[Paper Reading] VQ-GAN: Taming Transformers for High-Resolution Image Synthesis
名称
link
[VQ-GAN](Taming Transformers for High-Resolution Image Synthesis)
时间:CVPR2021 oral 21.06
机构:Heidelberg Collaboratory for Image Processing, IWR, Heidelberg University, Germany
代码可参考Stable Diffusion中实现:https://github.com/CompVis/stable-diffusion/tree/main/configs/autoencoder
TL;DR
Transformer优势在于能较好地长距离建模sequence数据,而CNN优势是天生对局部位置关系具有归纳偏差。本文结合两者特征,利用CNN建立context-rich vocabulary的codebook,利用transformer建立高分辨率(long range relations)构成。本文提出VQ-GAN结合Transformer与CNN两者,可以利用语义信息合成高分辨率图像。
GAN基础知识(前置基础知识)
GAN全称Generative Adversarial Network,包含两个功能模块分别是generator G用来生成图像(从noise vector生成图像),discriminator D用来判断生成图像的真实性(二分类网络判断输入图像是真实还是生成,从而拉进两类数据分布距离)。
网络结构
有点像反过来的AE,即Decoder在前面先生成图像,再用Encoder来判断图像的真实性。
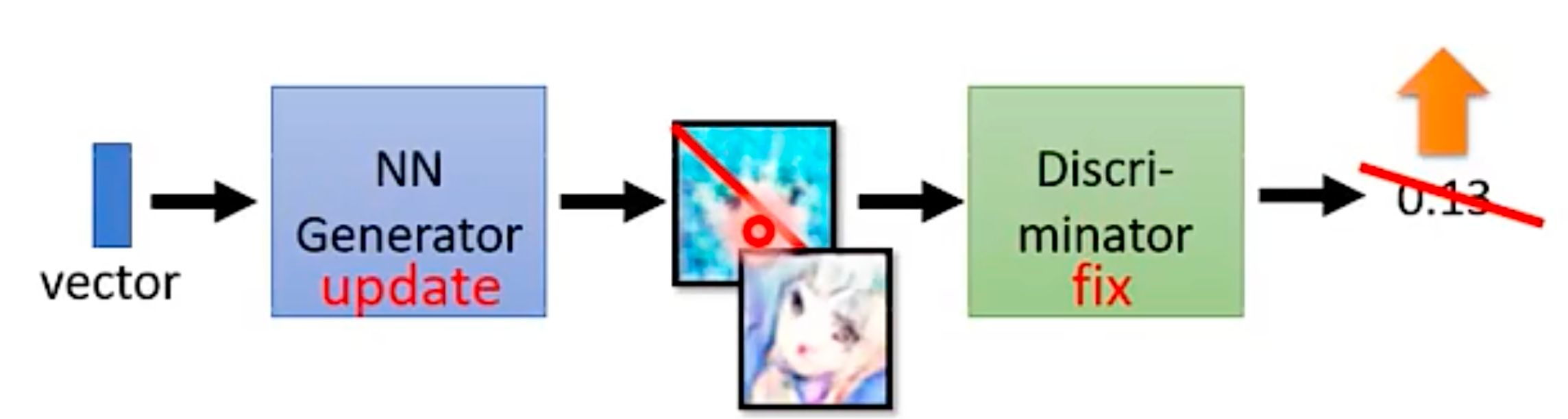
实际两个模块是在一个网络里面,只不过训练过程是交替训练的,即训练其中一个模块时另一个模块fix住。
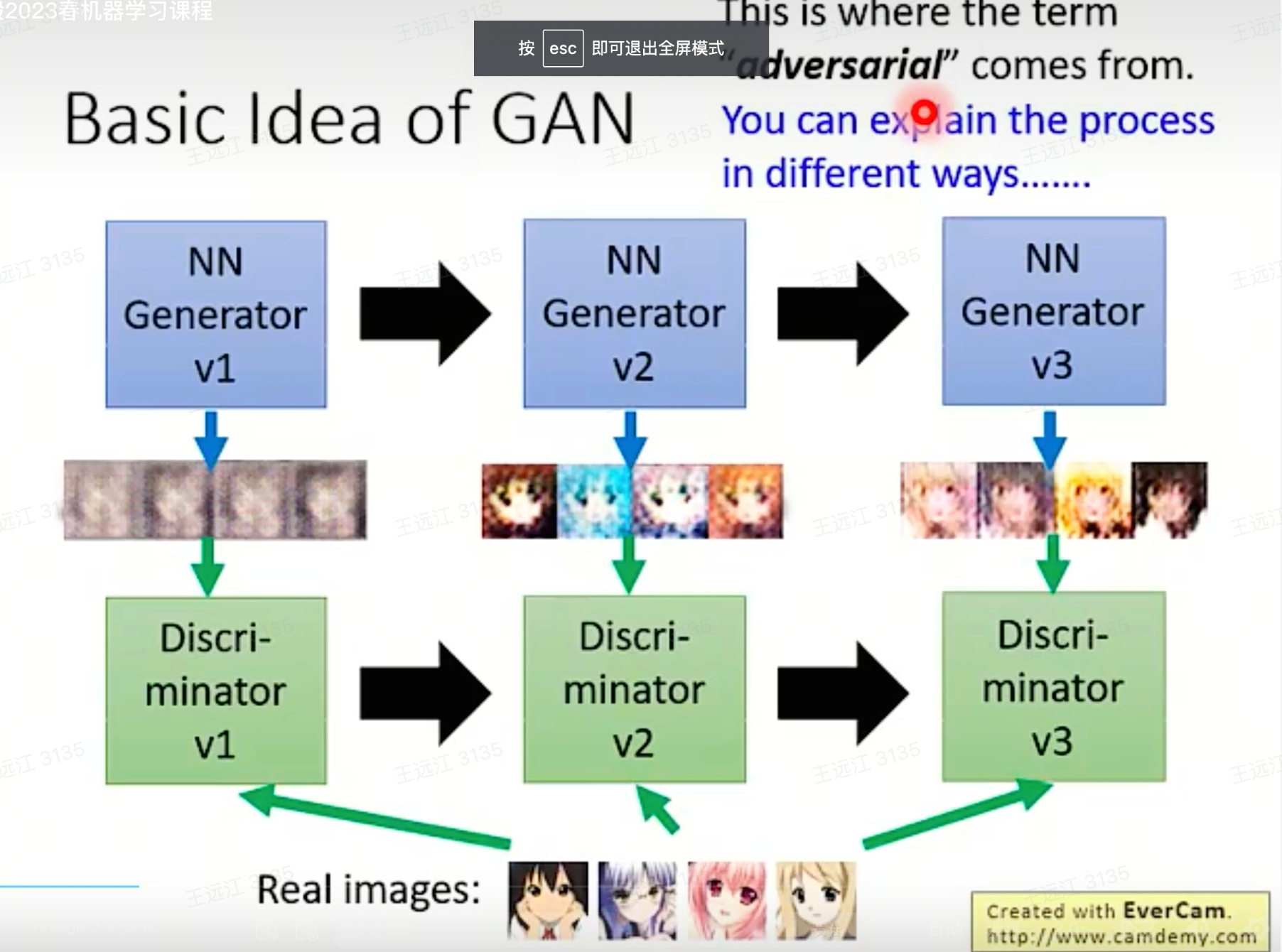

为什么必须要D?训练G的过程为什么fix D?
- 生成器仅能生成图像,无法知道真实数据的分布,而D可以方便地将图像映射到高维特征空间,从而比较方便衡量数据集之间的分布,并给G传递梯度告诉其靠近真实数据分布的优化方向。
- G在生成图像过程中是没有办法知道自己要生成的图像的全局信息,而D一开始就可以获取到图像全局信息,比较容易判断图像质量与改进方向。
如果训练G过程不fix D,那么D就会通过自身参数更新来过拟合图像真假判断的任务,不利于生成器的训练。
为什么必须要G?
