[基础] Vision Transformer
VIT: AN IMAGE IS WORTH 16X16 WORDS
TL;DR
首篇使用纯Transformer来做CV任务的文章。
Method
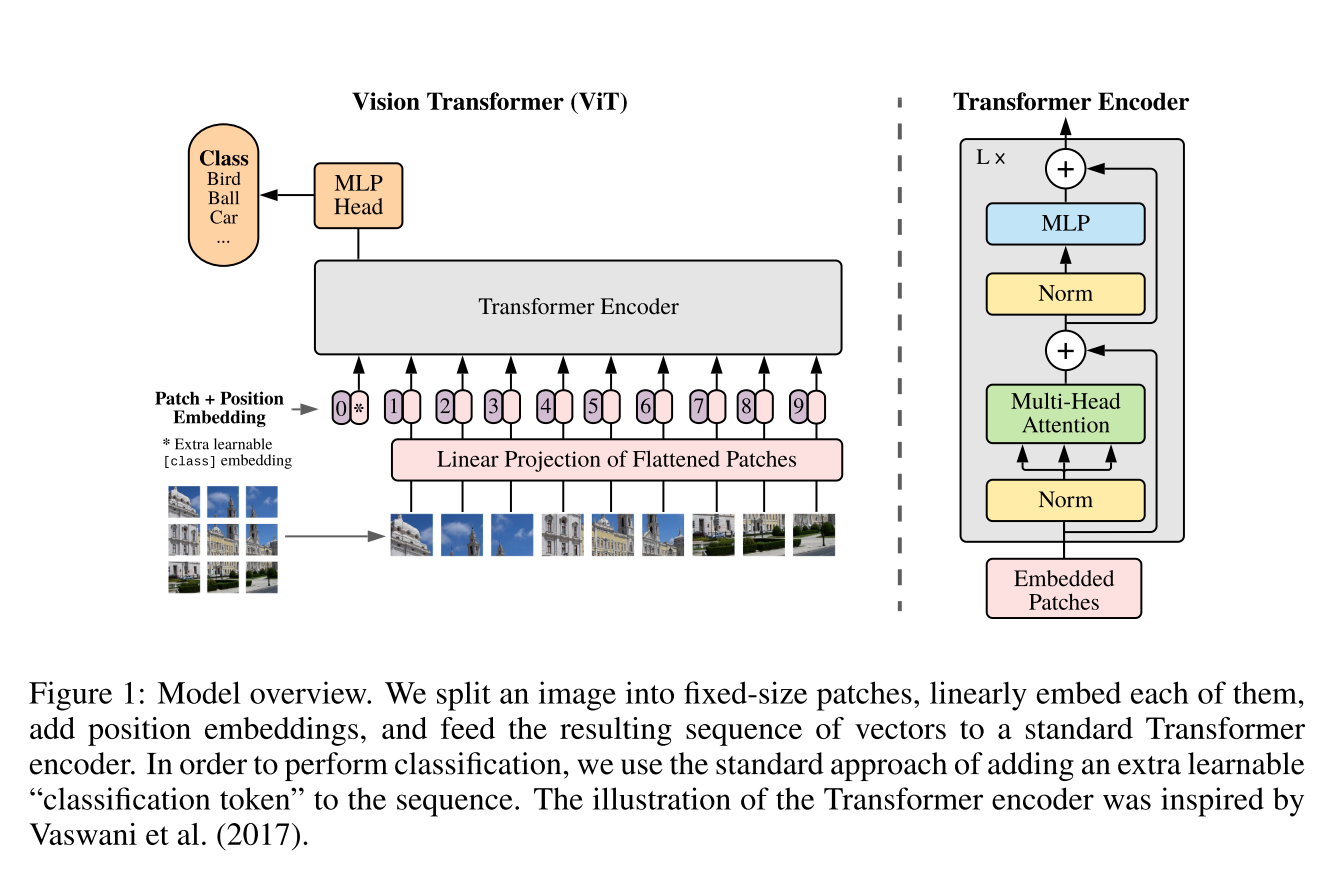
首先将图像拆成多个图片Patch,每个Patch通过LindearProjection变成embedding特征,使用Transformer的Encoder来聚合多个embedding。为了使用模型能够做分类任务,在Encoder输入部分会增加一个额外的Cls Token。
Cls Token
如果没有这个Token,那么Encoder从任何一个Patch Embedding对应的位置来输出类别都会破坏Patch之间对称性。