


【论文笔记】Relation Networks for Object Detection
&论文概述

获取地址:https://arxiv.org/abs/1711.11575
代码链接:https://github.com/msracver/Relation-Networks-for-Object-Detection
&总结与个人观点
消融实验表明relation module能够学习在单独目标检测中丢失的目标间的关系。但是,relation module到底学到了什么并不明确,尤其是当多个堆叠在一起的时候。

在上图中展示了一些有较高关联权重的代表性例子,左边例子表明一些在相同ground truth上重叠的anchor对中心目标有贡献;右边例子表明人对手套有贡献。但这只是一些直觉,对relation module如何工作的理解还处于初级阶段。
本文首次将目标间的关系结合在目标检测模型中,虽然relation module的可解释性没有介绍清楚,但给目标检测方向引出了新的思路。
&贡献
- 提出轻量级及原位计算的relation module,通过一系列目标的特征以及几何形状,同时处理多个目标,以对他们之间的关系进行建模,能够嵌入到其他模型中。
- 使用duplicate removal step替换NMS,是第一个完全端到端的目标检测器。
&拟解决的问题
问题:先前的目标检测器独立识别目标实例,没有探索目标间的关系。
分析:目标检的关系很难建模。目标在图片中可能处于任意的位置,有着不同的尺度、不同的类别,且在不同的图片中数量差距也很大。
本文提出的方法受自然语言处理领域中attention module的成功启发:attention module能够通过聚合一系列元素(elements)的信息来影响独立的元素,如一句话中所有的单词与机器翻译的目标句子中的一个词。聚合权重通过任务目标自动学习。Attention module能够对元素间的依赖进行建模,不需要在他们的位置以及特征分布上有着较大的开销。
本文方法基于基础的自适应attention module,使用object替换原始的word,相比于1D的句子,目标有着2D的空间以及scale/aspect ratio的变化。因此将原先的attention weight扩展为两个部分:原始的weight以及新的geometric weight。后者对目标间的空间关系进行建模,同时只考虑他们之间的相对几何形状,使得模型具有平移不变性。
&框架及主要方法
1、 Main Structure
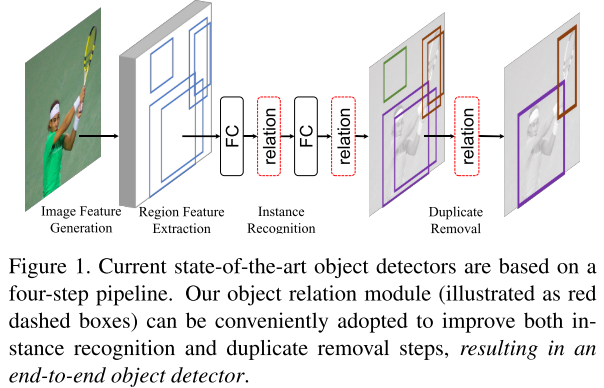
在实例识别过程中,relation module结合所有目标的推断(reasoning),提高识别的准确度。在冗余去除阶段,使用轻量级relation network取代以及改进传统的NMS,使得整体成为完全端到端的目标检测器。
2、 Object Relation Module
- Scaled Dot-Product Attention,放缩点积注意力,输入包含dk维度的查询(queries)及键(keys)以及dv维度的值(values)。在query以及所有的keys间的点积可获得其相似性,使用softmax函数来得到每个值(values)上的权重。
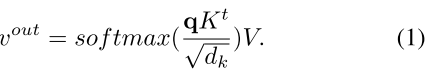
其中q为query,K为所有的keys,V是values。
定义目标是由其几何特征fG与外观特征fA组成,其中fG表示4d的bbox,fA负责task。给定N个目标,第n目标与全体目标几何的相关特征fR(n)计算如下:
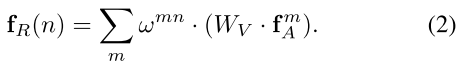
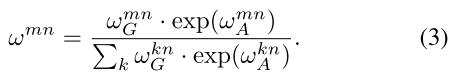
输出是通过WV对其他目标外观特征线性转换的加权和,同时WV是由上述(1)计算而来。相关权重wmn表示来自于其他目标的影响。外观权重通过点积计算,与(1)相似:
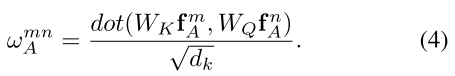
其中WK和WQ都是矩阵,与(1)中的K和q的作用相似。他们将原始的特征与分解为子空间来衡量其匹配程度,在分解后的特征维度为dk。
几何权重的计算如下:

