[Paper Reading] LVM: Sequential Modeling Enables Scalable Learning for Large Vision Models
LVM: Sequential Modeling Enables Scalable Learning for Large Vision Models
LVM: Sequential Modeling Enables Scalable Learning for Large Vision Models
时间:23.12
机构:UC Berkeley && Johns Hopkins University
TL;DR
本文提出一种称为大视觉模型(LVM)的方法,该方法以"visual seqence"为底层元数据来表示任何pixel级别的训练数据(图像、视频、分割图以及深度图),通过AR(auto-regressive)的方式来构建训练任务。推理时以"visual prompt"的形式来完成各类视觉任务。
Method
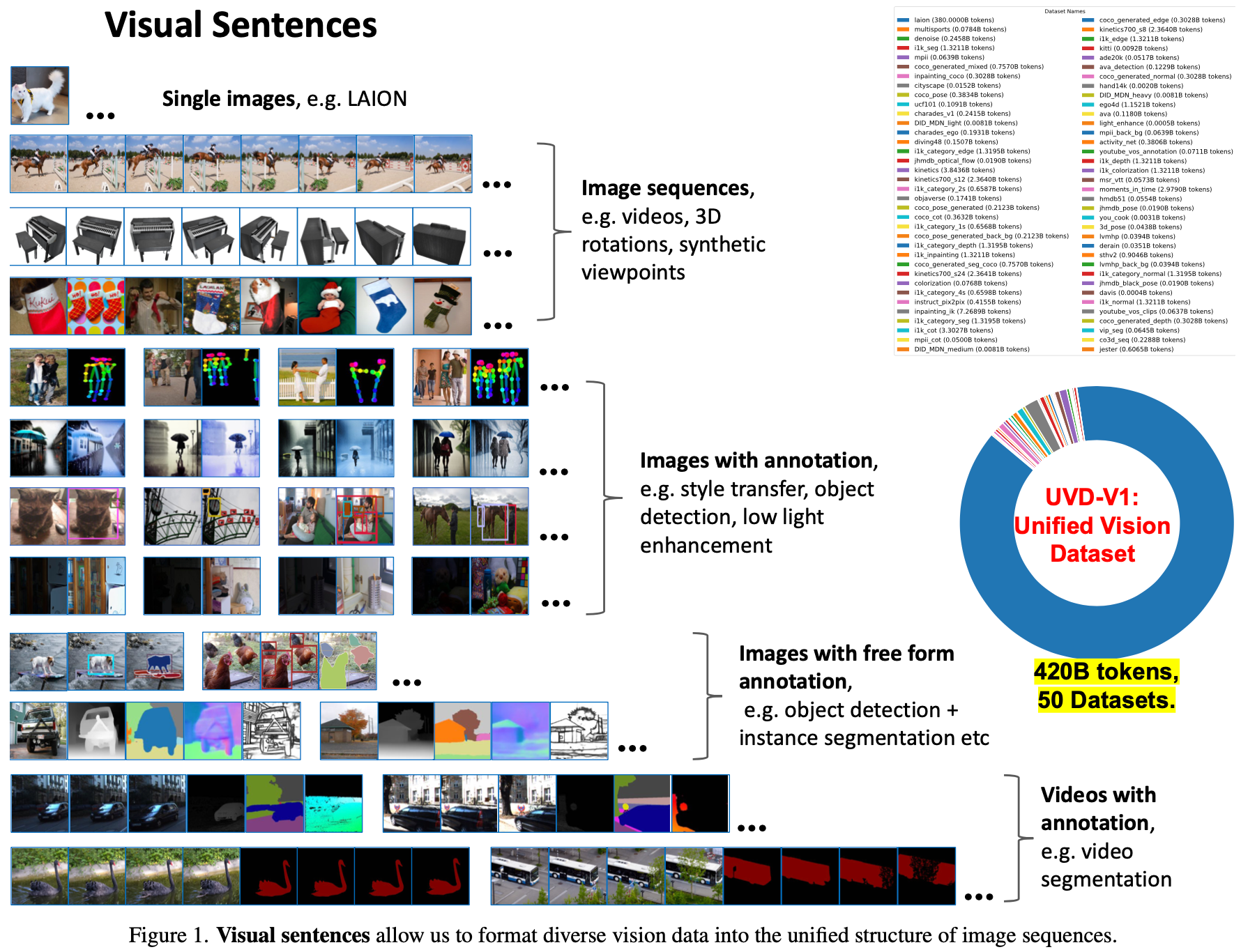
visual seqence能够将多种多样视觉数据统一为元数据格式。
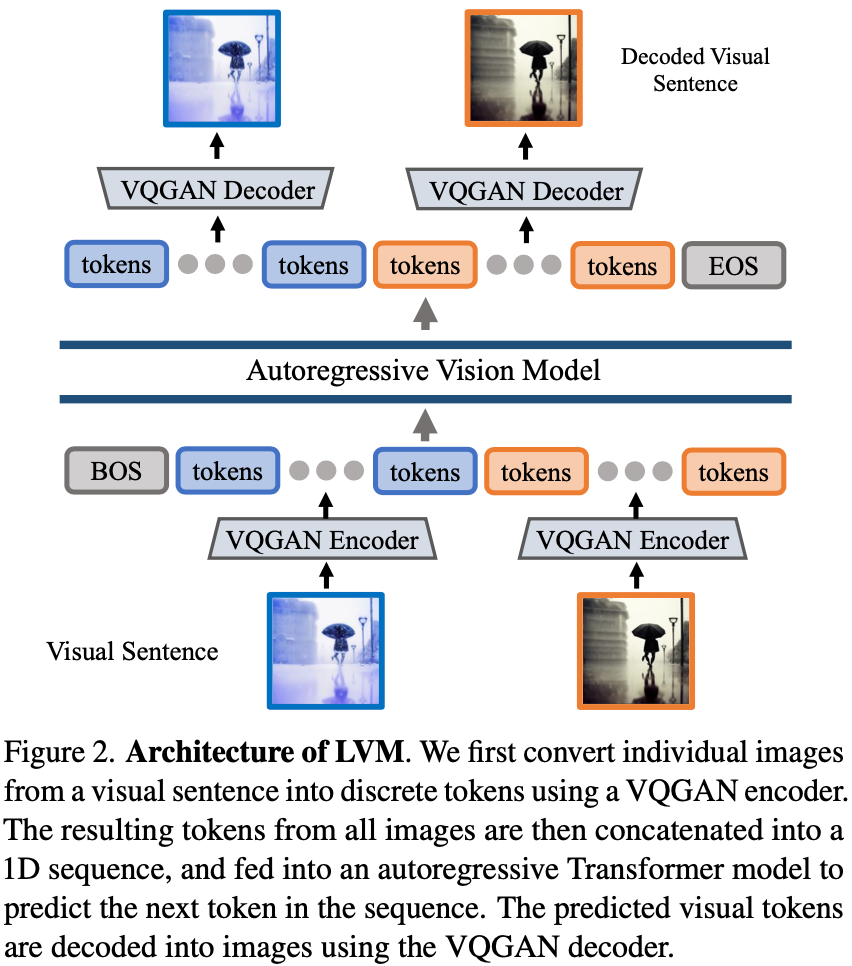
LVM有两个部分组成,一是visual sequence空间与图像之间相互转的VQ-GAN,二是AR预测image tokens的transformer。这两个部分是相互独立训练的。
