[Paper Reading] DALLE3: Improving Image Generation with Better Captions
DALLE3: Improving Image Generation with Better Captions
DALLE3: Improving Image Generation with Better Captions
时间:23/10
机构:OpenAI
TL;DR
本文认为text-image效果不够好的原因主要是训练集中text噪声太大,不够精确。本文展示了高描述性的text可以从本质上提升text-image任务的效果。本文没有开放DALLE3的全部训练细节,但展示了关键提升策略。
Method
captioner
利用已有训练集中的text与image信息,作者训练一个langue model作为captioner,不同于一般的LM,该captioner除了输入text之外还需要加入CLIP image embedding。这样,作者在一个小型数据集上训练了两个captioner,一个用来预测简短主题caption称为SSC(short synthetic captions),另一个称为DSC(descriptive synthetic captions),可以生成图像细节描述,包括环境背景等。关于如何训练captioner作者没有详细描述,感兴趣可以看一些网友的分析。
Experiment
Q: 仿真数据与真实数据混合比例对于效果的影响?
首先一个问题是,仿真数据那么好,为什么还需要和真实数据混合呢?因为在text2image这个任务上,生成效果很容易过拟合到训练text的分布上(比如,训练时所有text以空格开头,那推理时,如果没有以text开头,结果会出现异常)。最好的text分布就是人工标注的text,即Ground truth。GT缺少细节描述,仿真数据分布与人类输入text有gap,所以需要两者混合相互弥补。
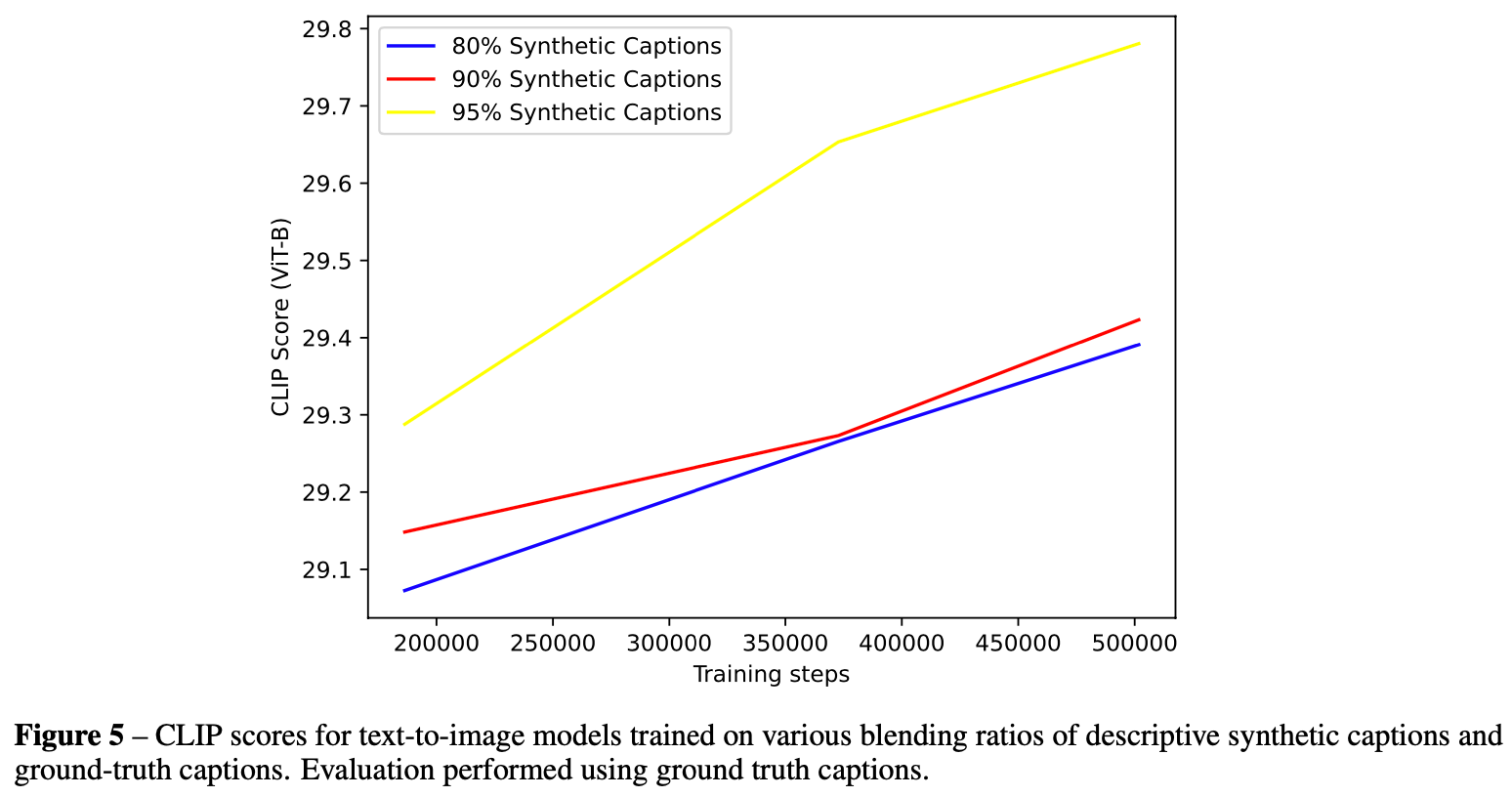
结论:混入95%的DSC效果最佳(DALLE3就是这个配比训出来的)
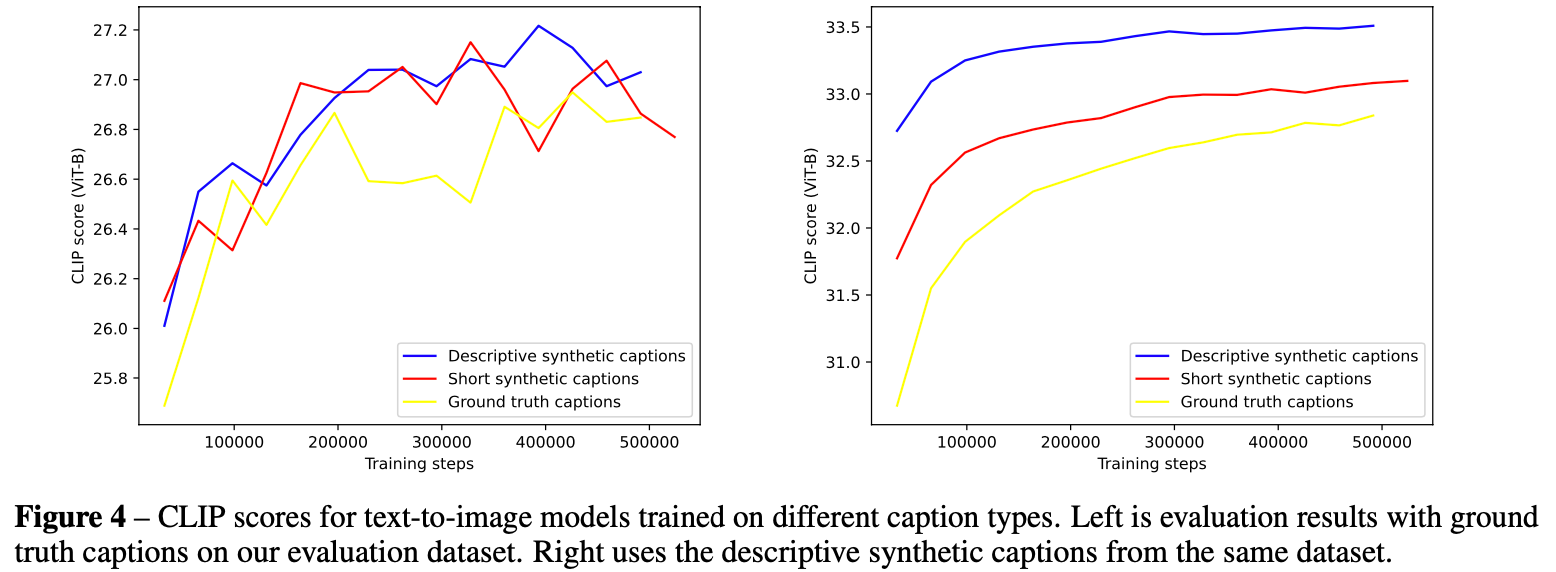
Q: 使用训练集使用哪种caption效果更好?
