
数据库缓存池, 参考:
https://www.cnblogs.com/myseries/p/11307204.html
MySql 缓冲池(buffer pool) 和 写缓存(change buffer)
应用系统分层架构,为了加速数据访问,会把最常访问的数据,放在缓存(cache)里,避免每次都去访问数据库。
操作系统,会有缓冲池(buffer pool)机制,避免每次访问磁盘,以加速数据的访问。
MySQL作为一个存储系统,同样具有缓冲池(buffer pool)机制,以避免每次查询数据都进行磁盘IO。
碰到过的栗子:
select userid from xxxx where userid > :startUserId and status = 0 group by userid having sum(amount) >= 50 limit 100;
外系统脚本循环获取所有状态为0的,总金额大于等于50的userid, 接口超时时间5s,每个月跑一次。
现象:前几次总是会超时,多执行几次之后,就不超时了,因为存在缓存了,必定预读成功。
补充一点:mysql8.0版本取消了缓存。
取消缓存原因:
缺点:
-
MySQL会对每条接收到的SELECT类型的查询进行hash计算,然后查找这个查询的缓存结果是否存在。虽然hash计算和查找的效率已经足够高了,一条查询语句所带来的开销可以忽略,但一旦涉及到高并发,有成千上万条查询语句时,hash计算和查找所带来的开销就必须重视了。
-
Query Cache的失效问题。如果表的变更比较频繁,则会造成Query Cache的失效率非常高。表的变更不仅仅指表中的数据发生变化,还包括表结构或者索引的任何变化。
-
查询语句不同,但查询结果相同的查询都会被缓存,这样便会造成内存资源的过度消耗。查询语句的字符大小写、空格或者注释的不同,Query Cache都会认为是不同的查询(因为他们的hash值会不同)。
-
相关系统变量设置不合理会造成大量的内存碎片,这样便会导致Query Cache频繁清理内存。
对性能的影响
-
读查询开始之前必须检查是否命中缓存。
-
如果读查询可以缓存,那么执行完查询操作后,会查询结果和查询语句写入缓存。
-
当向某个表写入数据的时候,必须将这个表所有的缓存设置为失效,如果缓存空间很大,则消耗也会很大,可能使系统僵死一段时间,因为这个操作是靠全局锁操作来保护的。
-
对InnoDB表,当修改一个表时,设置了缓存失效,但是多版本特性会暂时将这修改对其他事务屏蔽,在这个事务提交之前,所有查询都无法使用缓存,直到这个事务被提交,所以长时间的事务,会大大降低查询缓存的命中。
缓冲池(buffer pool)
什么是预读?
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K(16K?)),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。
预读为什么有效?
数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
ps:Linux默认page是4K, mysql的索引页默认为16K(需要5次IO)
按页(4K(16K))读取,和InnoDB的缓冲池设计有啥关系?
(1)磁盘访问按页读取能够提高性能,所以缓冲池一般也是按页缓存数据;
(2)预读机制启示了我们,能把一些“可能要访问”的页提前加入缓冲池,避免未来的磁盘IO操作;
InnoDB是以什么算法,来管理这些缓冲页呢?
最容易想到的,就是LRU(Least recently used)。
画外音:memcache,OS都会用LRU来进行页置换管理,但MySQL的玩法并不一样。
传统的LRU是如何进行缓冲页管理?
最常见的玩法是,把入缓冲池的页放到LRU的头部,作为最近访问的元素,从而最晚被淘汰。这里又分两种情况:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;

如上图,假如管理缓冲池的LRU长度为10,缓冲了页号为1,3,5…,40,7的页。
假如,接下来要访问的数据在页号为4的页中:

(1)页号为4的页,本来就在缓冲池里;
(2)把页号为4的页,放到LRU的头部即可,没有页被淘汰;
画外音:为了减少数据移动,LRU一般用链表实现。
假如,再接下来要访问的数据在页号为50的页中:
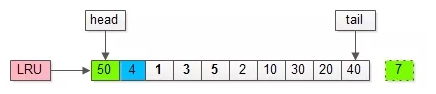
(1)页号为50的页,原来不在缓冲池里;
(2)把页号为50的页,放到LRU头部,同时淘汰尾部页号为7的页;
传统的LRU缓冲池算法十分直观,OS,memcache等很多软件都在用,MySQL为啥这么矫情,不能直接用呢?
这里有两个问题:
(1)预读失效: 由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
(2)缓冲池污染: 当某一个SQL语句,要批量扫描大量数据时,可能导致把缓冲池的所有页都替换出去,导致大量热数据被换出,MySQL性能急剧下降,这种情况叫缓冲池污染。
如何对预读失效进行优化?
