[Paper Reading] LSS: Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
名称
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
时间:20.08
机构:NVIDIA
TL;DR
后融合方法将每一目感知结果通过相机参数转换到BEV空间再后融合,LSS开启前融合的先河,将特征通过先lift再splat到BEV空间,通过BEV空间特征直接预测结果,并且部分感知任务达到SOTA水平,比如segmentation。
Method
Lift

目标是将特征升维到3D空间,由于没有深度信息,针对每个pixel位置会预测一个深度空间的oneshot向量\(\alpha\),该pixel位置的特征向量c与\(\alpha\)外积(即每个深度bin对应的值都会与c相乘得到一个特征向量再拼到一起如上图所示)得到lift之后的3D特征。
Splat
如下图所示,利用相机外参将Lift出的点云及对应的特征描述子合并到同一个坐标系下,再使用sum pooling整合为一个C × H × W的特征图(详细的作法参见pointpillars)。
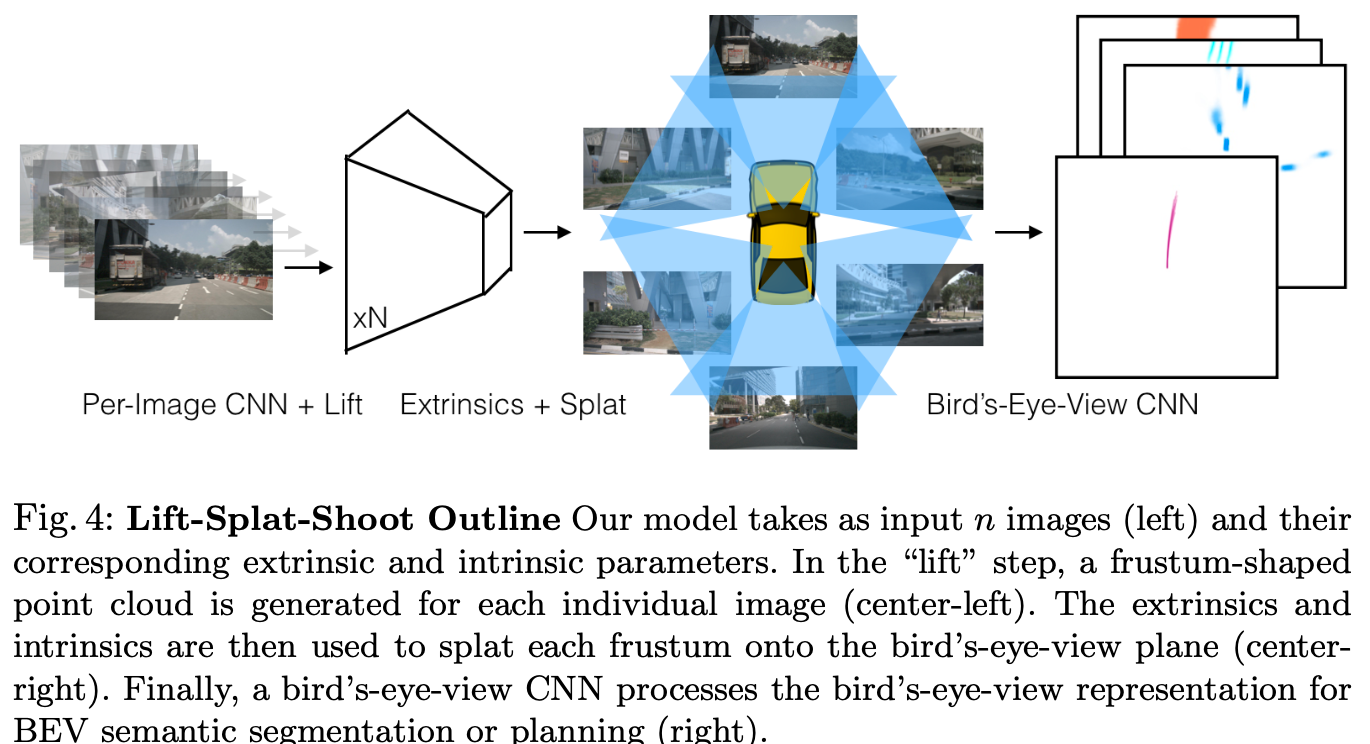
Shoot
利用BEV feature预测K条轨迹中概率最大的那个(K条轨迹是根据先验提前聚类出来的)
Experiment
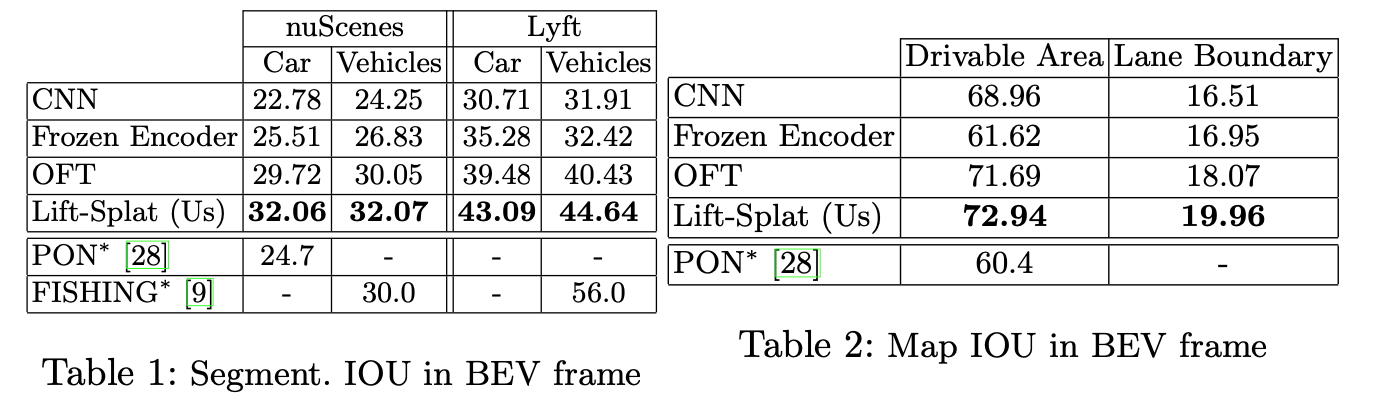
相关链接
OFT Orthographic Feature Transform for Monocular 3D Object Detection
pointpillars
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18175990

 浙公网安备 33010602011771号
浙公网安备 33010602011771号