首先,两个目标的几何特征被嵌入到高维表征,为使其具有平移不变性以及尺度转化,使用4d的相关几何特征:![]() ,在嵌入后的特征维度为dg。其次,使用WG将嵌入特征转换到标量权重,并通过ReLU非线性方法去除0。这个0去除方法只约束有着确切几何关系目标间的关系。
,在嵌入后的特征维度为dg。其次,使用WG将嵌入特征转换到标量权重,并通过ReLU非线性方法去除0。这个0去除方法只约束有着确切几何关系目标间的关系。
一个object relation module聚合了Nr个相关特征以及通过相加增强输入的外观特征:
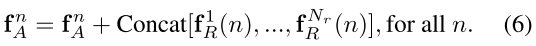
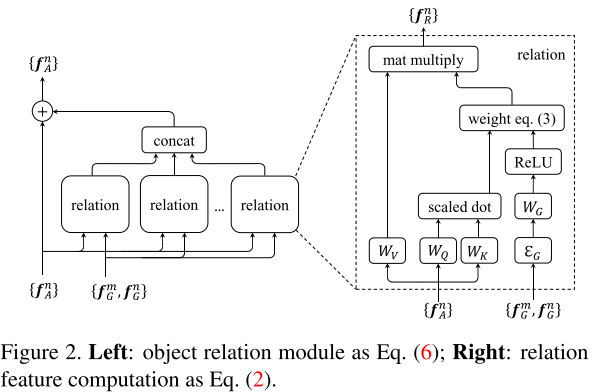

为匹配通道维度,每个的输出通道被设置为输入特征的。
3、 Relation for Instance Recognition
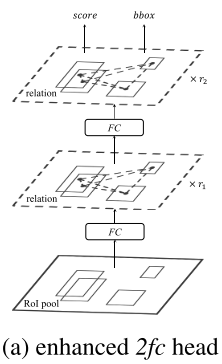
一般使用两层维度为1024的fc处理第n个候选区域的RoI池化特征,然后通过线性层进行分类于回归;而目标relation module也可以转换为所有候选区域的1024d特征,不需要改变特征的维度。


其中r1和r2分别表示relation module重复的次数。Relation module需要所有的候选区域的bbox作为输入。
4、 Relation for Duplicate Removal
NMS的简单、贪婪的天性以及成熟的选择参数使其明显是一个次优的选择。相比来说,duplicate removal简单且高效。
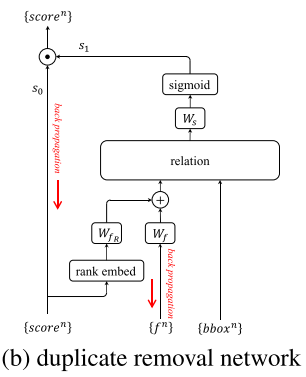
duplicate removal是二分类问题,对于每个ground truth,只有一个匹配到的目标为corrct,其他匹配到该目标的被分类为duplicate。可以通过上图中的网络进行分类,输入是检测目标的集合,每个目标有1024d的特征,分类得分s0,以及bbox。网络输出每个目标二分类的可能性。
网络共有3个步骤:1) 1024d特征于分类得分被融合以生成外观特征,2) 使用relation module将所有目标的外观特征进行转换,3) 通过线性分类器以及sigmoid函数,将每个目标被转换的特征得到可能性。
5、 Experiment
1) 消融实验:relation module的几何特征的使用、采用的相关特征的数量以及每次使用的模型的次数的实验对比。

