[基础] Transformer
Transformer
 )
)
名称解释:
Self-Attention:
类似于CNN里面的Conv层,是Transformer中重复次数最多的特征提取Layer。
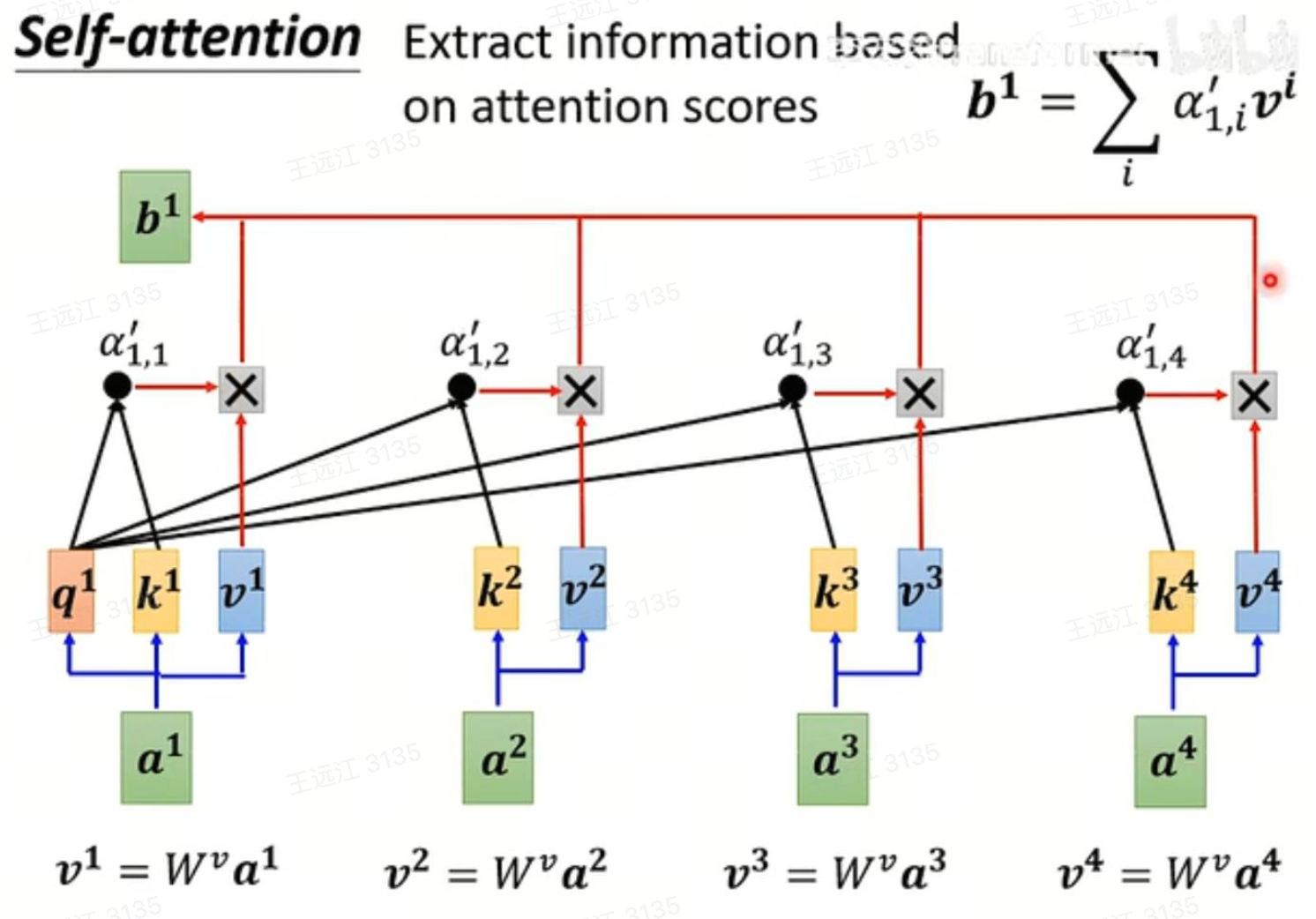
Multi-Head Attention:
相对于Self-Attention,将每个节点外接多个q、k、v head。

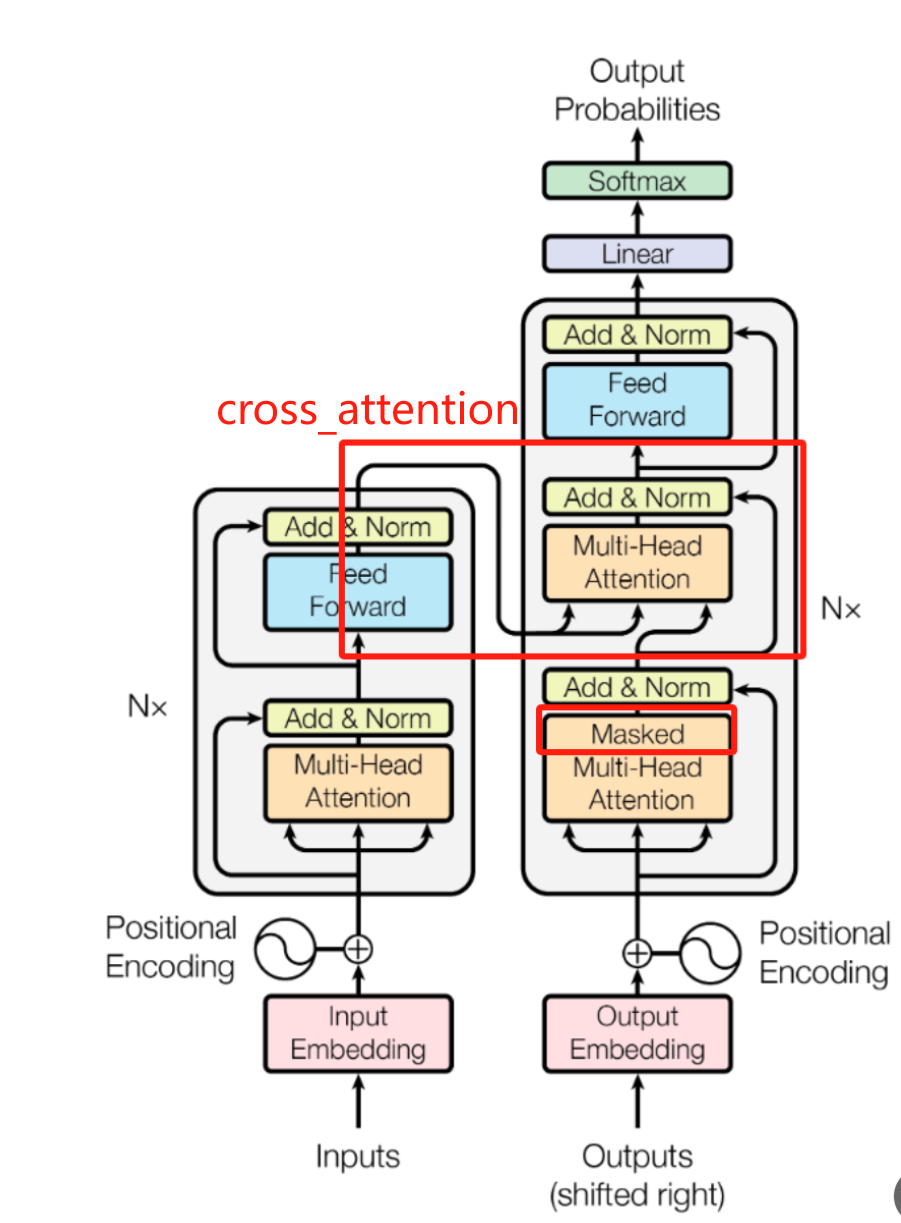
