
[基础] DiT: Scalable Diffusion Models with Transformers
名称
DiT: Scalable Diffusion Models with Transformers
时间:23/03
机构:UC Berkeley && NYU
TL;DR
提出首个基于Transformer的Diffusion Model,效果打败SD,并且DiT在图像生成任务上随着Flops增加效果会降低,比较符合scaling law。后续sora的DM也使用该网络架构。
Method
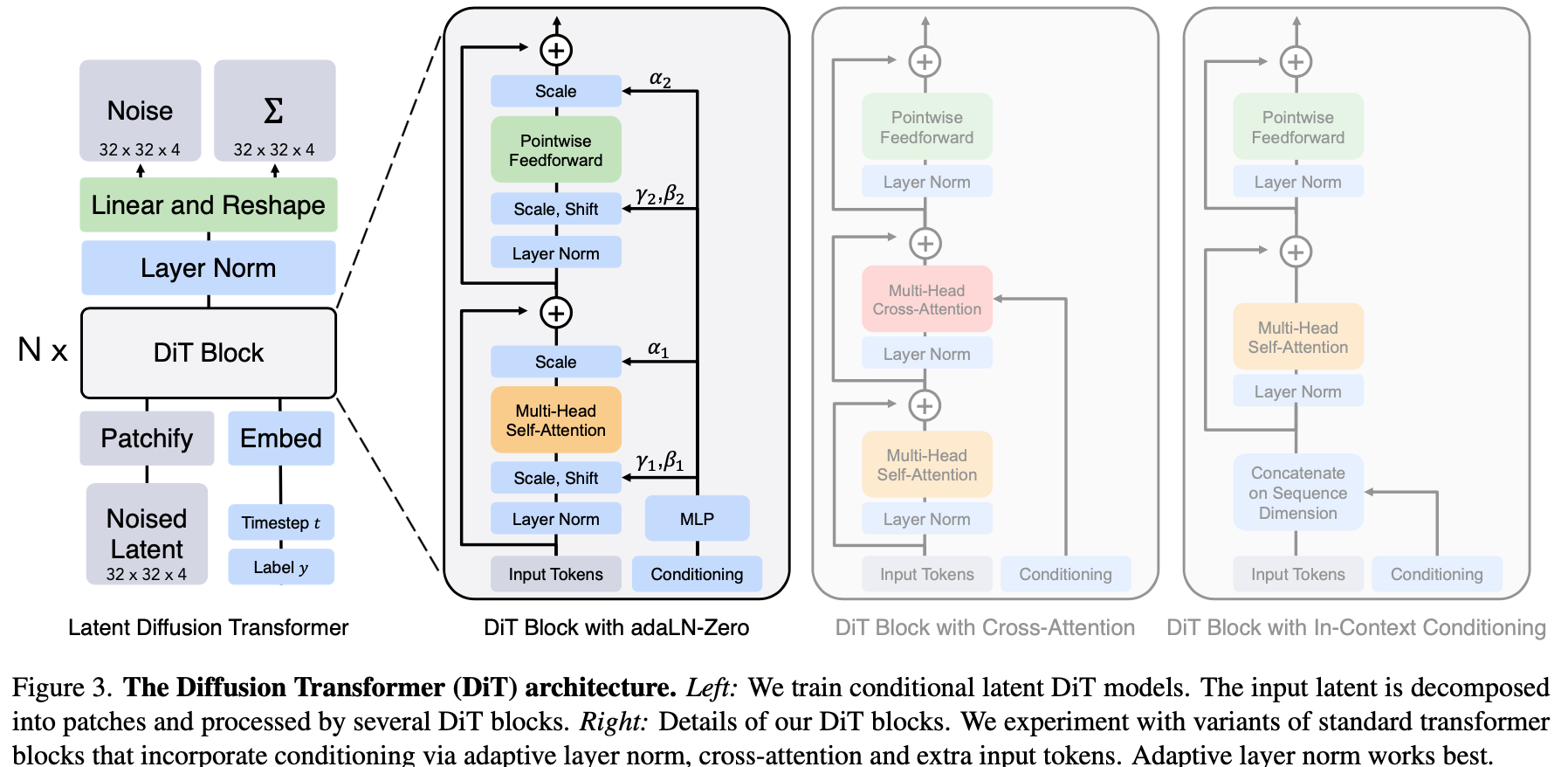
网络结构整体参考LDM,只不过将latent diffusion中的UNet替换为ViT,image与latent space之间编解码复用现成的基于卷积的VAE。DiT网络结构如下图所示,作者尝试了多种DiT blocks来编码condition信息,比如,cross-attention, in-context conditioning(直接concat with embeding tokens),最终发现adaLN-Zero block效果最好。