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
(1)将LRU分为两个部分:
-
新生代(new sublist)
-
老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
-
如果数据真正被读取(预读成功),才会加入到新生代的头部
-
如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
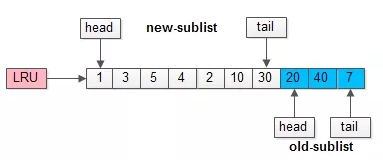
举个例子,整个缓冲池LRU如上图:
(1)整个LRU长度是10;
(2)前70%是新生代;
(3)后30%是老生代;
(4)新老生代首尾相连;

假如有一个页号为50的新页被预读加入缓冲池:
(1)50只会从老生代头部插入,老生代尾部(也是整体尾部)的页会被淘汰掉;
(2)假设50这一页不会被真正读取,即预读失败,它将比新生代的数据更早淘汰出缓冲池;
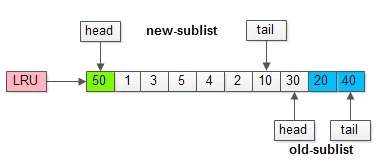
假如50这一页立刻被读取到,例如SQL访问了页内的行row数据:
(1)它会被立刻加入到新生代的头部;
(2)新生代的页会被挤到老生代,此时并不会有页面被真正淘汰;
改进版缓冲池LRU能够很好的解决“预读失败”的问题。
画外音:但也不要因噎废食,因为害怕预读失败而取消预读策略,大部分情况下,局部性原理是成立的,预读是有效的。
新老生代改进版LRU仍然解决不了缓冲池污染的问题。
如何解决大量数据导致的缓存池污染问题?
MySQL缓冲池加入了一个“老生代停留时间窗口”的机制:
(1)假设T=老生代停留时间窗口;
(2)插入老生代头部的页,即使立刻被访问,并不会立刻放入新生代头部;
(3)只有满足“被访问”并且“在老生代停留时间”大于T,才会被放入新生代头部;
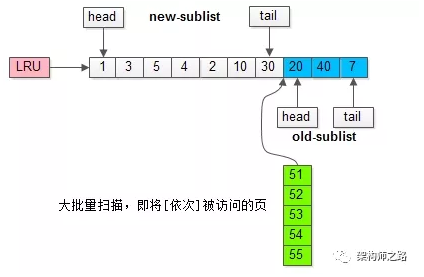
继续举例,假如批量数据扫描,有51,52,53,54,55等五个页面将要依次被访问。
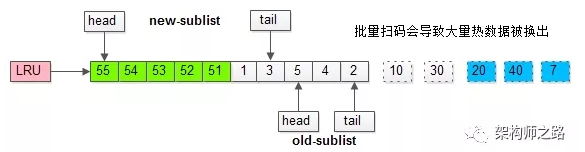
如果没有“老生代停留时间窗口”的策略,这些批量被访问的页面,会换出大量热数据。
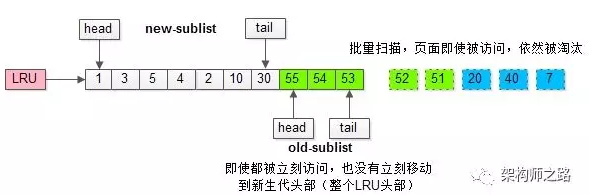
加入“老生代停留时间窗口”策略后,短时间内被大量加载的页,并不会立刻插入新生代头部,而是优先淘汰那些,短期内仅仅访问了一次的页。
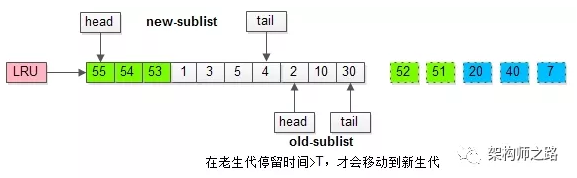
而只有在老生代呆的时间足够久,停留时间大于T,才会被插入新生代头部。
上述原理,对应InnoDB里哪些参数?