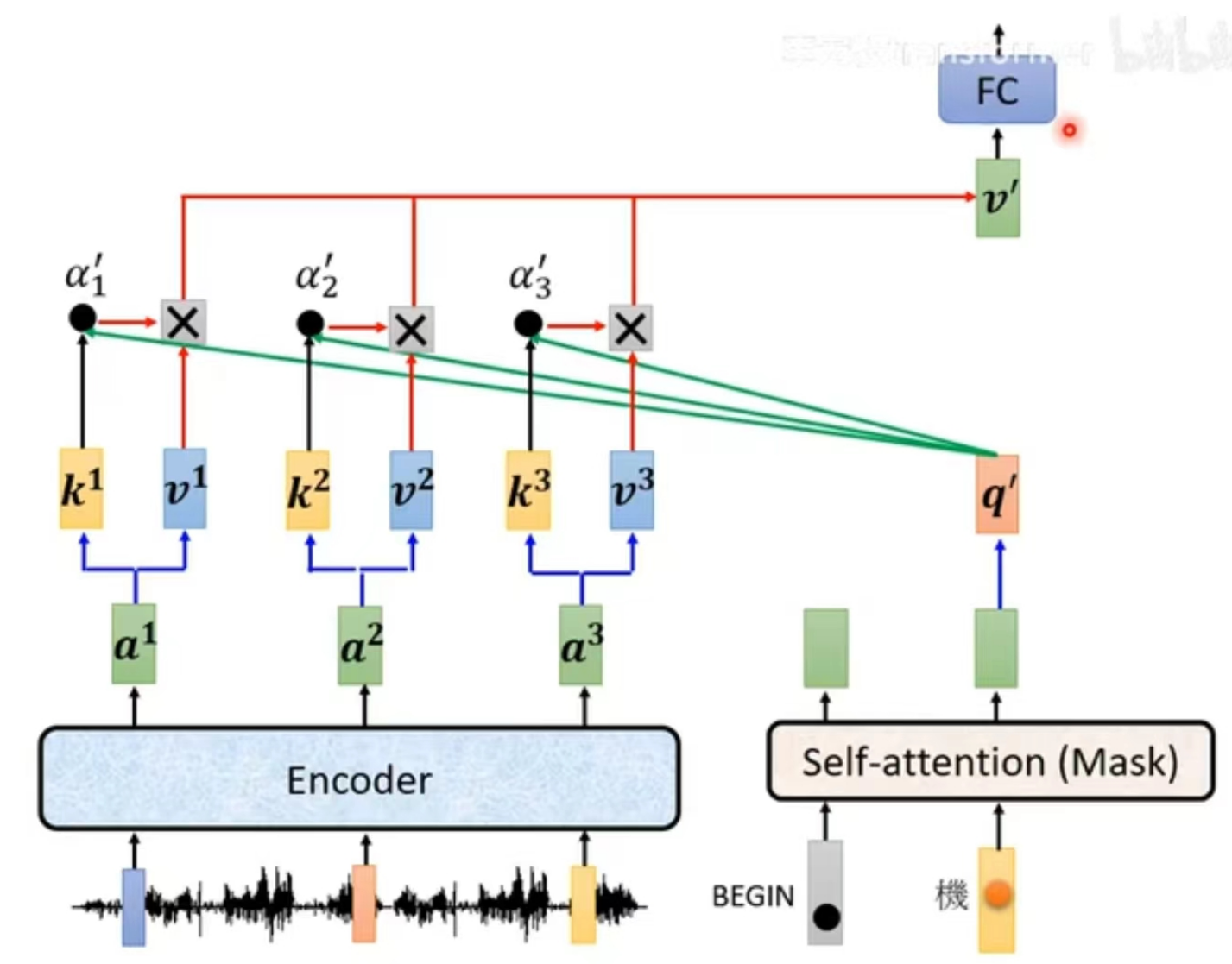
Cross Attention:
Decoder提取Encoder输出特征的桥梁,原理是用Decoder的q去query Encoder输出特征的k得到权重,并将Encoder所有输出特征v进行加权平均。
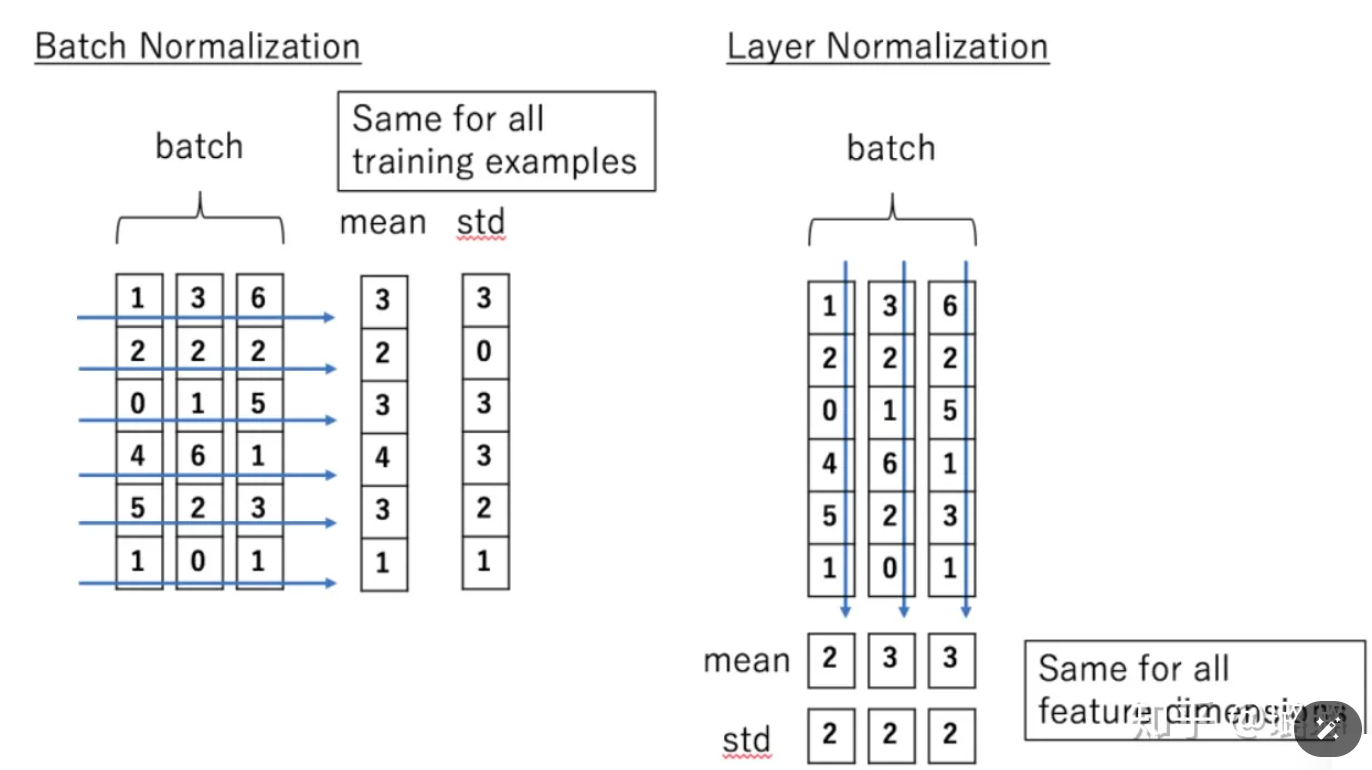
LayerNorm:
将单个样本特征进行均值方差归一化的Layer