D本质上还是一个判别任务,而非生成任务,而我们的目标是生成内容,所以必须要有生成器。
VQ-GAN Method
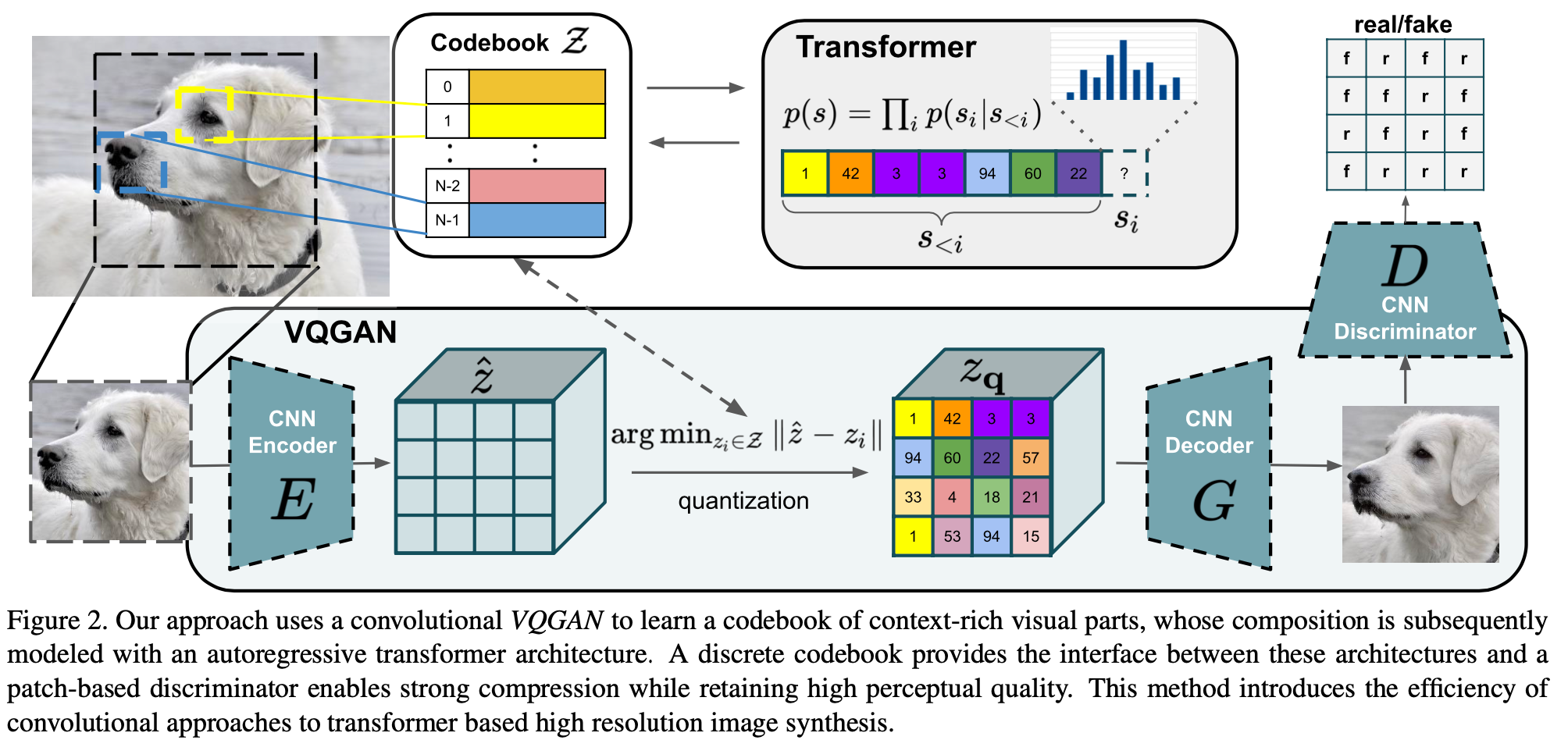
AE的训练
类似于之前VQ-VAE的训练过程,即AE + embedding space的聚类。

整体Loss

其中,\(L_{rec}\)为重建Loss,这里使用的是LPIPS(Learned Perceptual Image Patch Similarity),这种衡量图像间相似度的方法,使用预训练的深度神经网络(如 VGG、AlexNet)提取图像特征,并在特征空间计算相似度。
Transformer
- latent feature仍然保持spatial信息,每个cell上embedding特征在codebook里面都有唯一编号,这使得一个latent feature可以映射为一个sequence序列,再使用seq2seq的Transformer对latent feature进行特征融合。优势是可以在低分辨率的latent space进行特征融合,使得即使高分辨率图像的生成也能充分融合long-range的context。
- 方便conditional信息融合:transformer另一个优势是conditional信息也可编码为codebook编号,再利用Transformer auto-regressive来生成图像。
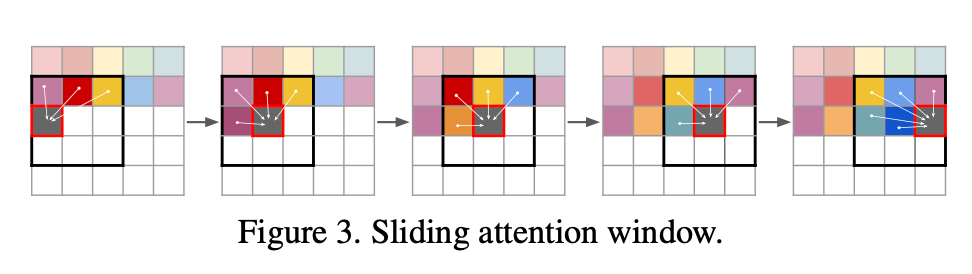
实际生成过程并没有完全使用所有前序code编码,而是使用一个sliding windows中编码生成某个coding embedding参见下图。个人理解是利用了CNN的位置归纳偏置简化了计算。
CodeReading
以SD官方代码中autoencoder_kl_32x32x4.yaml来说明VAE的训练实现。
AutoencoderKL
AE的模型结构参考这三个函数:
- encoder是一个ResNet结构,用来将原图下采样为yaml中配置的特征图latent feature
- quant_conv与post_quant_conv作为latent feature前后处理的普通conv理解即可
- posterior是根据每个样本生成的统计分布或者从分布中采样的一个DiagonalGaussianDistribution类的实例
def encode(self, x):
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
return posterior
def decode(self, z):
z = self.post_quant_conv(z)
dec = self.decoder(z)
return dec
def forward(self, input, sample_posterior=True):
posterior = self.encode(input)