首先,是使用几何特征的模型对比,none表示不使用几何特征,设置,unary表示将fG嵌入到高维空间中,加入到fA中形成新的外观特征,attention的权重设置与none相同。实验表明,使用加权的几何特征的效果更好。
在使用的相关特征数量方面,在Nr为16时达到最好的性能,在每个部分使用relation module的次数上,随着层数的增加,精度在不断提高。
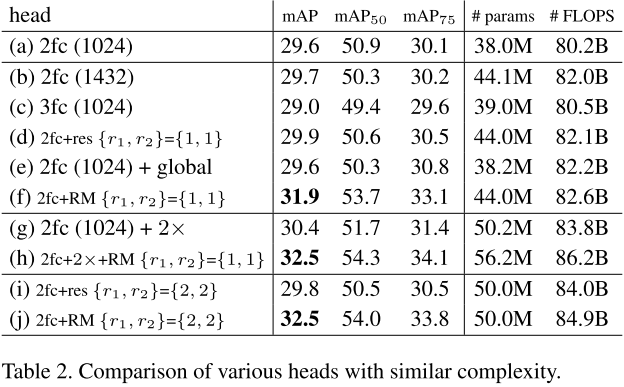
2) 比较:相同复杂度下各种head的性能比较,结果表明,使用relation module为head的模型性能最佳。
3) 消融实验:使用不同的后处理,rank fR表示将得分按从高到低的顺序转化为排行,标量的排行接着被嵌入到更高维的128d特征,使用与几何特征嵌入相似的方法。Rank特征与原始的1024d外观特征都被转换到128d,然后作为输入添加到relation module中。

4) 比较:与各种NMS方法的比较。最后一种e2e表示使用end-to-end方法进行训练。结果表明使用end-to-end的效果最好。
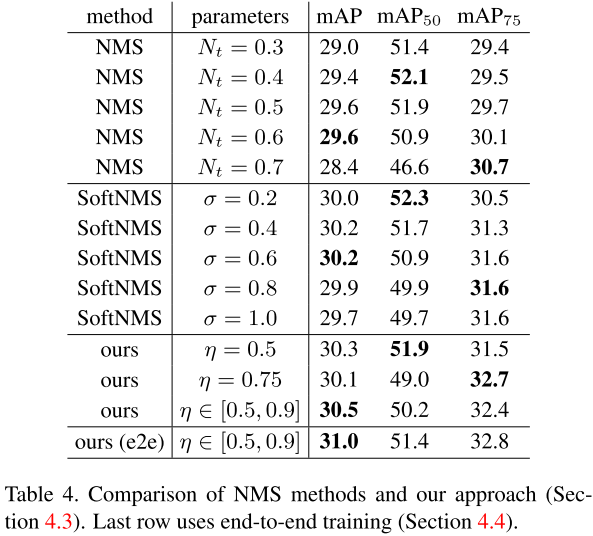
原因分析:end-to-end是否有用主要存在两个问题。
- 在实体识别以及冗余移除步骤中的目标存在冲突。前者是希望所有的目标能够匹配相同的ground truth以获得高得分,后者只希望其中一个如此。可能通过最终得分s0s1增加的行为消除了冲突,且使两者的目标互补。实体识别只需要为good detections产生高的分s0,冗余去除只需要为冗余产生低得分s1。大部分非目标或冗余的检测只要两个得分中有一个是correct,那么它就是correct。
- 冗余去除过程中的二分类ground truth标签依赖于实体识别步骤的输出,同时end-to-end训练过程中改变。在实验过程中却并未观察到由其不稳定性的反向影响,猜测是因为冗余移除网络相对来说容易训练,稳定的标签可能作为其中正则化的均值。
5) 比较:不同的backbone的改进效果对比。在每个backbone中比较3个策略的性能对比。结果表明,2fc+RM head+e2e过程在不增加较多计算量的同时能够提升较大的精度。

&思考与启发
先前的方法的后处理都是预先定义的,不能正常适应数据的变化,最终的结果显然并不是最优的,本文提出的relation module也应用于后处理中,使得整个网络能够end-to-end地进行训练。但是,本文提到的duplicate removal方法似乎需要将模型先前训练好,之后可以尝试将后处理过程也应用网络结构进行训练,但是要设计与整体匹配的loss,也许可以增强整体的性能。