FFN(Feed Forward Network):
前馈网络,构成是 FC + Relu + FC。
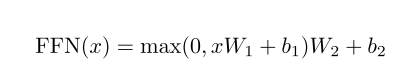
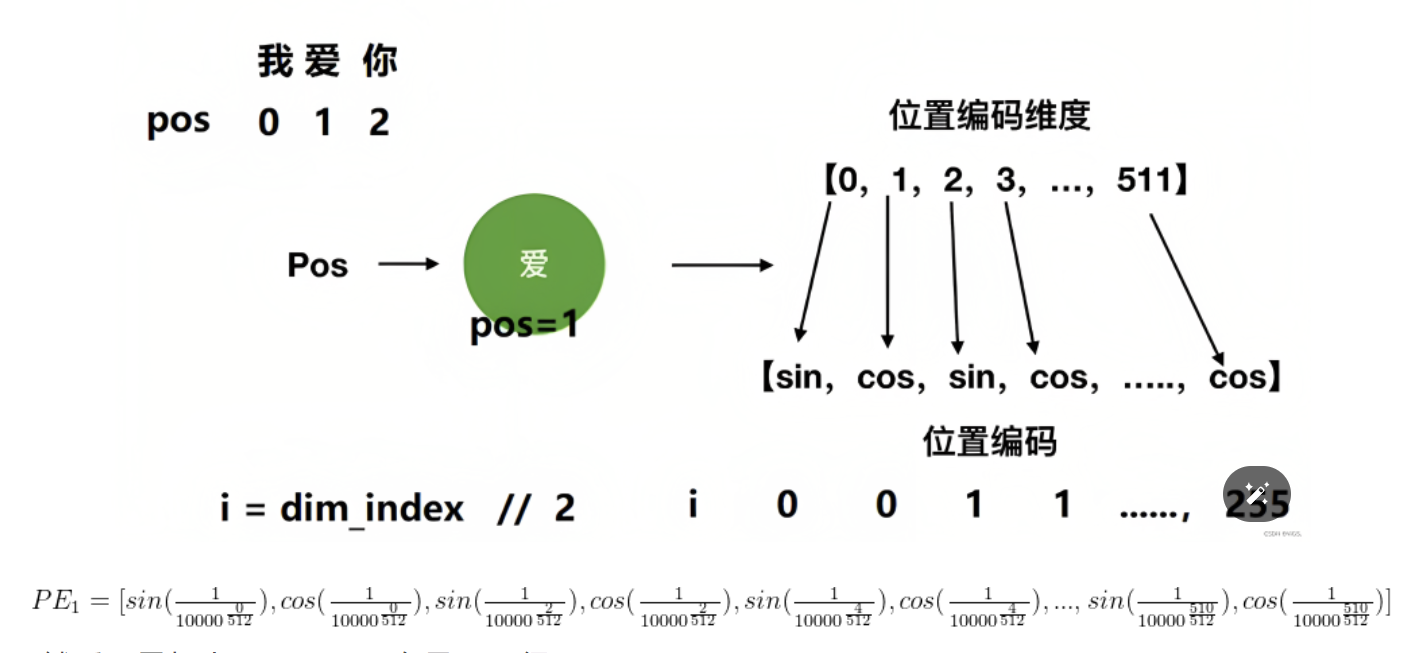
Position Encoding:
因为Self-Attention在前后特征融合时,是没有考虑时序信息的(加权平均过程,加法满足交换律),故词之间交换顺序结果也是一样的,比如,“我欠你100元”,与 “你欠我100元”使用Self-Attention算出的结果一样,但意思确是千差万别。所以需要手工引入Position信息,以下是标准positionEncoding方式。
Q&A
Q: Encoder与Decoder差别有什么差别?
a. Decoder中间需要使用cross attention从encoder输出提取信息。
b. Decoder首层使用Masked MultiHead Attention,不断将已经回归出来的结果作为新的输入,未回归到的位置被Mask掉,如此递归直到预测到End截止符。
c. Encoder适合Seq2Seq任务,Decoder适合AR自回归任务。
Q:GPT是Decoder-only网络结构,那么是否不用Encoder? 用户Prompt信息如何提取?
参考信息
李宏毅机器学习
一文通透位置编码
本文来自博客园,作者:fariver,转载请注明原文链接:https://www.cnblogs.com/fariver/p/18050972

 浙公网安备 33010602011771号
浙公网安备 33010602011771号