ImageTokenization
作者使用LAION 5B训练的VQ-GAN作为toeknizer。原理类似于stable diffusion用的VQ-VAE。
visual sequence的序列建模
经过上一步抽取到visual sequence之后,后续的步骤与基于AR(autoregressive)的LLM几乎相同,即使用sequence前面的token逐渐预测整个visual sequence。具体实践上,作者使用LLaMA作为基本框架,context length设定为4096能够组成16张图像。模型在UVD v1(420billions,大约16亿图像)数据集上训练1个epoch。
Experiment
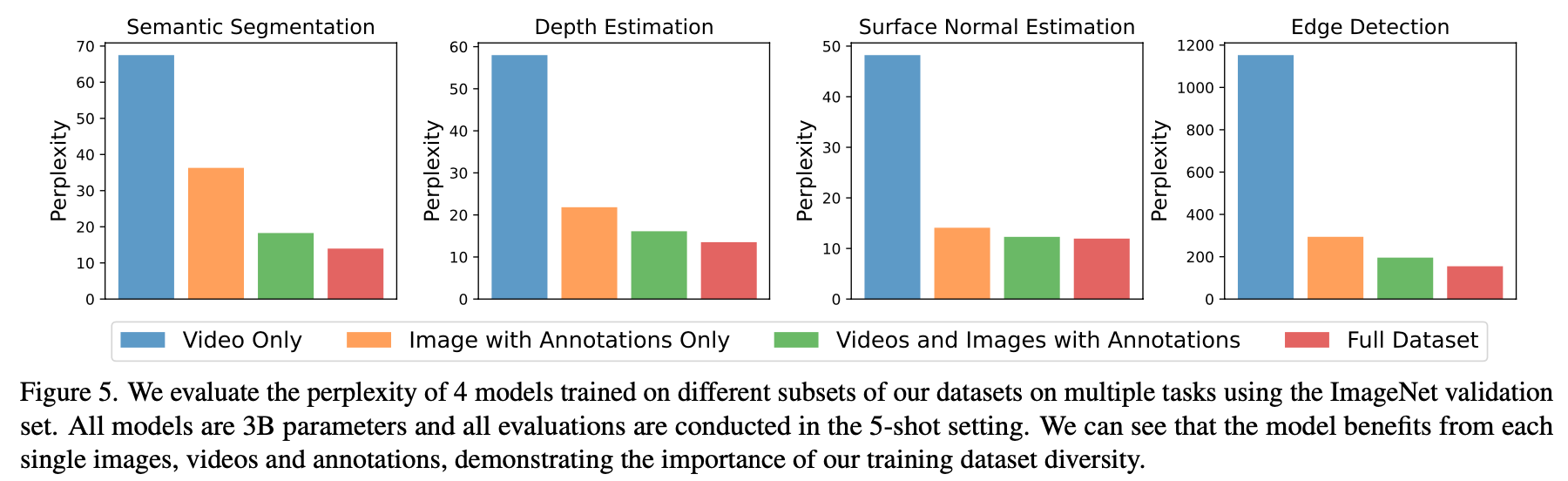
作者使用UVDv1中的纯video、纯image annotations以及混合(即完整数据集) 三类数据成分分别训练模型,使用5-shot promts在一些感知任务上测试(指标越低越好),可以看出所有数据成分都使用效果最佳。
Q: 与supervied训练方法对比。
作者没有在COCO之类的经典感知测试集上与SOTA方法对比,但是在Pascal 3D+上Keypoint任务PCK达到81.2超过hourglass的68.0。
Unseen Tasks and Dataset. We present the results for keypoint detection on Pascal 3D+ [90], evaluated using the standard Percentage of Correct Keypoints (PCK) metric with a of threshold 0.1. Remarkably, LVM achieves a PCK of 81.2 without training on this dataset, demonstrating impres- sive generalization capabilities. In comparison, we show some existing task-specific model: StackedHourglass [61] scores 68.0 PCK, MSS-Net [43] achieves 68.9 PCK, and StarMap [101] registers 78.6 PCK.
总结与发散
暂无
相关链接
引用的第三方的链接
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18098999

 浙公网安备 33010602011771号
浙公网安备 33010602011771号