


【总结 Anchor-free1】Anchor-Free Keypoint方法总结以及思路分析
这篇文章主要介绍了两个部分内容,一个是Anchor-based方法的缺陷,另外就是Anchor-free中基于Keypoint的方法的介绍
1、Anchor-based的shortcoming
2、Anchor-free方法以及具体思想
RepPoint
&Anchor-based的shortcoming
1) 使用anchor时,需要在每个特征尺度上密集平铺,而仅有很少一部分是正样本,即正负样本的比例差别很大;最终有很多计算都花费在无用样本,且一般使用时需要进行预处理,挖掘难负例;
2) 需要预定义的anchor size以及aspect ratio。检测性能会收到这些预定义的参数的影响,如果在每一个位置设定的anchor的数量太多,也会导致计算量成倍增长;
3) 使用axis-align的形式:
- 由于anchor是针对特征图上的点进行提取的,并不是所有的像素点上都会提取对应的anchor,且在每个点上提取的anchor的数量也不尽相同,如果只使用axis-align形式,最终结果可能对于那个bbox中心不在特征图上的点不大友好,最终影响整体的精度;当然,目前也有针对该问题做出的调整,如可以通过预测中心点偏移,参照RepDet中的Adaptive Convolution方法;
- 使用box来作为一个目标的回归结果,仍然会在其中包含大量的背景信息,尤其是在边角区域,而且对于斜放的细长目标会造成更大的影响。在这个方向上,也存在一些改进方式,如ExtremNet提出的使用八边形来描述一个目标,(Segmentation is All You Need)论文中也提出将目标的范围通过椭圆精细化。
&Anchor-free方法以及具体思想
1) YOLOv1
YOLOv1摒弃了anchor,使用grid来负责每一块区域的目标检测。主要思想就是将整张图片划分为S×S(7×7)个grid,每个网格检测B(2)个bbox。
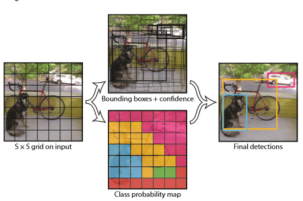
按照论文讲述的结果,先将图片resize到448×448;然后输入到CNN中,最终输出一个7×7×30的矩阵,其中30表示的是20个类别得分,2个回归框的信息(x, y, w, h, confidence);将最终的结果使用NMS进行处理。

显而易见,网上有人觉得这也是anchor的一种变种,但是,我认为这已经不再是anchor,反倒观点更接近于通过点来对bbox回归的思想。只不过YOLOv1是通过先将整张图片分成了多个网格,对应的中心落在该网格内的目标则由这个网格来回归。
Pros:
- 处理速度很快。YOLOv1的运行速度因为预处理部分很简单,只是简单地进行resize,之后直接使用CNN网络进行回归,在后处理中也只是用到了NMS,且最终得到的bbox回归框的个数极少。
- 降低背景误检。相比于anchor-based方法会提取很多的anchor出来,YOLOv1在运算过程中,会使用到的“anchor”相当少,至多只有7×7×2个。
Cons:
- 模型精度低。因为在运算中使用了很少的box,而且还定义了一个grid至多能识别的目标的数量,对于无目标与多目标存在同一个grid中的情况很不友好。且模型是从数据中学习预测bbox,最终对于新的或者不寻常的aspect ratio或者configuration的目标很难识别,由于使用了多层的卷积层,最终使用到的特征的信息很粗糙。
- 不适用于密集目标检测。同理。
- 有着很强的空间限制。因为YOLOv1在一个grid中至多只能识别两个目标,而且只能识别一个类。
- 损失函数等同对待小bbox以及大bbox的误差。
总而言之,YOLOv1可视为anchor-free论文的第一篇发迹文。之后就迎来了anchor-free方面论文的并发期,之后最基础的方法就是CenterNet以及CornerNet。
2) CenterNet
CenterNet的主要思想是通过中心点的信息来回归出其他bbox的属性,如中心点与四条边的距离、姿势、方向等信息。

