


【代码复现】CenterNet环境配置以及实现过程中出现的问题解决
这里提到的CenterNet指的是Keypoint Triplets for Object Detection,因为最近看了很多关于anchor-free的论文,其中也有很多如CornerNet、ExtremeNet、CenterNet使用的方法相似,而且网络的backbone使用的也相同,所以想要直接通过对CenterNet的理解来理解相关论文的实验流程。
Code Github:https://github.com/xingyizhou/CenterNet
&基本配置
配置流程在对应的github中都有介绍,在此也简单介绍一下:
1、搭建conda的虚拟环境
conda create --name CenterNet --file conda_packagelist.txt source activate CenterNet
2、编译代码
cd <dir>/models/py_utils/_cpools python setup.py install --user # 其中--user是为了python能够创建文件而不需要权限 cd <dir>/external make # 在进行下一步之前,需要建立在coco文件夹下建立对应的需要使用到的数据及信息 # 名称需要依照使用的模型文件中的定义,或者将配置文件中的定义改成自定义的名称 cd <dir>/data/coco/PythonAPI dake
& 问题及解决方案
首先,我使用的是4卡的服务器,但是成功运行时使用的是2个gpu,下面将我在配置此代码过程中遇到的主要问题进行介绍。而且在网上搜索相应内容的时候,网上的解决方案对我并不适用。
1、RuntimeError: CUDA error: out of memory
这个问题我遇到两种,第一种是在修改了文件中的一些配置,如相关的数据库的路径,以及threads的数量,然后直接运行代码就出现了下面的错误。

在遇到这个问题时,我以为是一般的0卡的内存不够用,然后在train.py中声明了CUDA_VISIBLE_DeVICES环境变量,只将当前占用较少的GPU显示表示,然后设置Threads为1。
这个方法在只有out of memory,或者是后面说明了当前使用的GPU还差多少内存的时候,才能使用,此时表明当前使用的GPU的大小或者数量不支持运算。
2、Runtime Error: CUDA error: invalid device ordinal
首先说明一点,使用的环境不一样,每个人的问题解决方案可能也是不同的,要仔细看问题报错的原因,以及看代码,比如在遇到这个问题的时候,我搜索了一下,基本上都是关于使用的device的问题,系统读取时是通过device(“cuda:1”)进行读取的,我将torch._C._scatter()的结果打印出来,确实在每一行的最后都跟随着一个device=1的标记。但是在整个项目中并没有出现device(“cuda:1”)的问题,因此按照网上给出的解决方法了调节一些参数,如将cudnn.enabled设置为False等等都是没用的。
而我这个问题是需要分析一下代码,错误信息在这里的作用也并不明显。需要注意我先前提到过的threads的数量与chunk的匹配关系,根据整体运行错误的分析,当前代码使用的多线程模式应当是静态分配,也就是一个chunk对应一个线程,而且在配置文件中所有的chunk的和,需要与batch_size的大小相匹配,如最终使用2个treads,那么此时就只能设置两个chunk,也就是配置文件中国的“chunk_size=[6, 6]”,对应的“batch_size”设置为12。当然在batch_size与chunk的和不匹配的时候,也会出现sum(chunk)=**, but ** expected的报错问题。
3、AttributeError: ‘NoneType’ object has no ‘cudaEventCreateWithFlags’
这个问题是出现在所有的问题基本上都调节好了之后运行代码时产生的,在网上也没有这个内容的详细解决方案,只能一步步看源码,一步步输出打印,跟着代码走的时候确实发现了一些不同之处,在运行的所有文件中也确实没有对于cudaEventCreateWithFlags的定义。
由于之前我也跑过mmdetection的代码,使用的也是多GPU模式,就参照了其使用DataParalell的代码,也的确在其中发现了一些不同寻常的地方:mmdetection中使用多GPU的代码,其中定义device_ids以及output_device的方法不一样,mmdetection中多出了_get_device_index函数,我就尝试着将代码进行了修改,在dataparalell.py中,具体如下:
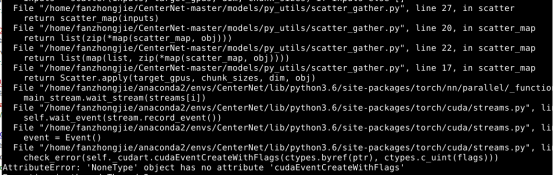
同时在这个代码的最后还要将mmdetection中utils的_get_device_index函数copy进来,以正常使用。
总结一下,最终修改的部分是在
- dataparalell.py的device_ids以及output_device;
- 项目默认使用的chunk_size是8组,如果使用的threads的数量不是8的话,可能需要进行修改,包括threads的数量、chunk_size以及batch_size;
- 如果再次运行出现out of memory,可以尝试修改CUDA_VISIBLE_DEVICES变量。