adaLN-Zero block
adaLN的全称是adaptive layer norm。layer norm是"逐样本"将均值方差替换为可学习参数beta/gamma的方法,而这里adaptive指得是额外学习一个逐channel的参数alpha。Zero指得是将residual连接的前一层MLP的norm中alpha初始值设定为0,起到Identity的作用,个人理解,这么做相当于在网络学习前期去掉了一些层,降低了前期学习复杂度加速收敛。更详细的解释参考论文
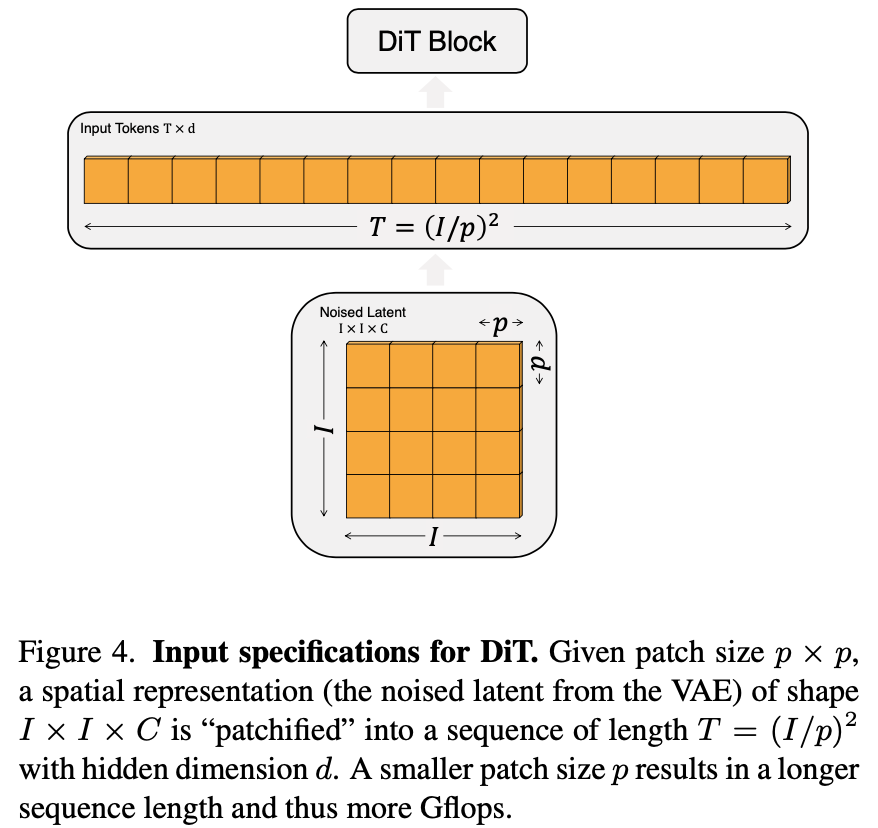
Patchify
类似于ViT中的图片切块出embedding的操作,只不过这里专门起了一个名字。如下图所示,DiT的输入尺寸是一个I x I的保留spatial shape的noise latent feature,被切成大小为pxp的patch,再将patch抽成embedding,把所有embedding组成一个序列的tokens。
网络架构
Q: UNet的上采样如何使用Vit实现?