首先,CenterNet会计算keypoint heatmap,然后通过网络直接回归出需要使用的信息。这种方法简单、快速、高效而且没有任何的NMS的后处理操作,可以直接端到端地进行训练。但是,只使用中心点进行回归,显然会使得获取的信息过少,可能不足以支撑回归出如此有效的信息,最终影响到检测性能。不过可能是由于其回归的信息很充分,增强了各种信息的表征能力使得能够对结果有所提升,【愚见,之后会重温】
3) CornerNet
相比CenterNet从中心点来回归出边界距离获得bbox来说,CornerNet反其道而行,直接使用两个角点:top-left,bottom-right,直接定义bbox,以一组角点来确定一个目标。

首先,CornerNet计算出top-left以及bottom-right两个heatmaps,其中分别表明图中的top-left以及bottom-right点的信息,然后通过embeded方法计算top-left集合以及bottom-right集合中点的距离,将距离最近的点分为一个组,作为最终的bbox。其中也是用了一些改进方法,如Corner-Pool,使得计算角点更精确。
当然,这种想法也很好,但是却不可避免地引入了分组的计算算法,增加了计算难度,同时与CenterNet类似,即便此时使用了两个角点的信息来确定一个bbox,此时的角点由于使用了Corner Pool方法融入了更多边的信息,不可避免地导致网络对于边更加敏感,而且忽略了更多的内部细节。
4) CenterNet-Triplets
这种方法粗略来看就相当于整合了Center以及Corner的信息,相当于在CornerNet的基础上增加了Center的信息作为其中一个判别标准。Corner的heatmaps的生成仍然像CornerNet中一样,只不过多增加一个分支为center heatmap,corner分组后需要判断其中是否包含有center heatmap中的点,没有就可以直接排除。剩下的与CornerNet相似。
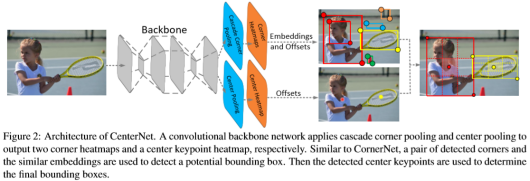
此外,考虑到corners对目标框中的内部信息把握不准,在CornerPool的基础上进行改进,提出了Cascade Corner Pool,使得corner也能编码一些内部的信息,增强了点的表征力;与此同时,提出了Center Pool,获得水平方向以及竖直方向上的最大值,也能够表示更多的信息。

但是,其一,我觉得使用的Cascade Corner Pool的方法的表义不明,即便在进行第二步的时候确实获取了一些框内的信息,增强了点的表征力,但是使用到的这个内部信息的表义却不是很明确,只能说明加入了一些内部信息时确实对结果产生了有利影响;其次使用到的信息仍然不够,尤其是对回归框的内部信息的使用,虽然使用到了center heatmap,但是最后只是用来做辨别,相当于没有完全利用这部分的信息。
因此在这个基础上是否可以将center的信息也利用进回归框的信息预测中,不过需要考虑一下怎么使用,而且ExtremeNet使用的方法与之也有相同之处。
5) ExtremNet
ExtremeNet使用到了4条边的极值点,以及中心点,在CenterNet-Triplets的基础上将预测的角点分解为边的极值点,同时分组不再按照embeded计算的距离,而是随机分组。
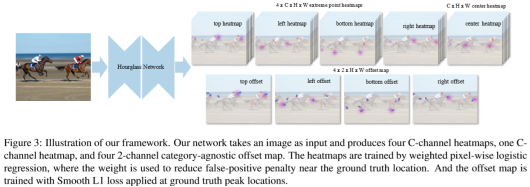
首先,网络计算得到5个heatmaps,分别为top、left、bottom、right以及center heatmap,其中top、left、right以及bottom仍然作为bbox获取的途径,每次从其中任取一个点作为一个bbox的四个极值点,然后计算其逻辑中心,如果在center heatmap中存在,则将之视为一个bbox,用作回归过程。
该方法,从分组的方式上来看,显然这个计算量是很大的。其余除了比CenterNet-Triplets多了一些边上的信息外,存在着与之相似的问题,而且网络对边缘的敏感更高。
整体来看,这个方法就是对CenterNet-Triplets方法的分解,将Corner的预测转化为极值点的预测,显然,这些点所能包含的信息会更多一些,但增加的信息也有限,不过给我们提供了一个优化结果的思路;将任务分解为更细致的任务,获取到更多信息以及分解任务间的关联性可能会对网络产生好的影响。
【注】之后会增加RepDet的内容,同时将使用的密集点检测的Anchor-free的方法也做进一步的总结。

