利用object query在这种特征上直接预测3D结果。
Method
方法架构图如下,首先这是一个多目的E2E 3D detection方法(文中没有说明多目的3D awared features如何进行融合),下面详细说明 3D Coordinates Generator, 3D Position Encoder以及Query Generator部分。
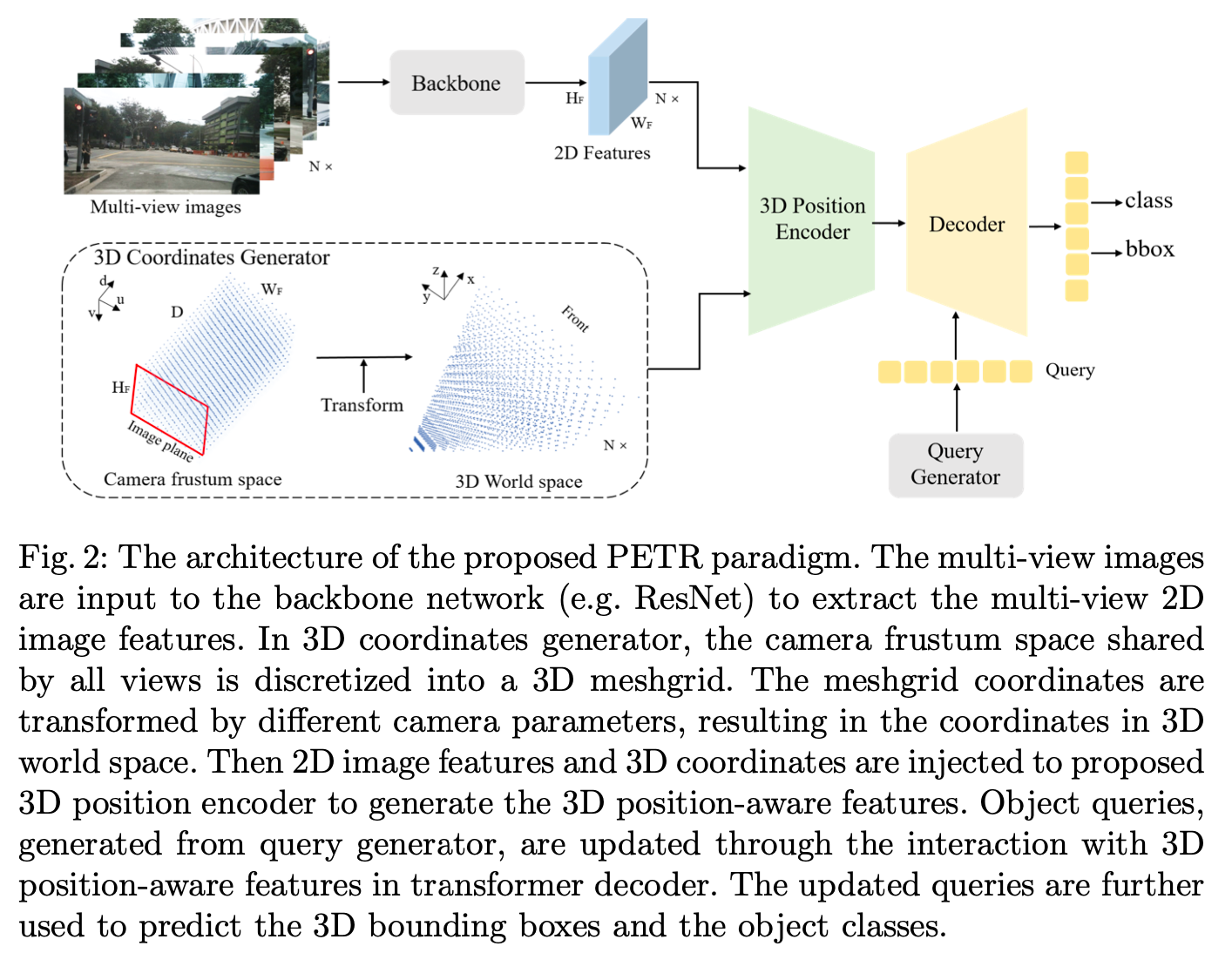
3D Coordinates Generator
