[Paper Reading] OFT Orthographic Feature Transform for Monocular 3D Object Detection
OFT Orthographic Feature Transform for Monocular 3D Object Detection
OFT Orthographic Feature Transform for Monocular 3D Object Detection
时间:18.11
机构:University of Cambridge
TL;DR
当时纯视觉自动驾驶方案效果上仅达到Lidar方案有10%的水平,本文claim部分差距源于perspective view看到的目标scale与外观会随着深度发生变化,本文提出正交特征变换层(orthographic feature transform)解决该问题。
Method

整体网络架构参见上图,主要创新的模块是OFT层(orthographic feature transform)。如下图,OFT主要作用是建立一个3D voxel feature map(例如,80m×4m×80m空间下每0.5划分一个栅格),栅格中每个位置的feature利用如下公式投影到图像特征空间ROI,使用average pooling(实际上用积分图实现)计算该栅格对应的特征。
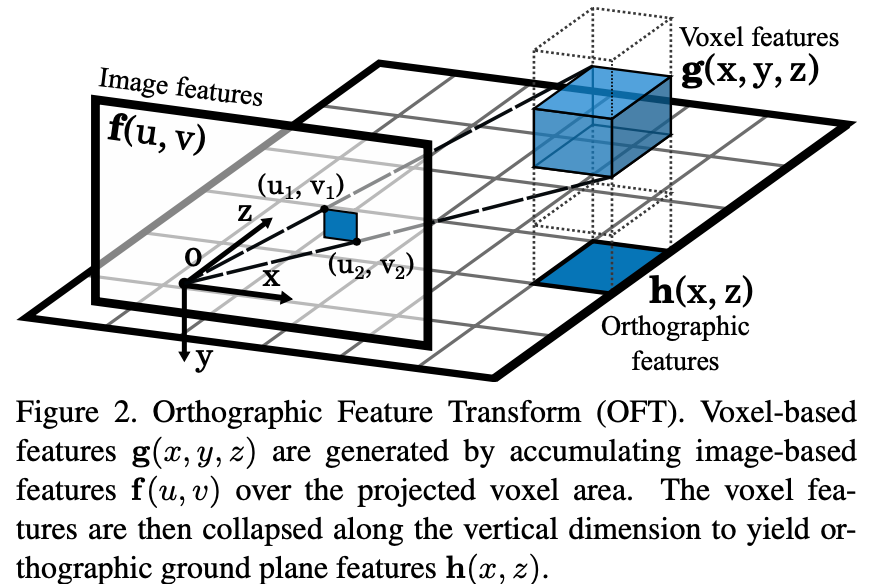
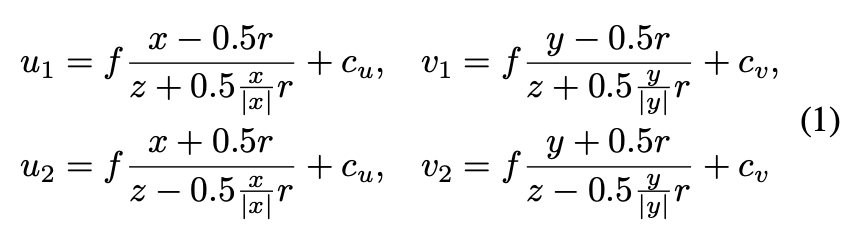
Q: 是否有类似于LSS的splat步骤? yes
获取3D voxel feature map后,为了降低计算量,利用自动驾驶更关注目标的BEV平面位置信息而非高度的特点,使用一个垂直方向的pooling将3D特征splat成为2D特征图,称为orthographic feature map。如下公式(1)所示,\(W(y)\)为pooling过程每个voxel对应的权重,为可学习参数。
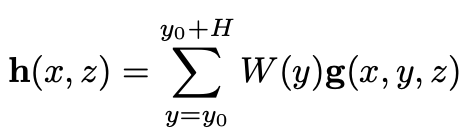
![]()
Q:box如何回归?是否回归角度?
