
Spark大数据平台安装教程
一.Spark介绍
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是开源的类Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
二.安装Spark
环境:Docker(17.04.0-ce)、镜像Ubuntu(16.04.3)、JDK(1.8.0_144)、Hadoop(3.1.1)、Spark(2.3.2)
1.安装Hadoop
参考:Hadoop伪分布式模式安装
2.解压Spark
bigdata@lab-bd:~$ tar -xf spark-2.3.2-bin-without-hadoop.tgz
3.重名名conf/spark-env.sh.template为spark-env.sh
bigdata@lab-bd:~$ mv spark-2.3.2-bin-without-hadoop/conf/spark-env.sh.template spark-2.3.2-bin-without-hadoop/conf/spark-env.sh
4.编辑conf/spark-env.sh文件,增加如下变量
export JAVA_HOME=/home/hadoop/jdk1.8.0_144 export SPARK_DIST_CLASSPATH=$(/home/hadoop/hadoop-3.1.1/bin/hadoop classpath) export HADOOP_CONF_DIR=/home/hadoop/hadoop-3.1.1/etc/hadoop export PYSPARK_PYTHON=/usr/bin/python3.5
三.运行Spark
1.启动Hdfs服务
bigdata@lab-bd:~$ hadoop-3.1.1/sbin/start-dfs.sh
2.启动Yarn服务
bigdata@lab-bd:~$ hadoop-3.1.1/sbin/start-yarn.sh
3.交互模式运行pyspark
bigdata@lab-bd:~$ spark-2.3.2-bin-without-hadoop/bin/pyspark --master yarn --deploy-mode client 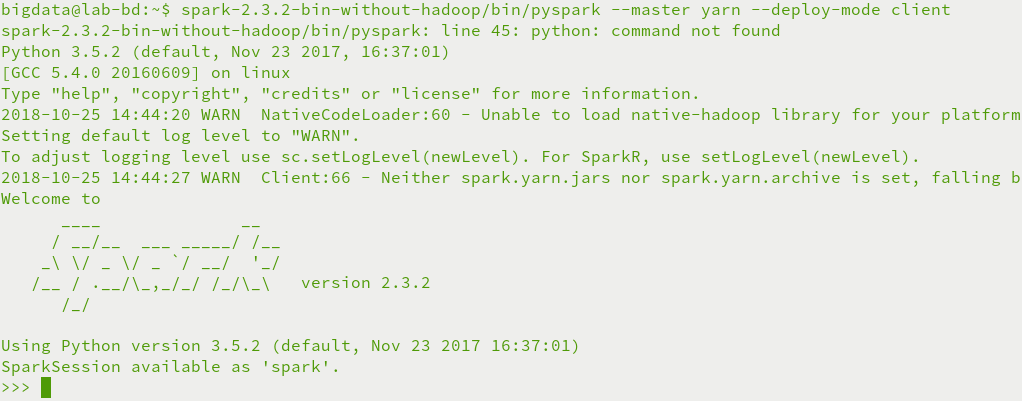
4.提交模式运行spark-submit
bigdata@lab-bd:~$ spark-2.3.2-bin-without-hadoop/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client \ > spark-2.3.2-bin-without-hadoop/examples/jars/spark-examples_2.11-2.3.2.jar