这一步将camera frustum空间(\(u_j\) × \(d_j\), \(v_j\) × \(d_j\), \(d_j\), 1)转为3D world空间 (x, y, z, 1),这两种空间的坐标点可视化参见架构图左下角。转换关系如下,后续模块使用的就是3D world空间的坐标点,是融合了相机参数信息在里面的。关于camera frustum space下空间的划分可以参考DGSN
![]()
其中,K是4x4矩阵,融合了相机内外参,可将3D space点转到camera frustum space。
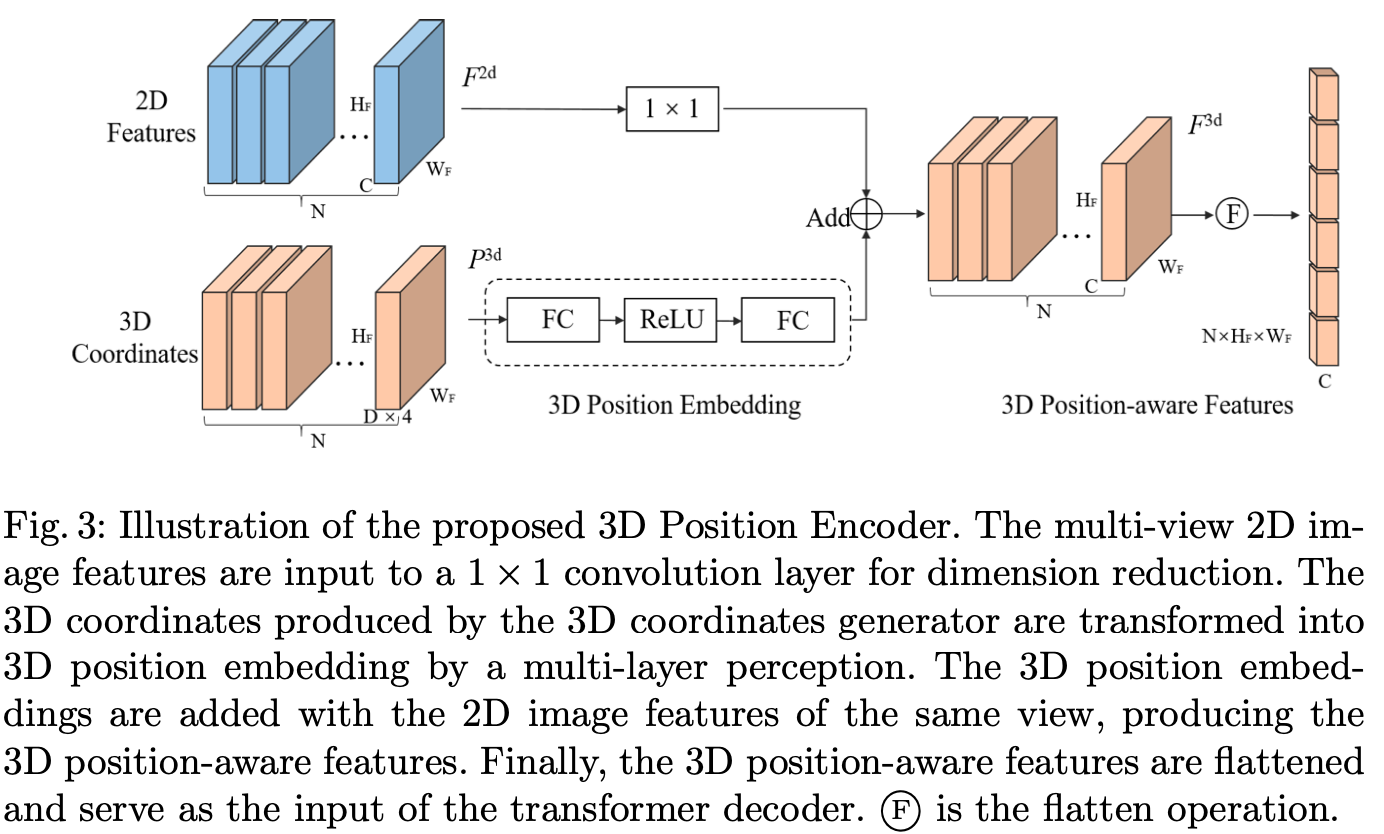
3D Position Encoder