于是使用cls token的位置来聚合其它Patch Embedding的特征信息,从而获取全局特征来分类。
![]()
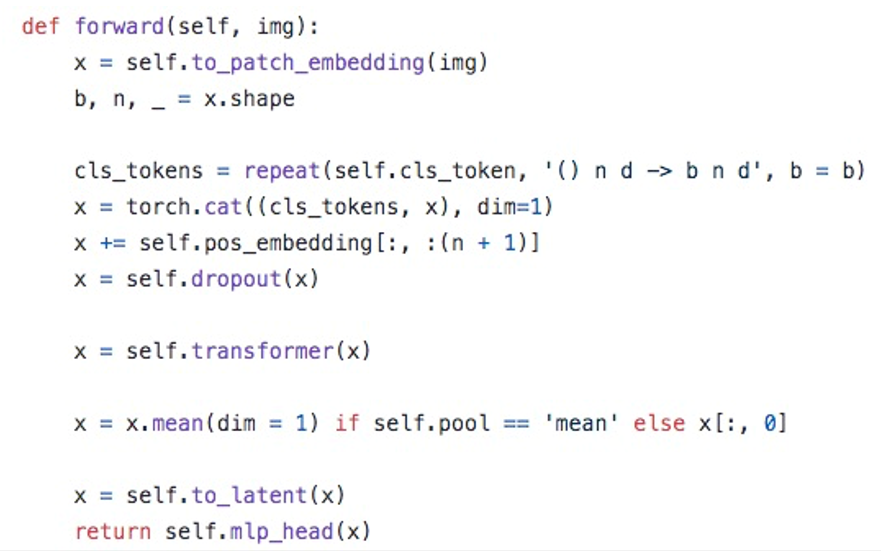
Code
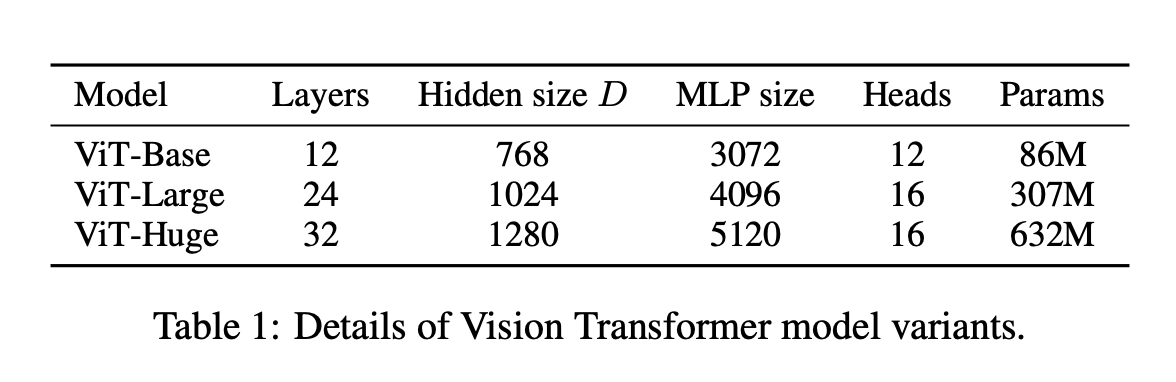
参数
Experiment
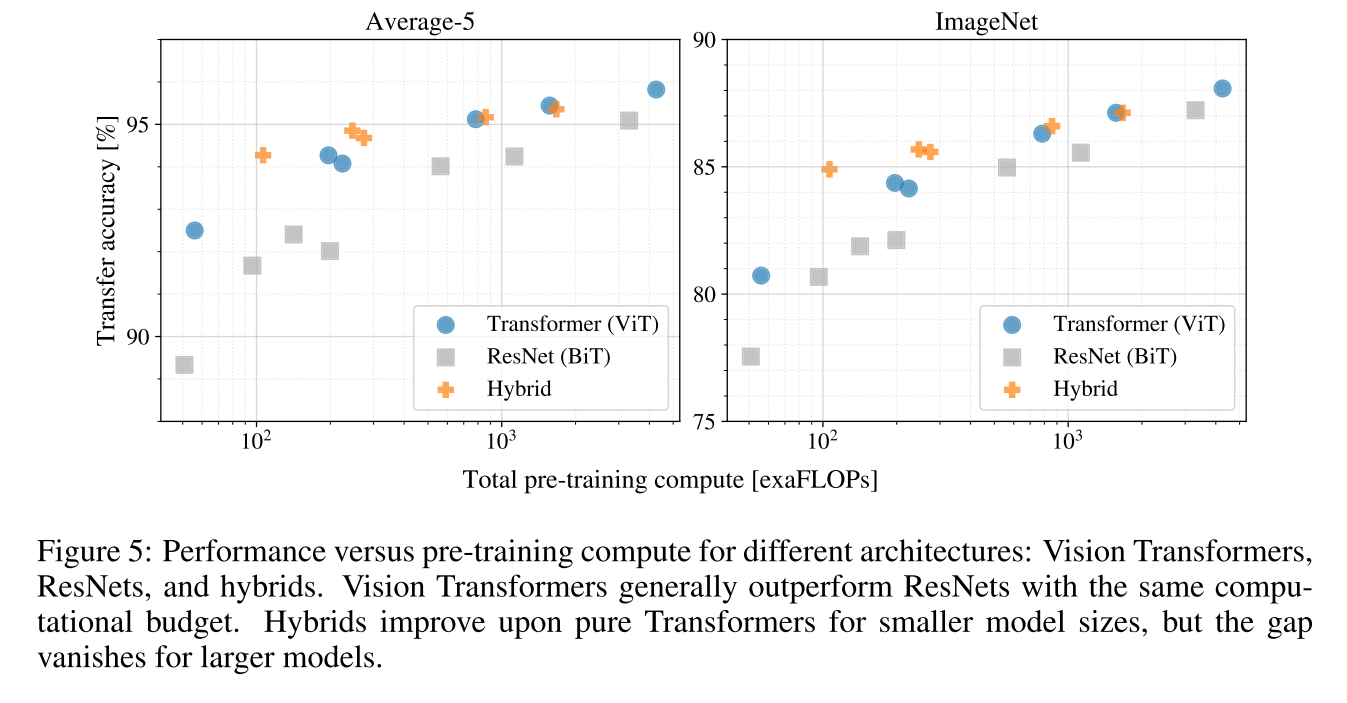
1.相同计算量情况下ViT优于CNN;
2.在计算量较小时Hybrid(ViT+CNN)有优势,但计算量变大之后融合CNN的优势就不存在了。
Conclusion
Q: 为什么Vision Transformer的上限要比CNN更高?
A:因为CNN有诱导偏差(Inductive Bias),即CNN由卷积作为基本单元构成,卷积无法改变特征2D相邻结构,每一层特征始终具有2D相邻关系,使得模型无法自主学习spatial信息。而ViT学习过程中局部特征由MLP提取,全局相关性由Self-Attention聚合,根据Self-Attention加权的原理,embedding之间本身没有位置相关关系,符合加法交换律,唯一的位置信息由Encoder输入时的Position Encoding提供,除此之外再无2D spatial信息,这使得ViT在学习少了一些Spatial上的诱导偏差。
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18055572

 浙公网安备 33010602011771号
浙公网安备 33010602011771号