有三个比较重要的参数。
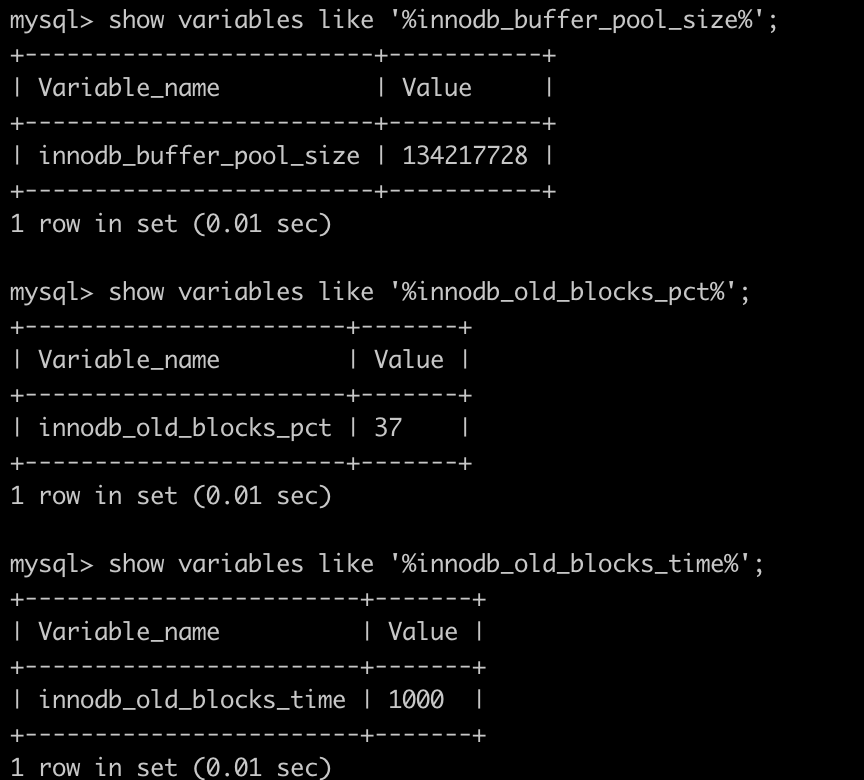
参数:innodb_buffer_pool_size (show variables like '%innodb_buffer_pool_size%';)
介绍:配置缓冲池的大小,在内存允许的情况下,DBA往往会建议调大这个参数,越多数据和索引放到内存里,数据库的性能会越好。
参数:innodb_old_blocks_pct (show variables like '%innodb_old_blocks_pct%';)
介绍:老生代占整个LRU链长度的比例,默认是37,即整个LRU中新生代与老生代长度比例是63:37。
画外音:如果把这个参数设为100,就退化为普通LRU了。
参数:innodb_old_blocks_time (show variables like '%innodb_old_blocks_time%';)
介绍:老生代停留时间窗口,单位是毫秒,默认是1000,即同时满足“被访问”与“在老生代停留时间超过1秒”两个条件,才会被插入到新生代头部。
总结:
(1)缓冲池(buffer pool)是一种常见的降低磁盘访问的机制;
(2)缓冲池通常以页(page)为单位缓存数据;
(3)缓冲池的常见管理算法是LRU,memcache,OS,InnoDB都使用了这种算法;
(4)InnoDB对普通LRU进行了优化:
-
将缓冲池分为老生代和新生代,入缓冲池的页,优先进入老生代,页被访问,才进入新生代,以解决预读失效的问题
-
页被访问,且在老生代停留时间超过配置阈值的,才进入新生代,以解决批量数据访问,大量热数据淘汰的问题
写缓存(change buffer)
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
什么业务场景,适合开启InnoDB的写缓冲机制?
先说什么时候不适合,如上文分析,当:
(1)数据库都是唯一索引;
(2)或者,写入一个数据后,会立刻读取它;
这两类场景,在写操作进行时(进行后),本来就要进行进行页读取,本来相应页面就要入缓冲池,此时写缓存反倒成了负担,增加了复杂度。
什么时候适合使用写缓冲,如果:
(1)数据库大部分是非唯一索引;
(2)业务是写多读少,或者不是写后立刻读取;
可以使用写缓冲,将原本每次写入都需要进行磁盘IO的SQL,优化定期批量写磁盘。
画外音:例如,账单流水业务。
复习一下数据库的ACID特性和实现机制:
MySQL 作为一个关系型数据库,以最常见的 InnoDB 引擎来说,是如何保证 ACID 的。
- (Atomicity)原子性(靠undo log,回滚日志保证): 事务是最小的执行单位,不允许分割。原子性确保动作要么全部完成,要么完全不起作用;
- (Consistency)一致性(靠其他三个特性保证+业务逻辑代码正确(事务中不要把catch异常)): 执行事务前后,数据保持一致;
- (Isolation)隔离性(锁 和 MVCC): 并发访问数据库时,一个事务不被其他事务所干扰。
- (Durability)持久性(靠内存+redo log保证): 一个事务被提交之后。对数据库中数据的改变是持久的,即使数据库发生故障。
原子性(undo log)
当事务对数据库进行修改时,InnoDB会生成对应的 undo log;如果事务执行失败或调用了 rollback,导致事务需要回滚,便可以利用 undo log 中的信息将数据回滚到修改之前的样子。undo log 属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB 会根据 undo log 的内容做与之前相反的工作:
- 对于每个 insert,回滚时会执行 delete;
- 对于每个 delete,回滚时会执行insert;
- 对于每个 update,回滚时会执行一个相反的 update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
一致性
一致性是事务追求的最终目标,前问所诉的原子性、持久性和隔离性,其实都是为了保证数据库状态的一致性。当然,上文都是数据库层面的保障,一致性的实现也需要应用层面进行保障。
也就是你的业务,比如购买操作只扣除用户的余额,不减库存,肯定无法保证状态的一致。
持久性(redo log)
mysql修改数据的同时在内存和redo log记录这次的操作,宕机的时候可以通过redo log来恢复
简单执行过程:
InnoDB redo log写盘, InnoDB事务进入prepare状态.