Transformer的Decoder输出序列的长度为I x I x 2,被reshape成为I x I的噪声以及方差。
Experiment
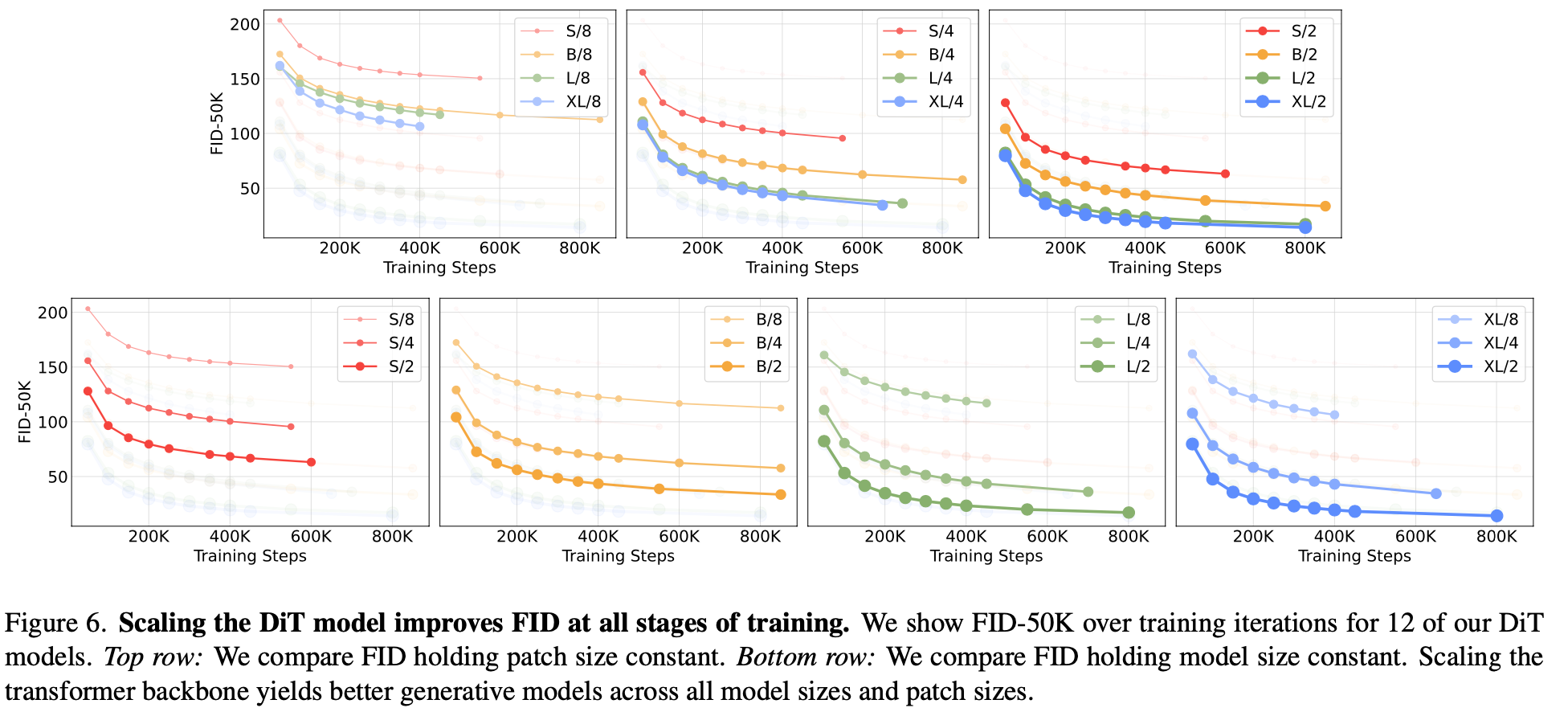
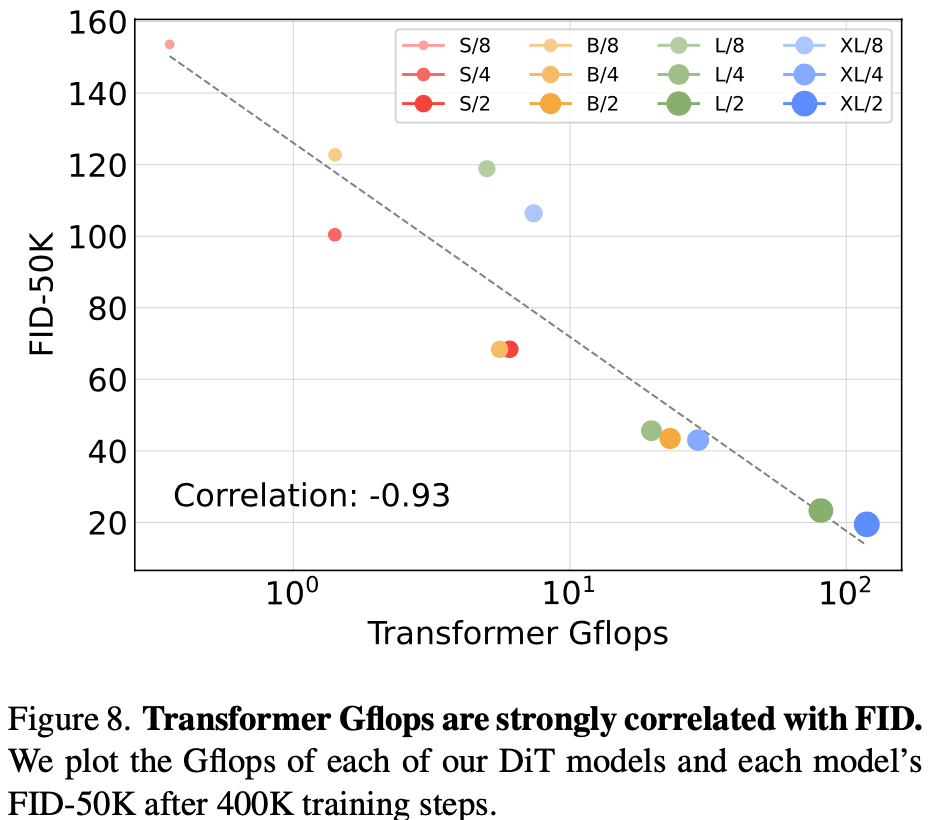
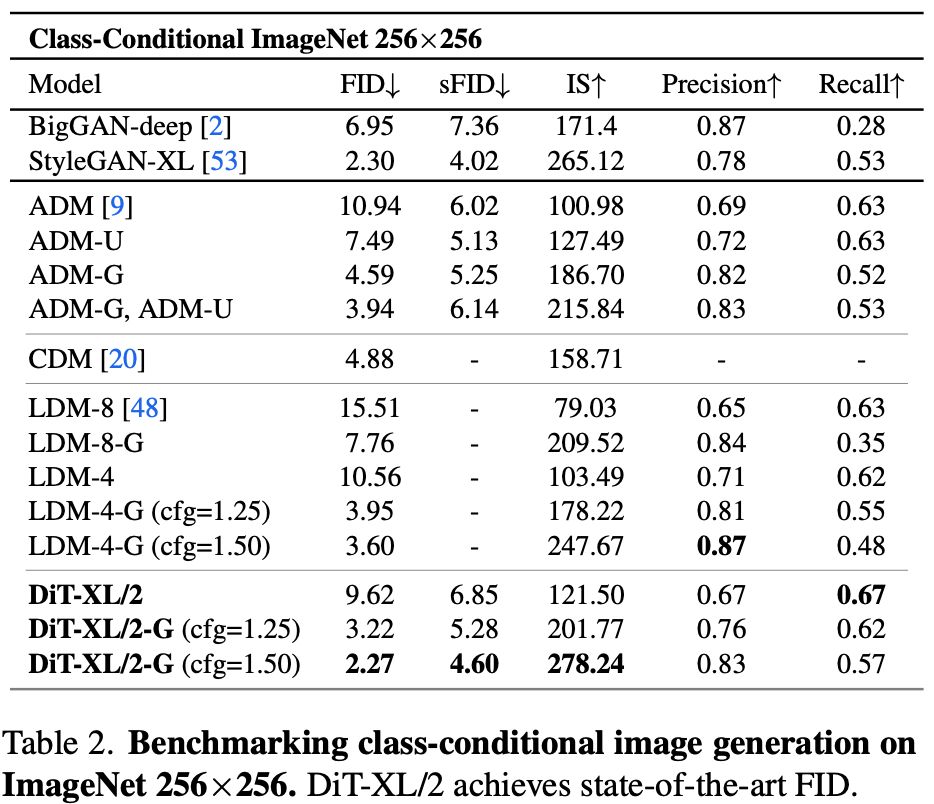
总结与发散
属于LDM上改进工作,将UNet替换为transformer,由于实验结果符合scaling law,比较适合大力出奇迹。
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18087204

 浙公网安备 33010602011771号
浙公网安备 33010602011771号