


【论文笔记】Object detection with location-aware deformable convolution and backward attention filtering
&论文概述

&总结与个人观点
本文提出了location-aware deformable convolution以及backward attention filtering模块以提高自动驾驶中多类别多尺度目标检测的性能。其中location-aware deformable convolution能够自适应提取不均匀分布的上下文特征,与标准卷积特征结合以搭建为复杂场景中检测目标的健壮的、更具表征力的特征。Backward attention filtering模型利用深层卷积层中的高级语义特征以增强有信息的高分辨率特征同时抑制分散特征,提高了性能同时减少了需要的RoIs。通过在前向-后向网络中结合两个方法,在KITTI以及PASCAL VOC数据集中速度和性能均达到顶尖水准。
本文主要关注两个方面:上下文信息以及空间信息的精炼。分别使用位置感知的可变形卷积以及注意力机制,均是增强特征方面的操作;对问题的分析以及每一步的原由分析都很到位。
&贡献
- 提出location-aware可变形卷积来提取没有固定几何分布的上下文特征,提取的特征被用于增强标准卷积特征,从而提高检测性能;
- 提出backward attention filtering模型使用深层特征过滤浅层特征,强调informative特征同时抑制分散特征,使得RPN能够更容易生成合理的RoIs,因此减少了需要的RoI的数量从而提升模型速度;
- 将两个方法结合到forward-backward网络中,在KITTI以及PASCAL VOC数据集中性能和速度均达到顶尖水准。
&拟解决的问题
问题:上下文信息以及高分辨率特征在多尺度目标检测中有着重要的作用,但是上下文信息分布不均匀,高分辨率特征图中也包含distractive低级特征。
分析:先前的研究表明,在复杂场景的多尺度目标检测中,上下文信息以及高分辨率特征至关重要。最常用的提取上下文特征的方法是通过卷积层增大感受野,从而能够看到较大的区域;然而,上下文信息的分布并不均匀,同时也不是固定的。为了捕获上下文信息,不仅需要较大的感受野,还需要对输入的自适应的几何结构。标准卷积固定输入采样的网格,不能灵活处理上下文分布的多样性。可变形卷积引入位置偏移能够自适应地提取上下文特征。
在街景中CNN浅层的高分辨率特征往往是模糊且受干扰的,为了使检测器集中在目标上,需要强调有信息的特征,同时抑制噪音。使用卷积高层语义特征作为attention map以过滤高分辨率特征图是一个好的解决方案。
&框架及主要方法
1、 Main Structure
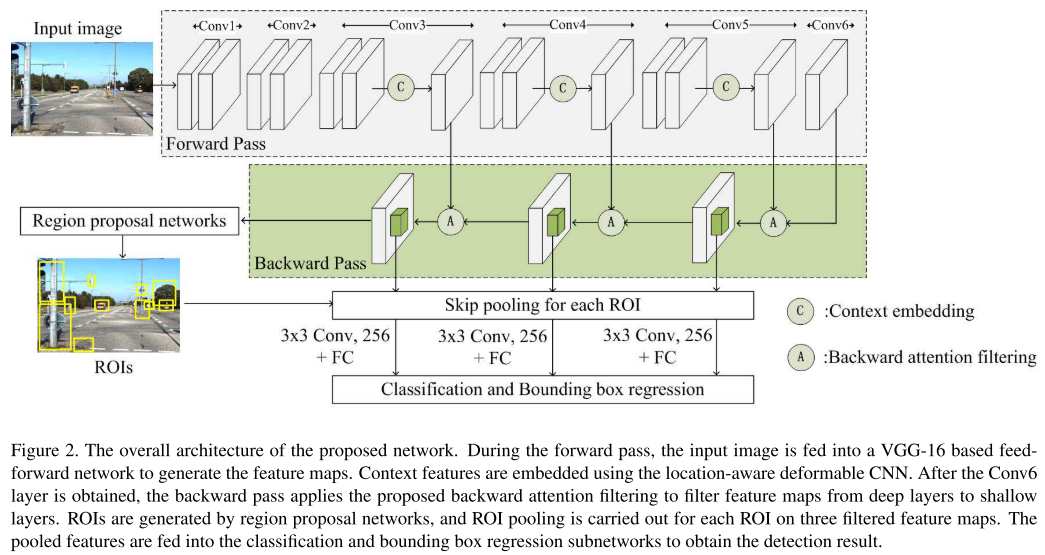
从现在的角度看,这个框架很容易理解,从backbone中提取出c1-c6,从c3开始使用location-aware deformable convolution以增强上下文信息,之后使用横向连接以及将上层特征作为注意力整合特征,显示信息较为丰富的区域,同时抑制噪声。之后使用skip pooling来整合特征进行预测。
2、 Location-aware deformable convolution