如果前面prepare成功, binlog写盘, 再继续将事务日志持久化到binlog, 如果持久化成功,那么InnoDB事务则进入commit状态(在redo log中写一个commit记录)
redo log的刷盘会在系统空闲时进行
为何要刷盘,不是直接写?
redo log采用磁盘顺序写(因就一个文件,在文件末尾追加,很少删除,性能相当高,接近内存随机读. eg:kafka、RocketMQ等能实现每秒几十万的读写), 通过bufferpool和redolog
ibd文件(数据表数据)是随机写(需要找不同的表的不同文件,且存在删除等操作)
mysql执行过程(基于InnoDB引擎)
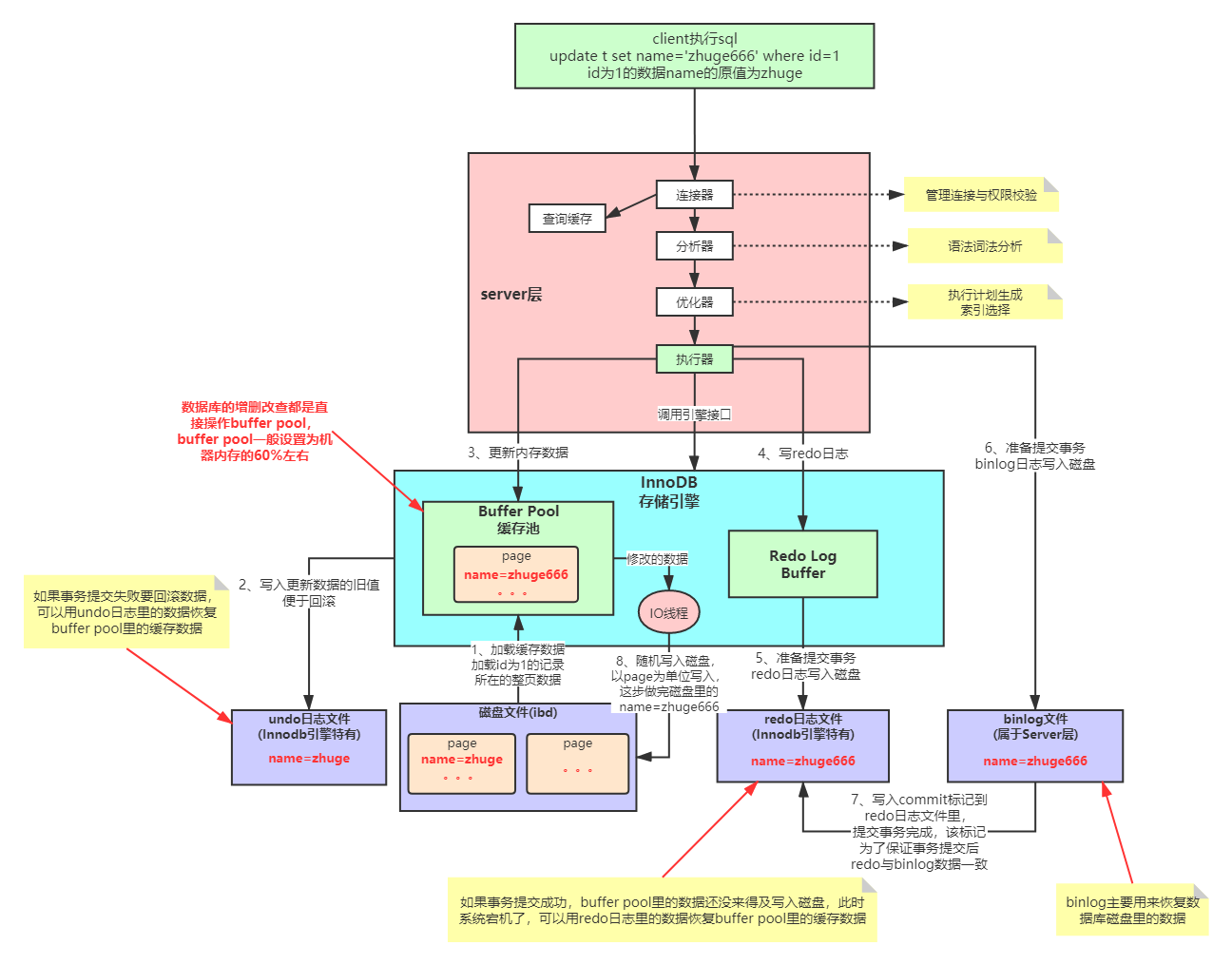
一条SQL更新语句怎么运行?
