
[Paper Reading] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
GLIDE(Guided Language to Image Diffusion for Generation and Editing)
时间:22/03
机构:OpenAI
TL;DR
本文研究使用Diffusion Model做图像生成过程,如何更好地加入conditional信息。主要尝试两种方法: CLIP-guidance, Classifier-free guidance,并且证明了后者效果更佳。文本是后续DALLE2的重要baseline。
Method
Classifier-free guidance
不同于classifier guidance直接将text信息c加入noise prediction每一步进行引导,classifier-free方法直接将c作为先验输入模型。另外,部分text/label信息替换为空,以防止diffusion生成图像过程过度依赖于text/label信息。s表示替换的比例(比如,s=1时就完全不替换,s=0.5时表示替换一半为空序列,文中超参数是替换了20%为空序列)
这个做法现在看好像很简单,不过之前给diffusion加condition不太容易,参考本文对比的ADM方法,使用classifier guidance需要在每一步使用分类器进行类别引导,非常麻烦参考。
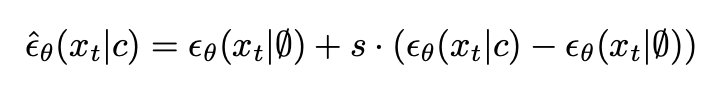
CLIP guidance
个人理解:diffusion model的reverse process每一步扩散都是在一个正态分布的mean附近采样,而CLIP guidance在这个mean附近增加一个扰动,该扰动与 f(x)和g(c)点积的梯度 有关。
直观的motivation:一些利用CLIP将文本特征融合到diffusion model中的方法,通常是对diffusion model reverse process过程中加过噪声的图像进行特征抽取,而CLIP在训练过程见到的却是清晰无噪的图像样本,这导致reserse process时图像与文本的特征并不是同分布,所以这类方法同常比较依赖数据增强来弥补这种分布差异。而本文reverse process过程加入CLIP guidance之后,不仅增加了text的condition,还增加了noise image的condition先验,缓解了该问题。上述这么处理也只能让diffusion model训练过程aware CLIP的image与text encoder。所以,后面作者提到又重新训练CLIP,让CLIP重新学习noise image的分布,称之为noise CLIP。
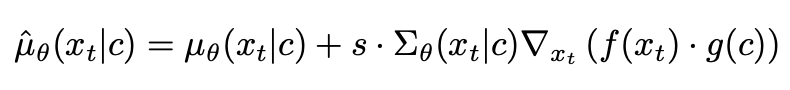
网络
整体网络结构参考OpenAI 21年一篇文章ADM,根据作者描述,使用两阶段的Diffusion model,第一阶段扩散生成64x64分辨率的图像,第二阶段是一个64 -> 256的上采样扩散模型。text信息使用了classifier-free方法进行编码训练,这样模型在输入空condition情况下也能正常工作。多模态信息融合使用上CLIP guidance方法(也叫noise CLIP)。
Experiment

总结与发散
类似于stable diffusion(同期工作,SD是21年12月放出),特别是加condition的方式,不过还没有像stable diffusion那样直接在latent space扩散,而是使用低分辨率DM,再使用提升分辨率DM。另外,noise CLIP的做法听起来比较make sense。
相关链接
ADM
如何评价OpenAI的工作GLIDE? - CVHub的回答 - 知乎
https://www.zhihu.com/question/507688429/answer/2829764157
资料查询
折叠Title
FromChatGPT(提示词:XXX)本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18080262

 浙公网安备 33010602011771号
浙公网安备 33010602011771号