5.浏览器访问http://10.0.0.3:8088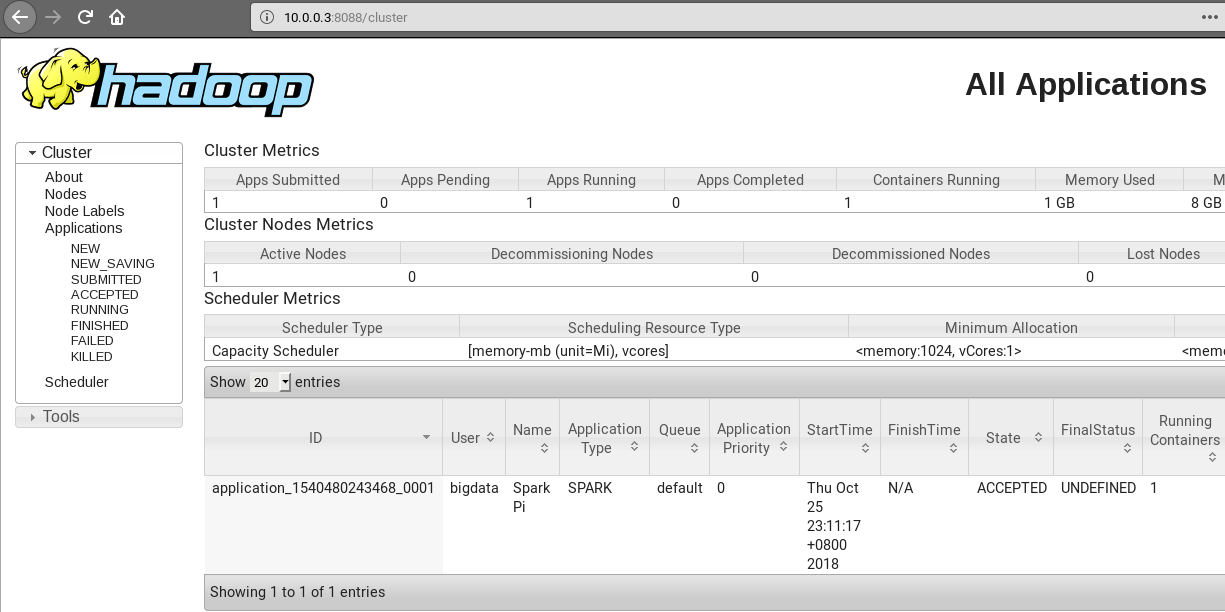
四.启动异常
1.Caused by: java.lang.ClassNotFoundException: org.slf4j.Logger异常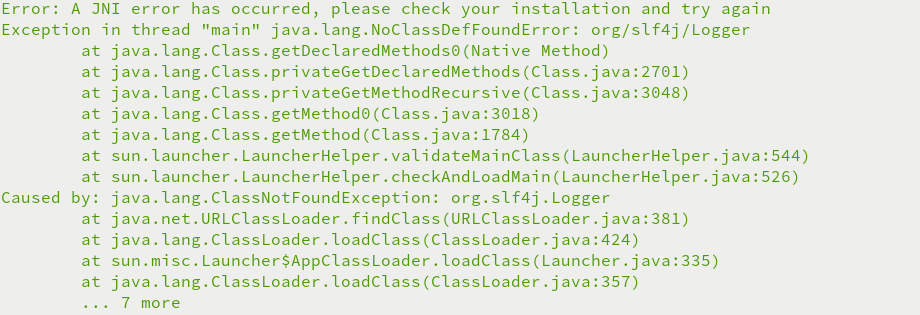
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无SPARK_DIST_CLASSPATH变量,无法关联hadoop
编辑conf/spark-env.sh文件,配置SPARK_DIST_CLASSPATH变量
export SPARK_DIST_CLASSPATH=$(/home/bigdata/hadoop-3.1.1/bin/hadoop classpath)
2.Exception in thread "main" java.lang.Exception: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment异常
Hadoop和Spark独立安装,Spakr运行需要Hadoop,无HADOOP_CONF_DIR变量,无法关联YARN
编辑conf/spark-env.sh文件,配置HADOOP_CONF_DIR变量
export HADOOP_CONF_DIR=/home/bigdata/hadoop-3.1.1/etc/hadoop
3.org.apache.spark.rpc.RpcEnvStoppedException: RpcEnv already stopped异常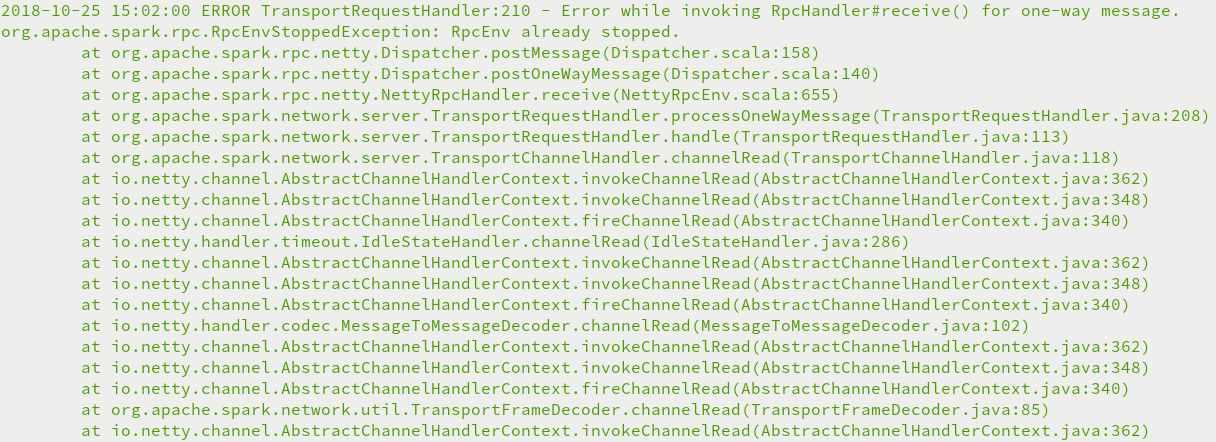
物理内存或者虚拟内存分配不够,Yarn直接杀死进程,需要禁止内存检查
编辑Hadoop中的etc/hadoop/yarn-site.xml文件,添加如下配置
<property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
4.env: 'python': No such file or directory错误
pyspark需要使用python,未配置PYSPARK_PYTHON变量
export PYSPARK_PYTHON=/usr/bin/python3.5
作者:faramita2016
出处:http://www.cnblogs.com/faramita2016/
本文采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