持久性肯定和写有关,MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘。就像小店做生意,有个粉板,有个账本,来客了先写粉板,等不忙的时候再写账本。
redo log
redo log 就是这个粉板,当有一条记录要更新时,InnoDB 引擎就会先把记录写到 redo log(并更新内存),这个时候更新就算完成了。在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,这就像打烊以后掌柜做的事。
redo log 有两个特点:
- 大小固定,循环写
- crash-safe
对于redo log 是有两阶段的:commit 和 prepare 如果不使用“两阶段提交”,数据库的状态就有可能和用它的日志恢复出来的库的状态不一致. 好了,先到这里,看看另一个。
Buffer Pool
InnoDB还提供了缓存,Buffer Pool 中包含了磁盘中部分数据页的映射,作为访问数据库的缓冲:
- 当读取数据时,会先从Buffer Pool中读取,如果Buffer Pool中没有,则从磁盘读取后放入Buffer Pool;
- 当向数据库写入数据时,会首先写入Buffer Pool,Buffer Pool中修改的数据会定期刷新到磁盘中。
Buffer Pool 的使用大大提高了读写数据的效率,但是也带了新的问题:如果MySQL宕机,而此时 Buffer Pool 中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性无法保证。
所以加入了 redo log。当数据修改时,除了修改Buffer Pool中的数据,还会在redo log记录这次操作;
当事务提交时,会调用fsync接口对redo log进行刷盘。
如果MySQL宕机,重启时可以读取redo log中的数据,对数据库进行恢复。
redo log采用的是WAL(Write-ahead logging,预写式日志),所有修改先写入日志,再更新到Buffer Pool,保证了数据不会因MySQL宕机而丢失,从而满足了持久性要求。而且这样做还有两个优点:
- 刷脏页是随机 IO,redo log 顺序 IO
- 刷脏页以Page为单位,一个Page上的修改整页都要写;而redo log 只包含真正需要写入的,无效 IO 减少。
binlog
说到这,可能会疑问还有个 bin log 也是写操作并用于数据的恢复,有啥区别呢。
- 层次:redo log 是 innoDB 引擎特有的,server 层的叫 binlog(归档日志)
- 内容:redolog 是物理日志,记录“在某个数据页上做了什么修改”;binlog 是逻辑日志,是语句的原始逻辑,如“给 ID=2 这一行的 c 字段加 1 ”
- 写入:redolog 循环写且写入时机较多,binlog 追加且在事务提交时写入
binlog 和 redo log
对于语句 update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,直接用树搜索找到。如果 ID = 2 这一行所在数据页就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成
为什么先写 redo log 呢 ?
- 先 redo 后 bin : binlog 丢失,少了一次更新,恢复后仍是0。
- 先 bin 后 redo : 多了一次事务,恢复后是1。
隔离性(锁、MVCC)
MySQL数据库四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
参考:https://www.cnblogs.com/fjdingsd/p/5273008.html
1. Read UnCommitted(读未提交)
最低的隔离级别。一个事务可以读取另一个事务并未提交的更新结果。
2. Read Committed(读提交)
大部分数据库采用的默认隔离级别。一个事务的更新操作结果只有在该事务提交之后,另一个事务才可以的读取到同一笔数据更新后的结果。
3. Repeatable Read(重复读)
mysql的默认级别。整个事务过程中,对同一笔数据的读取结果是相同的,不管其他事务是否在对共享数据进行更新,也不管更新提交与否。
4. Serializable(序列化)
最高隔离级别。所有事务操作依次顺序执行。注意这会导致并发度下降,性能最差。通常会用其他并发级别加上相应的并发锁机制来取代它。
ps:查看数据库隔离级别(mysql 5.x为tx_isolation): show variables like '%transaction_isolation%';
锁
先来说说锁, MySQL 有多少锁。
粒度
从粒度上来说就是表锁、页锁、行锁。表锁有意向共享锁、意向排他锁、自增锁等。行锁是在引擎层由各个引擎自己实现的。但并不是所有的引擎都支持行锁,比如 MyISAM 引擎就不支持行锁。
行锁的种类
在 InnoDB 事务中,行锁通过给索引上的索引项加锁来实现。这意味着只有通过索引条件检索数据,InnoDB才使用行级锁,否则将使用表锁。行级锁定同样分为两种类型:共享锁和排他锁,以及加锁前需要先获得的意向共享锁和意向排他锁。
- 共享锁:读锁,允许其他事务再加S锁,不允许其他事务再加X锁,即其他事务只读不可写。
select...lock in share mode加锁。 - 排它锁:写锁,不允许其他事务再加S锁或者X锁。
insert、update、delete、for update加锁。
行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。
行锁的实现算法
Record Lock
单个行记录上的锁,总是会去锁住索引记录。
Gap Lock
间隙锁,想一下幻读的原因,其实就是行锁只能锁住行,但新插入记录这个动作,要更新的是记录之间的“间隙”。所以加入间隙锁来解决幻读。
Next-Key Lock
Gap Lock + Record Lock, 左开又闭。
锁之于隔离性
大致介绍了下锁,可以看到。有了锁,当某事务正在写数据时,其他事务获取不到写锁,就无法写数据,一定程度上保证了事务间的隔离。但前面说,加了写锁,为什么其他事务也能读数据呢,不是获取不到读锁吗?
