

Hadoop伪分布式模式安装
一.Hadoop介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop的框架最核心的设计就是:HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算。
二.安装Hadoop
环境:Docker(17.04.0-ce)、镜像Ubuntu(16.04.3)、Hadoop(3.1.1)、JDK(1.8.0_144)
1.运行dockeer容器,指定IP
faramita2016@linux-l9e6:~> docker run -id --hostname lab-bd --net br0 --ip 10.0.0.3 ubuntu:ssh
2.在容器中执行,安装ssh、vim
root@lab-bd:~# apt-get update root@lab-bd:~# apt-get install -y ssh vim
3.新建bigdata用户(作为hadoop用户)
root@lab-bd:~# useradd bigdata -m -g root -c /bin/bash root@lab-bd:~# passwd bigdata root@lab-bd:~# su - bigdata
4.解压Jdk和Hadoop
bigdata@lab-bd:~$ tar -xf jdk-8u144-linux-x64.tar.gz bigdata@lab-bd:~$ tar -xf hadoop-3.1.1.tar.gz
5.编辑.bashrc文件,配置Java环境
export JAVA_HOME=/home/bigdata/jdk1.8.0_144 export PATH=$JAVA_HOME/bin:$PATH
6.激活Java环境变量
bigdata@lab-bd:~$ source .bashrc
7.编辑etc/hadoop/hadoop-env.sh文件,配置Java环境
export JAVA_HOME=/home/bigdata/jdk1.8.0_144
8.配置ssh免密登录
bigdata@lab-bd:~$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa bigdata@lab-bd:~$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys bigdata@lab-bd:~$ ssh localhost
9.编辑etc/hadoop/core-site.xml文件,添加如下配置
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
10.编辑etc/hadoop/hdfs-site.xml文件,添加如下配置
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
11.格式化文件系统
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hdfs namenode -format
12.启动hdfs服务
bigdata@lab-bd:~$ hadoop-3.1.1/sbin/start-dfs.sh
13.浏览器访问http://10.0.0.3:9870
三.配置Yarn
1.创建bigdata用户默认文件夹
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hdfs dfs -mkdir -p /user/bigdata
2.编辑etc/hadoop/mapred-site.xml文件,添加如下配置
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> </property> </configuration>
3.编辑etc/hadoop/yarn-site.xml文件,添加如下配置
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> </configuration>
4.启动Yarn服务
bigdata@lab-bd:~$ hadoop-3.1.1/sbin/start-yarn.sh
5.浏览器访问http://10.0.0.3:8088

四.运行任务
1.创建hadoop任务输入文件夹
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hdfs dfs -mkdir /user/bigdata/input
2.添加xml文件做为输入文本
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hdfs dfs -put hadoop-3.1.1/etc/hadoop/*.xml /user/bigdata/input
3.执行单词统计示例任务,input输入文件夹,output输出文件夹(自动创建)
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hadoop jar hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar grep input output 'had[a-z.]+'
4.查看单词统计输出结果
bigdata@lab-bd:~$ hadoop-3.1.1/bin/hdfs dfs -cat /user/bigdata/output/part-r-00000 
五.HDFS命令
1) ls 显示目录下的所有文件或者文件夹
示例: hdfs dfs –ls /
显示目录下的所有文件可以加 -R 选项
示例: hdfs dfs -ls -R /
2) cat 查看文件内容
示例: hdfs dfs -cat /user/bigdata/test.txt
3) mkdir 创建目录
示例: hdfs dfs –mkdir /user/bigdata/a
创建多级目录 加上 –p
示例: hdfs dfs –mkdir -p /user/bigdata/a/b/c
4) rm 删除目录或者文件
示例: hdfs dfs -rm /user/bigdata/test.txt
删除文件夹加上 -r
示例: hdfs dfs -rm -r /user/bigdata/a/b/c
5) put 将文件复制到hdfs系统中,
示例:hdfs dfs -put /tmp/test.txt /user/bigdata
6) cp 复制系统内文件
示例:hdfs dfs -cp /user/bigdata/test.txt /user/bigdata/a/
7) get 复制文件到本地系统
示例:hdfs dfs -get /user/bigdata/test.txt /tmp
8) mv 将文件从源路径移动到目标路径。
示例:hdfs dfs -mv /user/bigdata/a/test.txt /user/bigdata/b/test.txt
9) du 显示目录中所有文件的大小
示例: hdfs dfs -du /
显示当前目录或者文件夹的大小可加选项 -s
示例: hdfs dfs -du -s /user/bigdata
六.运行异常
running …… beyond the 'VIRTUAL' memory limit异常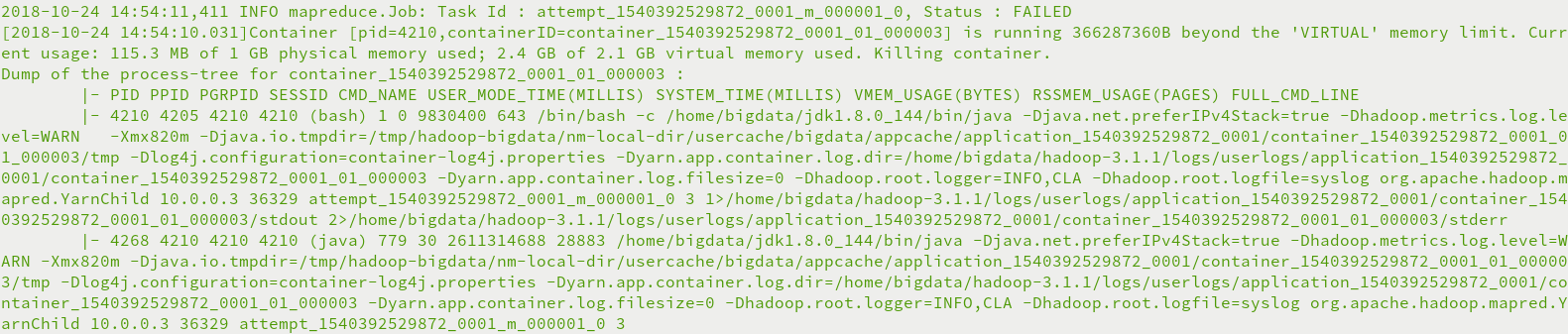
虚拟内存分配不够,Yarn直接杀死进程,需要禁止内存检查
编辑etc/hadoop/yarn-site.xml文件,添加如下配置
<configuration> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
作者:faramita2016
出处:http://www.cnblogs.com/faramita2016/
本文采用知识共享署名-非商业性使用-相同方式共享 3.0 中国大陆许可协议进行许可,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。