if sample_posterior:
z = posterior.sample()
else:
z = posterior.mode()
dec = self.decode(z)
return dec, posterior
AE的训练过程参考training_step,其中optimizer_idx从pytorch_lighting中获取,即下面配置了几个optimizer,则会轮流输入对应的optimizer_idx分别用loss更新对应的optimizer,所以会依次更新AE的参数(即generator),以及Discriminator的参数
def training_step(self, batch, batch_idx, optimizer_idx):
inputs = self.get_input(batch, self.image_key)
reconstructions, posterior = self(inputs)
if optimizer_idx == 0:
# train encoder+decoder+logvar
aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
last_layer=self.get_last_layer(), split="train")
self.log("aeloss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False)
return aeloss
if optimizer_idx == 1:
# train the discriminator
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
last_layer=self.get_last_layer(), split="train")
self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False)
return discloss
def configure_optimizers(self):
lr = self.learning_rate
opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
list(self.decoder.parameters())+
list(self.quant_conv.parameters())+
list(self.post_quant_conv.parameters()),
lr=lr, betas=(0.5, 0.9))
opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
lr=lr, betas=(0.5, 0.9))
return [opt_ae, opt_disc], []
DiagonalGaussianDistribution
- 无参数,每次iter动态生成,以quant_conv出的feature作为初始化,分解为mean与var
- sample(): 根据mean与var采样出的feature
- kl(): 根据mean与var计算出KL散度
- nll(): Negative Log Likelihood,用来根据mean与var计算高斯分布的似然
- mode(): "众数",高斯分面的均值、中位数、众数为同一个值,所以这里直接return mean
LPIPSWithDiscriminator
训练VAE Loss Function
- 初始化: 包含了带可学参数的NLayerDiscriminator的定义
- forward:
- 重建loss:包含重生成与原图之间的L1相似度与LPIPS相似度
- 分布loss:posteriors中的高斯分布与标准正态分布的距离
- optimizer_idx == 0时,discriminator仅用来给VAE生成图打分
- optimizer_idx == 1时,用discriminator分别对真实与生成图打分,学到真实/生成样本的判别能力
总结
- 可以本节分析的SD中的VAE实际并没有使用VQ(vector quantized)的方式训练,而是直接连续采样
- VAE是作为GAN中的Generator来进行训练的
Experiment

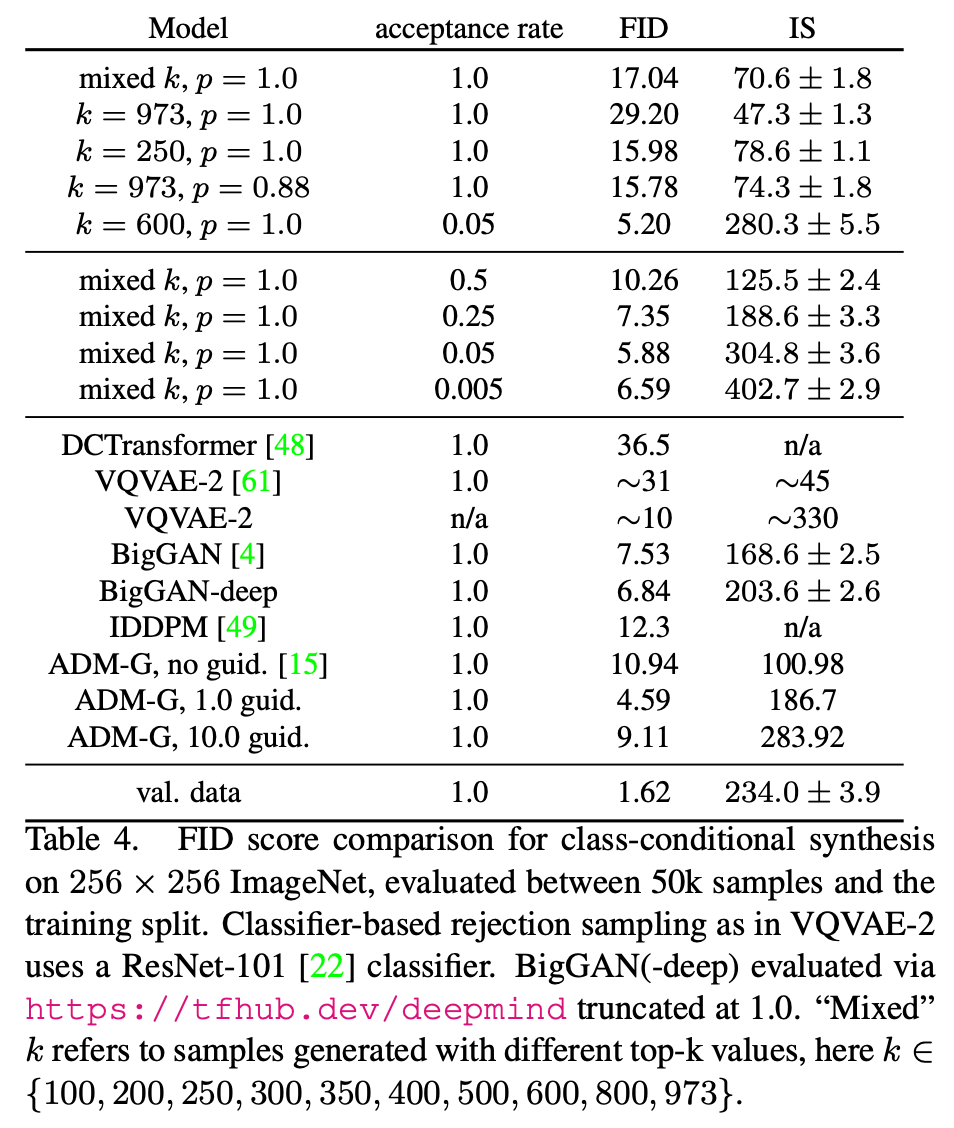
总结与发散
对于本文motivation上的理解:
利用CNN的位置归纳偏置建立context rich codebook(因为CNN提取的特征能够保持spatial信息,所以codebook也具有spatial信息,并且每个cell包含了一定context语义信息)
利用Transformer长时序能力生成生高分辨率图像(Transformer本身就有长时序优势,在这里面Transformer应用于低分辨率的latent feature生成,再Decode为高分辨图,减轻了计算量与生成难度)
整体理解,比较类似于VQ-VAE,不同点是:
1.重建后的图像是用adversarial loss监督,而VQ-VAE是直接使用重建Loss;
2.直接将latent feature每个embedding映射为编码,通过transformer seq2seq模型生成编码序列来生成图像,VQ-VAE直接训练了一个PixelCNN生成特征。
相关链接
link
https://zhuanlan.zhihu.com/p/515214329
https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.php
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18102912

 浙公网安备 33010602011771号
浙公网安备 33010602011771号