MVCC
前面说到,有了锁,当前事务没有写锁就不能修改数据,但还是能读的,而且读的时候,即使该行数据其他事务已修改且提交,还是可以重复读到同样的值。这就是MVCC,多版本的并发控制,Multi-Version Concurrency Control。
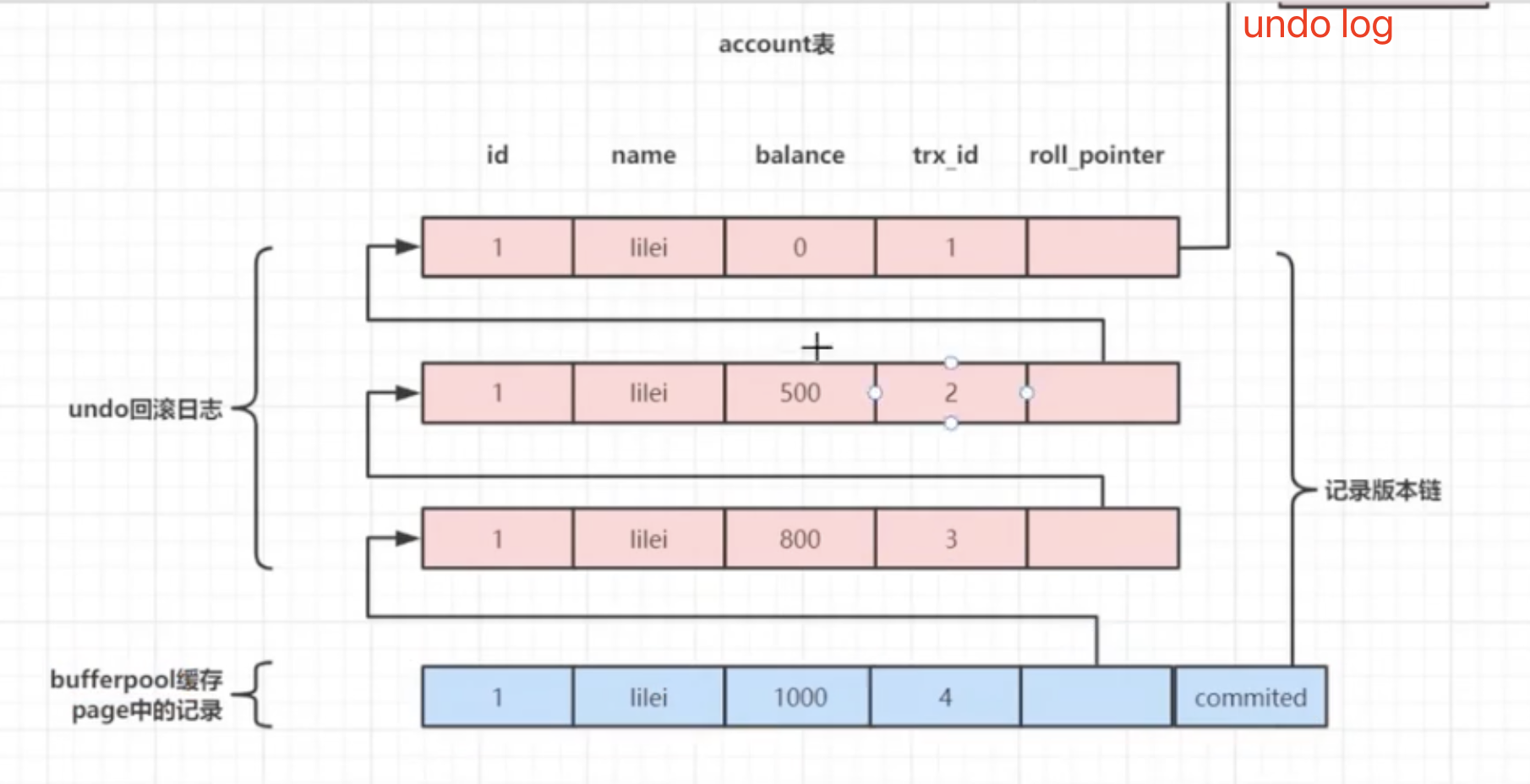
版本链
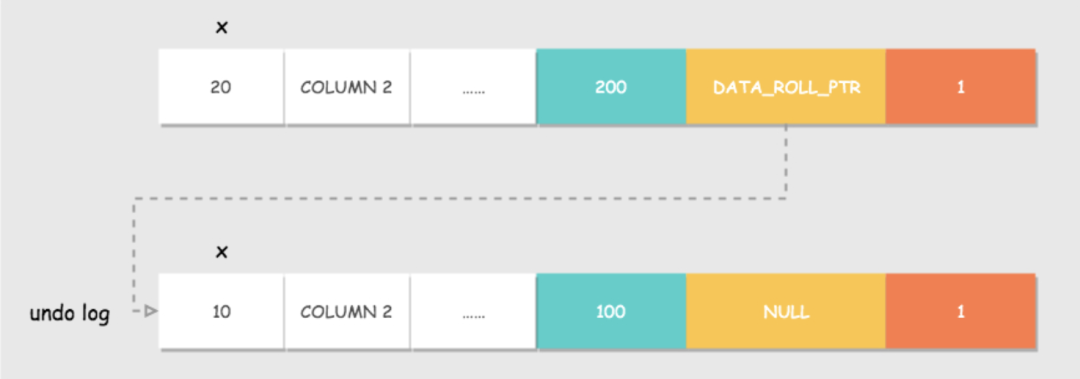
Innodb 中行记录的存储格式,有一些额外的字段:DATA_TRX_ID和DATA_ROLL_PTR。
- DATA_TRX_ID:数据行版本号。用来标识最近对本行记录做修改的事务 id。
- DATA_ROLL_PTR:指向该行回滚段的指针。该行记录上所有旧版本,在
undo log中都通过链表的形式组织。
undo log : 记录数据被修改之前的日志,后面会详细说。

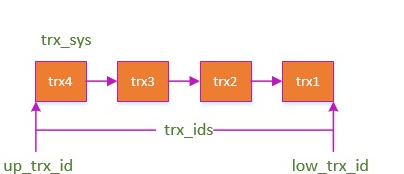
ReadView
在每一条 SQL 开始的时候被创建,有几个重要属性:
- trx_ids: 当前系统活跃(未提交)事务版本号集合。
- low_limit_id: 创建当前 read view 时“当前系统最大事务版本号+1”。
- up_limit_id: 创建当前read view 时“系统正处于活跃事务最小版本号”
- creator_trx_id: 创建当前read view的事务版本号;
开始查询
-
DATA_TRX_ID <up_limit_id :说明数据在当前事务之前就存在了,显示。
-