该模块比较NN,就是将N view的2D feature对应的3D空间的position coordinate分别提取特征,融合后形成N view的3D awared特征。注意,由于3D coordinates取决于图像大小与相机参数,所以是定值,可以一次性提取好并缓存,这里称为3D Position Embedding。
Query Generator
参考anchorDETR,使用3D space上均匀分布的点作为送入MLP之后得到可学习anchor points的初值,这种方法更容易收敛。 后续的Decoder、Head及Loss类似于DETR,不再赘述。
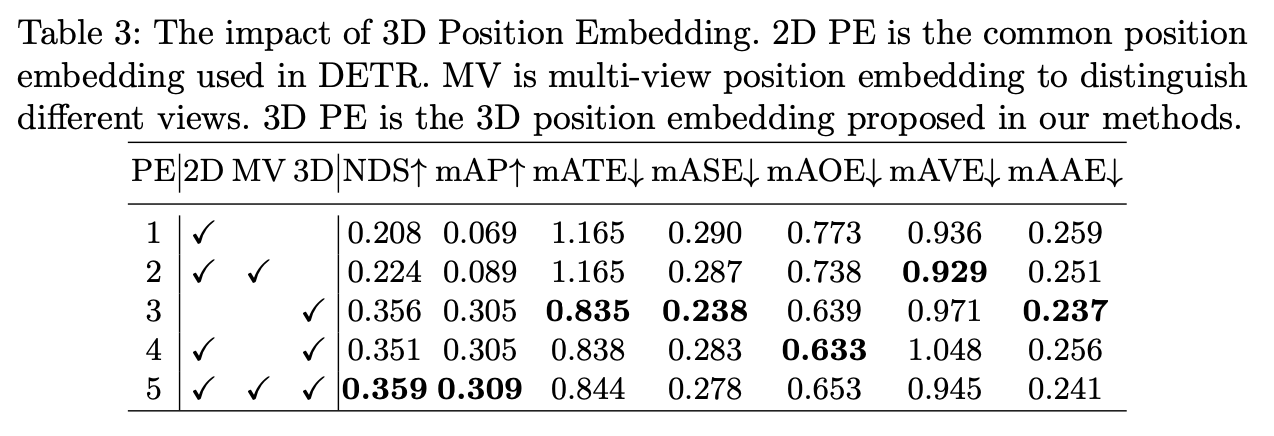
Experiment
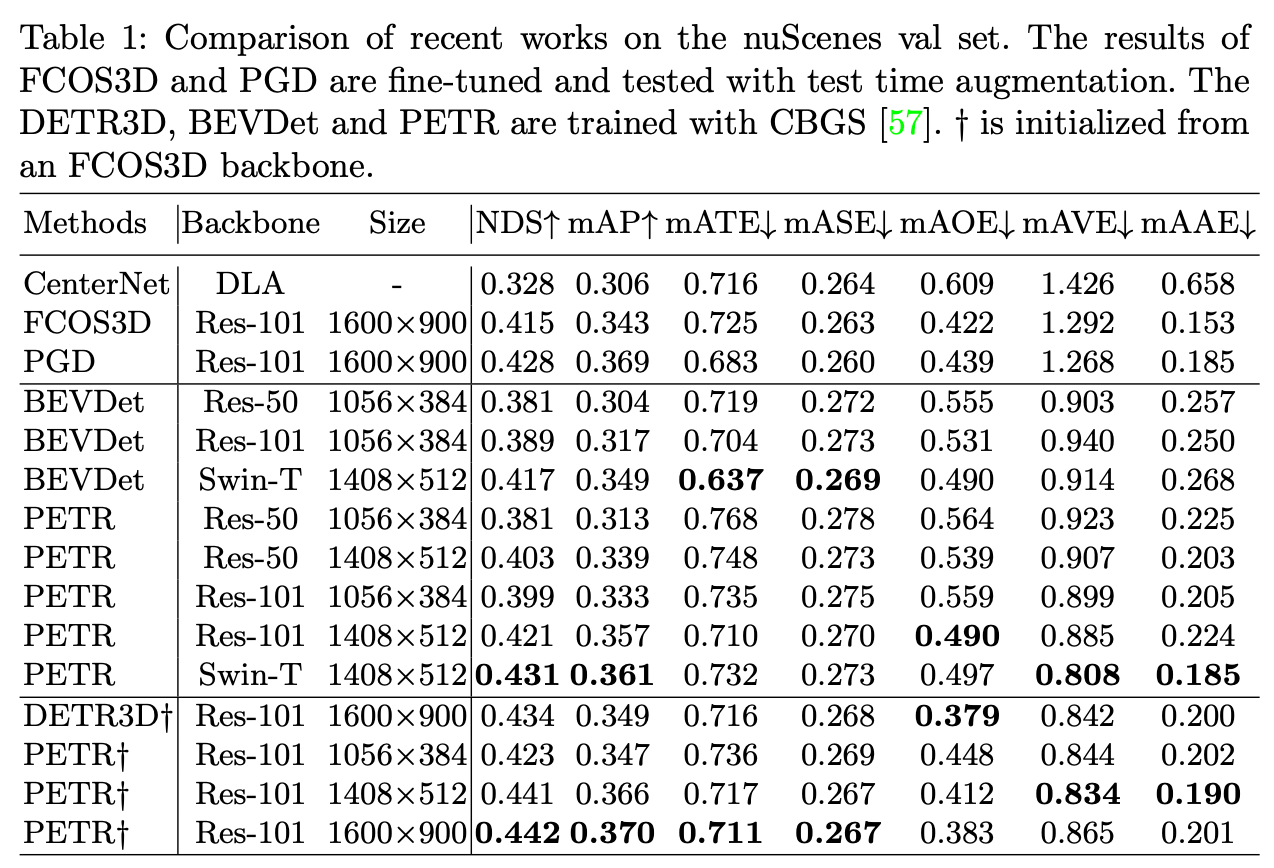
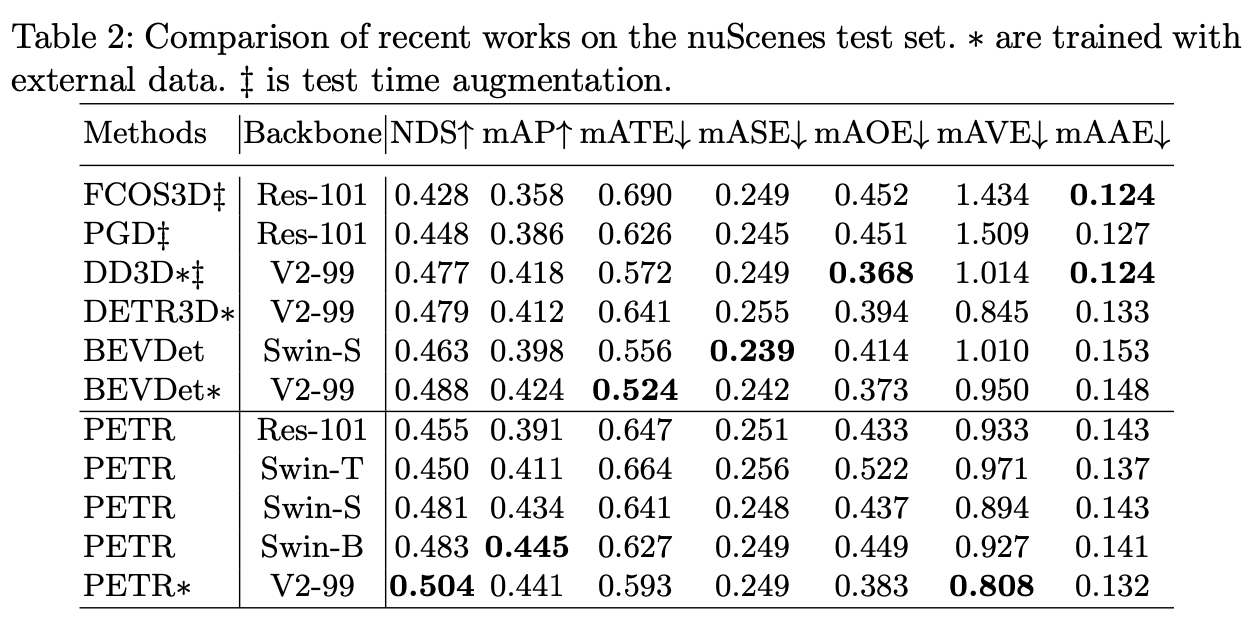
使用3D Position Embedding能明显提升精度(个人理解主要是里面隐含了相机参数信息)。
总结与发散
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18193774

 浙公网安备 33010602011771号
浙公网安备 33010602011771号