confidence score S, a position offset ∆pos, a dimension offset ∆dim(w, h, l) and an angle vector ∆ang(因为在BEV平面,所以预测仅y轴对应角度)
Q:是否有栅格特征是否有多目特征融合?否
根据作者在实验中描述,应该都是Mono view直出,3D voxel空间未进行多目特征融合。
Experiment
单目实验结果里面提升比较明显,但也双目方法仍有差距。
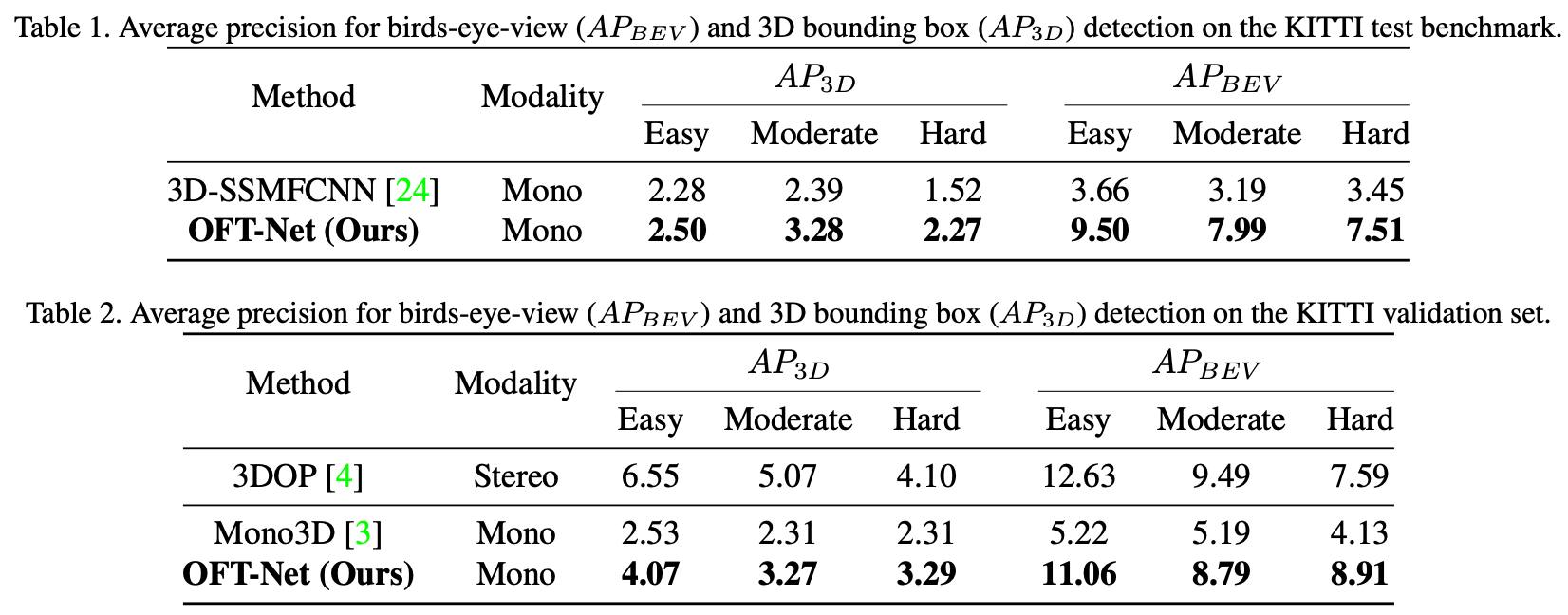
总结与发散
在bird view而非perspective view上提取特征预测结果听起来确实很合理
orthographic feature map后续慢慢会演变为BEV featmap,好处:
- feature map的spatial位置与最终要输出结果的位置更加对应。
- 提供了一个统一的特征空间供后续多目特征融合。
相关链接
OFT Orthographic Feature Transform for Monocular 3D Object Detection
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18177096

 浙公网安备 33010602011771号
浙公网安备 33010602011771号