DATA_TRX_ID >= low_limit_id:
说明该数据是在当前read view 创建后才产生的,数据不显示。
- 不显示怎么办,根据 DATA_ROLL_PTR 从 undo log 中找到历史版本,找不到就空。
-
up_limit_id <DATA_TRX_ID <low_limit_id :就要看隔离级别了。
RR 级别的幻读
有了锁和 MVCC , 事务的隔离性得到解决。这里要引申一下,默认的 RR 的级别,解决了幻读吗?幻读通常针对的是 INSERT, 不可重复度则针对 UPDATE 。
| 事物 1 | 事物 2 |
|---|---|
| begin | begin |
| select * from dept | |
| - | insert into dept(name) values("A") |
| - | commit |
| update dept set name="B" | |
| commit |
我们期望是
id name
1 A
2 B
实际却是
id name
1 B
2 B
其实在 MySQL 可重复读的隔离级别中并不是完全解决了幻读的问题,而是解决了读数据情况下的幻读问题。而对于修改的操作依旧存在幻读问题,就是说 MVCC 对于幻读的解决时不彻底的。
MVCC简单解释:类似 (写入时复制)CopyOnWrite思想(COW)
像docker、nocos为了提升性能,都会用,包括高并发编程的时候,eg: CopyOnWriteArrayList/CopyOnWriteArraySet
每次更新时,新建一个副本,更新副本,更新完替换掉。(貌似PT大表sql也是类似的思想?)