一般的可变形卷积,只有一个基于标准卷积相同感受野的卷积层来预测所有的offset。可是使用相同感受野以及卷积层对每个输入样本进行offset预测可能无法获得最优的结果;此外,感受野太小在offset预测时不能查看周围的特征,也使其不能捕获有用的上下文信息。因此提出location-aware deformable convolution:

其中I为输入特征,O为输出特征,D为膨胀率,pn为相对于中心的位置变化,如(-1, -1);
如上图所示,首先使用1×1的卷积来压缩通道至64,减少通道大小在维持计算开销上是必要的;然后膨胀卷积来扩大感受野,在每个卷积的位置上使用不同的卷积核以预测每个位置的偏移;之后由于预测的偏移通常是小数,使用插值以获得对应的特征值,最后计算加权和得到最终输出。
Location-aware deformable convolution的目的是为了获得更丰富的上下文信息,得到的结果需要与标准卷积的结果一起处理,将两者concatenate起来,然后使用1×1卷积压缩到原来的通道数组成最终的输出特征。
这里没有进行消融实验,看不出来这个方法对整体效果的提升有多大,同时我想要了解只使用location-aware deformable convolution,不加上standard convolution的结果会有什么效果。
3、 Backward attention filtering
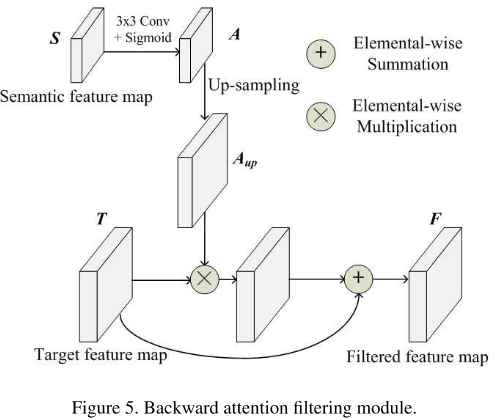
这里的注意力机制的使用很常规,直接将上层语义信息使用3×3卷积后进行sigmoid,作为注意力,然后上采样到对应大小与当前层特征相乘:

4、 Skip pooling

Skip pooling可以参考ION: Inside-Outside Net: Detecting Objects in Context with Skip pooling and recurrent neural networks一文中提出的skip pooling方法的使用。将池化扩展到多层中,需要考虑到维度以及幅度的问题:在ImageNet上的预训练表明,保存现有层的shape相当重要,因此最终的结果也应该为512×7×7;同时,为了匹配原始的shape,必须匹配原始的激活幅度。
首先将多层特征中的每一层使用RoI pool到512×7×7的大小,然后按通道进行拼接,使用1×1卷积压缩通道;为适应原始幅度,使用L2正则化,同时将rescale到需要的scale。
5、 Experiment
1) 对比+消融:使用相同backbone与faster R-CNN间的效果对比,以及模块间的消融实验结果。使用两个backbone,本文的方法效果对比Faster R-CNN均有较大的提高,最高分别提升2.9与3.4个点。每个模块的使用也都有相应的提升。其中(a)为仅使用location-aware deformable convolution,(b)仅使用backward attention filtering,(c)同时使用两个模块。

2) 对比+消融:Location-aware deformable convolution模块与一般的convolution以及deformable convolution间的对比,同时对比了不同膨胀率的结果。可见,最优的结果是使用膨胀率为2的膨胀卷积,使用标准卷积进行offset预测。

3) 对比实验:与其他使用attention机制的方法的对比。可见,本文提出的backward attention filtering的效果最佳。

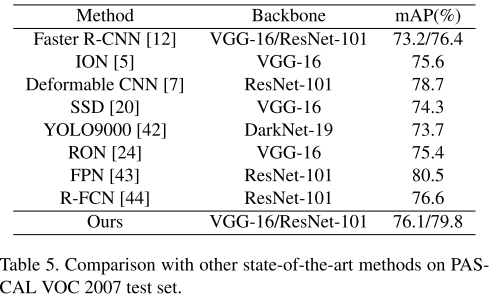
4) 对比实验:本文结果与其他方法的对比。可见,本文提出的虽不至于在效果上达到最优,但是均衡了速度与性能。

&遇到的问题
1、 当前的特征对结果的影响究竟在哪,只使用用于增强的方法的效果还比不上最初的结果,必须要加上当前的特征才能得到更好的结果?
2、 直接使用融合特征做预测,而不是使用多尺度训练,这样能够有效避免NMS处理多义性的问题吗?当前的效果比FPN的要差一些,是不是因为没有使用多尺度训练的原因,如果不使用skip pooling效果会不会好一些?
&思考与启发
看这篇论文主要是想要明白注意力机制是怎么使用的,当前自己尝试使用了几个注意力融入的方式效果均达不到想要的水准,此外,根据本文的想法,可以思考如何在特征融合过程中加入更丰富的上下文信息。

