[基础] CLIP
Learning Transferable Visual Models From Natural Language Supervision
link
CLIP 全称 Contrastive Language-Image Pre-training
时间:21.02
机构:OpenAI
TL;DR
一种使用图文对做预训练的方法,影响力:打破传统人工标准类别Label的预训练方式。
Method

训练阶段:将图文样本对分别过Encoder抽取特征,一个大小为N的Batch内,属于同一组图文对为正样本对共N组,不同图文组成样本对为负样本共N^2 - N组,以此构建对比学习Loss。
推理阶段:将目标测试集所有类别标签使用Text Encoder抽取Embedding特征,图像特征用KNN来预测对应标签。
Code
论文中伪代码看得不是很明白,直接上源码:open_clip
Q:为什么需要算两次cross_entropy_loss然后再相加?
A:为了让每个样本能在其它卡的Batch中获取到更多的负样本对。比如,Text做为query时将其它卡的图像特征都拿到做负样本对,Image作Query时也把其它卡上的Text特征作为负样本对,那么这个两个Loss的值自然就不一样了。
def get_logits(self, image_features, text_features, logit_scale):
if self.world_size > 1:
all_image_features, all_text_features = gather_features(
image_features, text_features,
self.local_loss, self.gather_with_grad, self.rank, self.world_size, self.use_horovod)
if self.local_loss:
logits_per_image = logit_scale * image_features @ all_text_features.T
logits_per_text = logit_scale * text_features @ all_image_features.T
else:
logits_per_image = logit_scale * all_image_features @ all_text_features.T
logits_per_text = logits_per_image.T
else:
logits_per_image = logit_scale * image_features @ text_features.T
logits_per_text = logit_scale * text_features @ image_features.T
return logits_per_image, logits_per_text
def forward(self, image_features, text_features, logit_scale, output_dict=False):
device = image_features.device
logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale)
labels = self.get_ground_truth(device, logits_per_image.shape[0])
total_loss = (
F.cross_entropy(logits_per_image, labels) +
F.cross_entropy(logits_per_text, labels)
) / 2
return {"contrastive_loss": total_loss} if output_dict else total_loss
Experiment
ZeroShot效果已经超过FewShot Of其它SSL预训练方法了。
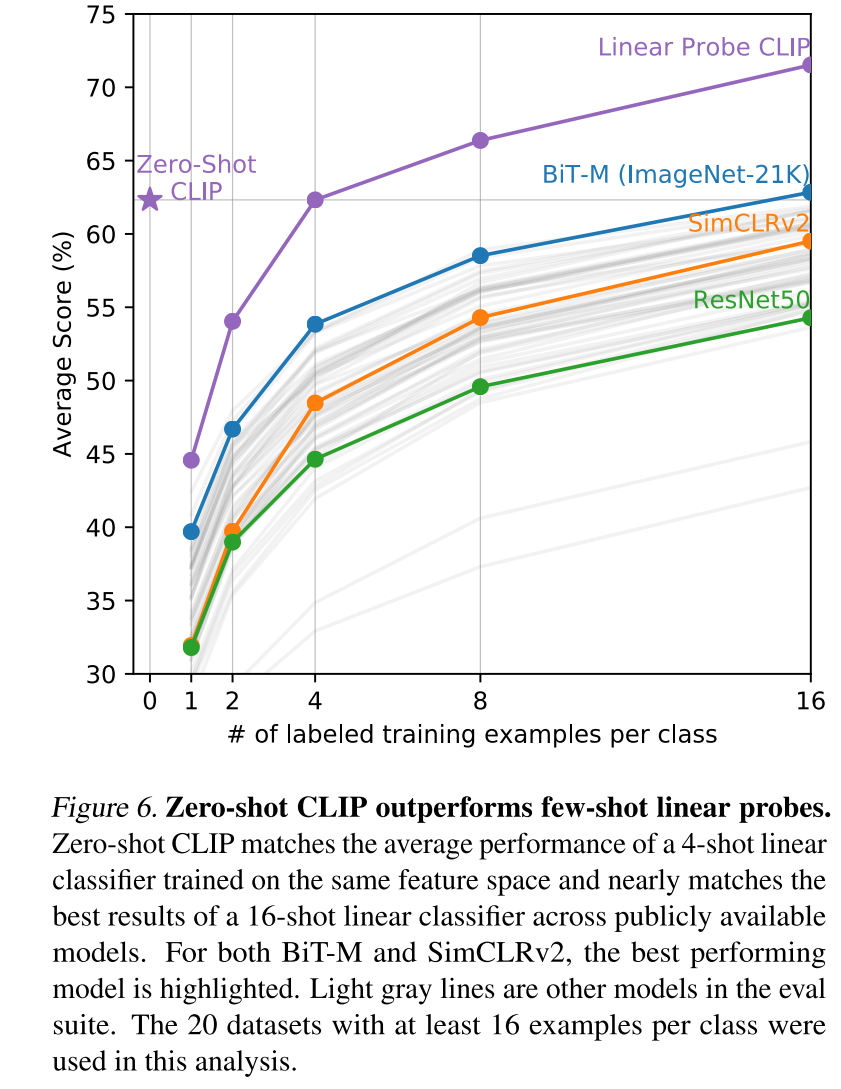
Conclusion
1.CLIP能充分利用大量图文样本作为图像与文本Encoder的预训练数据。
2.文章实验部分花了比较大篇幅证明了CLIP预训练的图像Encoder有SOTA级别的表征能力。
3.这种混合模态的预训练方式,在后续跨模态特征对齐过程中被广泛使用。
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18057979

 浙公网安备 33010602011771号
浙公网安备 33010602011771号