结论:DSC > SSC > GT。评测时如果都不加入GT text,差距更明显。
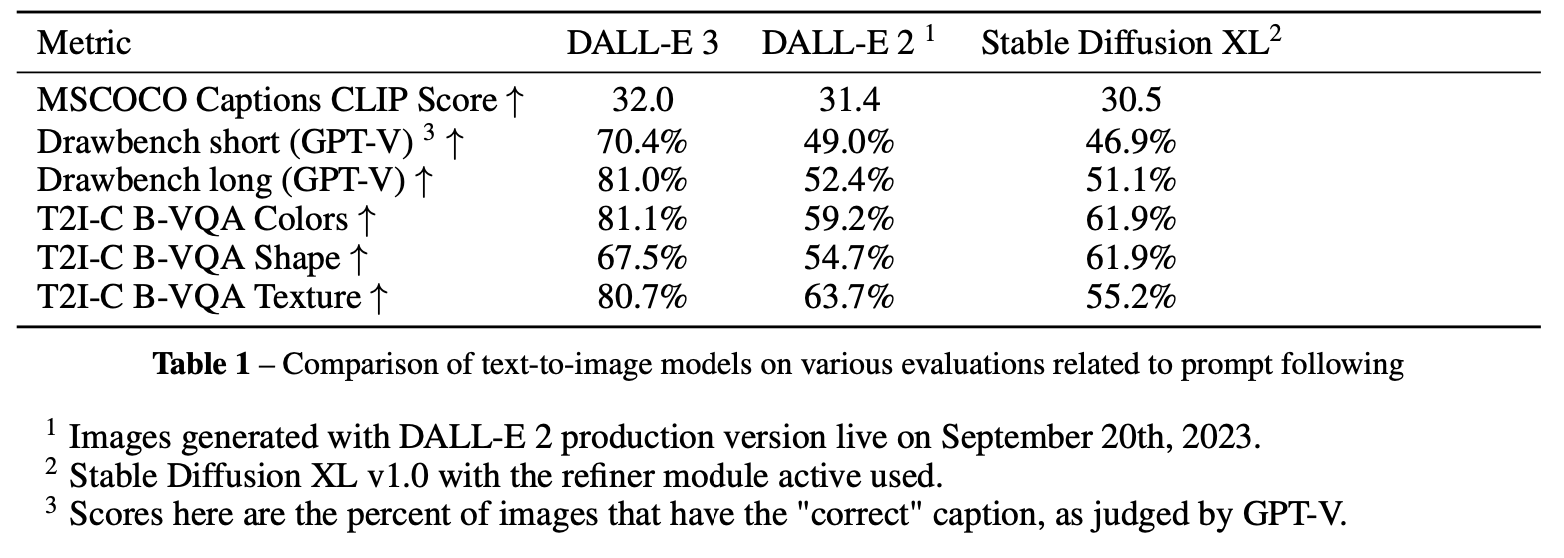
Q: 与其它Text2image方法的效果对比。

总结与发散
OpenAI没有放出DALLE3的全部干货,不过训练集中的caption分布丰富性也确实是text2image目前核心问题之一。
相关链接
https://blog.csdn.net/u012193416/article/details/134358194
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18085065

 浙公网安备 33010602011771号
浙公网安备 33010602011771号