eg:nocos作为注册中心,要修改一条数据时,防止出现ip修改了,端口还没修改,又不能影响正常读的问题(不用加锁)。 根本思想:读写分离。
栗子:
初始化数据:


1 CREATE TABLE `accounts` ( 2 `id` bigint(20) unsigned NOT NULL DEFAULT '0' COMMENT '主键id', 3 `type` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '账户类型', 4 `amount` decimal(12,2) NOT NULL DEFAULT '0.00' COMMENT '金额', 5 `ctime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', 6 `utime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', 7 `ver` mediumint(9) unsigned NOT NULL DEFAULT '1' COMMENT '版本号', 8 PRIMARY KEY (`id`) 9 ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 10 11 insert into `accounts` (`id`, `type`, `amount`, `ctime`, `utime`, `ver`) values (1, 1, 10000, '2022-01-01', '2022-01-02', 1); 12 insert into `accounts` (`id`, `type`, `amount`, `ctime`, `utime`, `ver`) values (2, 1, 50000, '2022-10-01', '2022-10-02', 1); 13 14 SELECT * from accounts; 15 16 17 SELECT @@transaction_isolation; 18 19 #设置数据库隔离级别 set transaction_isolation=''; 20 21 #read-uncommitted 22 #read-committed 23 #REPEATABLE-READ 24 #serializable 25 26 show variables like '%tx_isolation%'; 27 show variables like '%innodb_buffer_pool_size%'; 28 select @@global.tx_isolation; 29 show variables like '%tx_isolation%'; 30 show variables like '%transaction_isolation%'; 31 32 #查看数据库隔离级别(mysql 5.x为tx_isolation): show variables like '%transaction_isolation%';
窗口1操作:
1 set transaction_isolation='read-uncommitted'; 2 set transaction_isolation='read-committed'; 3 set transaction_isolation='REPEATABLE-READ'; 4 set transaction_isolation='serializable'; 5 6 show variables like '%transaction_isolation%'; 7 8 SELECT * from accounts; 9 10 11 #读未提交 12 set transaction_isolation='read-uncommitted'; 13 14 BEGIN; 15 update accounts set amount = amount - 1000 where id = 1; 16 #============= 17 ROLLBACK; 18 #COMMIT; 19 20 21 #读已提交 22 set transaction_isolation='read-committed'; 23 24 BEGIN; 25 update accounts set amount = amount - 1000 where id = 1; 26 #============= 27 COMMIT; 28 BEGIN; 29 update accounts set amount = 4000 where id = 1; 30 #============= 31 COMMIT; 32 33 #可重复读 34 set transaction_isolation='REPEATABLE-READ'; 35 36 BEGIN; 37 update accounts set amount = amount - 1000 where id = 1; 38 #============= 39 COMMIT; 40 BEGIN; 41 update accounts set amount = 45000 where id = 2; 42 update accounts set amount = 8000 where id = 1; 43 #============= 44 COMMIT; 45 46 #串行化 47 set transaction_isolation='serializable'; 48 49 BEGIN; 50 update accounts set amount = 6000 where id = 1; 51 #=============wait 52 COMMIT; 53 54 55 56 57 #锁,锁,锁 58 #读未提交实现串行化 59 set transaction_isolation='read-uncommitted'; 60 BEGIN; 61 #加读锁 62 SELECT * from accounts where id = 1 lock in share mode; 63 #wait!去下页update 64 COMMIT; 65 #写默认加锁 66 BEGIN; 67 update accounts set amount = 999 where id = 1; 68 #去下页select 69 COMMIT;
窗口2查看结果:
1 #!!!读未提交 2 set transaction_isolation='read-uncommitted'; 3 BEGIN; 4 SELECT * from accounts; 5 #COMMIT; 6 7 #!!!读已提交 (不可重复读!) 8 set transaction_isolation='read-committed'; 9 BEGIN; 10 #第一次查:6000 11 SELECT * from accounts where id = 1; 12 #上页事务第一次提交后,再查:5000 13 SELECT * from accounts where id = 1; 14 #上页事务第二次提交后,再查:4000 15 SELECT * from accounts where id = 1; 16 #COMMIT; 17 18 #!!!可重复读 19 set transaction_isolation='REPEATABLE-READ'; 20 BEGIN; 21 #第一次查:3000 22 SELECT * from accounts; 23 SELECT * from accounts where id = 1; 24 #包括不是查询的数据,也是之前的。 25 SELECT * from accounts where id = 2; 26 27 #会有脏写问题! 28 update accounts set amount = 18000 where id = 1; 29 30 #脏写解决方案 31 #乐观锁+CAS 32 BEGIN; 33 update accounts set amount = 6000 where id = 1 and ver = 1; 34 #update 会加写锁,会用最新的数据查出来再去减 35 update accounts set amount = amount - 1000 where id = 1; 36 COMMIT; 37 38 39 40 #串行化 41 set transaction_isolation='serializable'; 42 BEGIN; 43 #上页事务未提交,会等待 44 SELECT * from accounts where id = 1; 45 46 47 48 #锁,锁,锁 49 #读未提交实现串行化 (mysql就是读操作后面加个读锁 lock in share mode) 50 set transaction_isolation='read-uncommitted'; 51 52 BEGIN; 53 update accounts set amount = 888 where id = 1; 54 #不用commit,已经报错了 55 COMMIT; 56 BEGIN; 57 #加读锁 58 SELECT * from accounts where id = 1 lock in share mode; 59 COMMIT; 60 61 #读未提交实现串行化 (mysql就是读操作后面加个读锁 lock in share mode) 62 set transaction_isolation='read-uncommitted'; 63 64 BEGIN; 65 update accounts set amount = 888 where id = 1; 66 #不用commit,已经报错了 67 COMMIT; 68 BEGIN; 69 #加读锁 70 SELECT * from accounts where id = 1 lock in share mode; 71 COMMIT;
索引!!!
1、ICP(索引下推,mysql5.6之后)
show profiles; 显示执行时长
先查看是否打开:show variables like '%profiling%';
打开: set profiling = 1;
2、InnoDB引擎下,除主键索引是聚簇索引且叶子结点为全数据外,其他二级索引均为非聚簇索引,且叶子结点仅有索引和主键id。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号