


【论文笔记】Cascade RPN:Delving into High-Quality Region Proposal Network with Adaptive Convolution
&论文概述

获取地址:https://arxiv.org/abs/1909.06720
&总结与个人观点
本文提出Cascade RPN,虽然简单但是在提高提高候选区域的质量以及目标检测性能上很有效的网络结构。Cascade RPN系统地解决由传统的RPN启发式地定义anchor以及将特征与anchor对齐产生的限制。一个简单的使用two-stage Cascade RPN的实现在AR上比baseline高出13.4个点,超过了现有的候选区域的方法。当将其应用到Fast R-CNN以及Faster R-CNN时,Cascade RPN在检测的mAP上对应提高3.1与3.5个百分点。
本文提出的Cascade RPN针对目前研究在改进RPN上遇到的问题,即anchor与特征的对齐问题作出修正,我认为本文最大的两点在于Adaptive Convolution的提出以及Cascade RPN的结构使得其能够直接使用上一个阶段得到的特征。
&贡献
1、提出了Adaptive convolution,使得其能够解决Deformable convolution出现的特征对齐计算不便的问题;
2、使用Cascade RPN对Iterative RPN的结构做了一些修正,使得其能够使用到上一阶段中更多的特征信息。
&拟解决的问题
问题:由传统RPN启发式定义anchor以及将特征与anchor对齐过程中产生的限制。
分析:
每个anchor由其scale以及aspect ratio定义,为了得到足够的正样本,需要一系列的scale以及aspect ratio的anchor集合,因此设置合适的scale以及aspect ratio对目标检测的性能至关重要,要求经过大量的调整。其中对齐原则被隐式定义为图像特征与其参考框间的响应,因此RPN与R-CNN的输入特征应当与被回归的bbox很好地对齐。在R-CNN中通过RoIPool层来确保对齐,在RPN中被启发式地确保:利用在特征图上RPN统一的卷积核strde来对anchor box进行统一地初始化,而这种启发式的方式也限制了检测性能的提高。
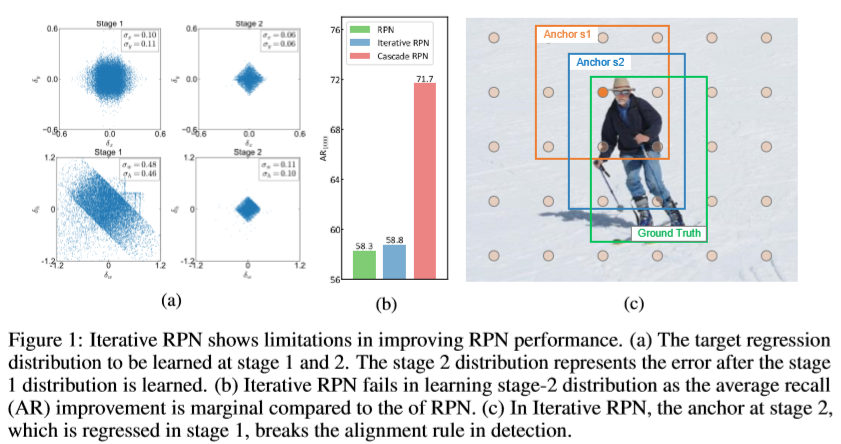
之前有大量的研究试图通过迭代地精炼以改善RPN,即iterative RPN。Anchor boxes作为回归使用的参考框被统一地初始化,而目标的ground truth却是任意地定位,因此RPN必须学习高偏差的回归分布,如上图中地(a)。如果这个回归分布被完美地学习,则在stage 2中回归分布接近于Dirac Delta分布;然而,在stage 1中这种高偏差分布往往很难被学习,需要在stage 2中做回归。相比来说,stage 2的分布有着更低的偏差,因此能够更简单地学习,但是在Iterative RPN中却并未成功。而这个失利的原因也能从(b)中得出结论,因为Iterative RPN改善的性能相比于RPN来说很小。同时从(c)来看,在stage 1后,anchor被回归到更接近与ground truth,然而却破坏了检测中的对齐原则。
在本文中使用的Cascade RPN方法系统地解决了之前提到的问题:
1) 使用单个anchor,以及在定义正样本区域时结合anchor-based以及anchor-free的评估标准来提高检测性能,取代使用多尺度多纵横比的anchors;
2) 基于在每个stage之后的应用于精炼的anchor的自适应卷积,在从多阶段精炼收益的同时维持anchor boxes与特征之间的对齐。
&框架及主要方法
1、Main Structure

在上图中,包含了多种RPN的结构图,主要是用于从结构图中展示Cascade RPN的不同之处。
2、Iterative RPN
Cascade RPN是在基于Iterative RPN对于RPN进行改良的过程中引发的问题进行处理的,因此,首先需要了解一下Iterative RPN的情况。
根据之前提到的问题,Iterative RPN(2b)能够通过多次精炼来获得更精准的定位,但是由于anchor的位置以及形状在每次迭代之后都回发生变化,因此在anchor以及其表示的特征之间出现了误匹配问题,即破坏了目标检测中的对齐原则。
之后,为解决这个问题,也有研究使用了可变形卷积来学习特征空间的转换(2c、2d),希望能够习得anchor几何形状的对应变换,然而却没有明确的监督来学习特征变换,因此很难确定最终的性能提高究竟是来自于对对齐原则的规整还是依赖于可变形卷积自身带来的益处。
3、Adaptive Convolution
针对于一般的卷积操作,取3×3的卷积核,在每次卷积计算中,输出的特征结果y为:
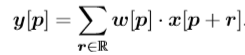
其中R表示标准网格,R={(rx, ry)},在标准卷积中,R={(-1, -1), (-1, 0),..., (0, 1), (1, 1)},表示3×3卷积以及膨胀率为1的 位置变化。而在自适应卷积中,标准网格R被偏移区域O替换:

使用a表示anchor在特征图中的映射。则偏移o可以解耦为center偏移以及shape偏移(具体如2e所示,中心偏移直接移动预定义anchor的中心,shape偏移相当于膨胀卷积的扩展):

其中,octr=(ax-px, ay-py),oshp通过anchor的shape以及卷积核的size进行定义,如取卷积核size为3×3,则:


上图为自适应卷积与标准卷积、膨胀卷积以及可变形卷积的对比,通过上图可以发现,可变形卷积只学习了每个位置的偏移,对于形状的变化并不关注,因此最终还需要学习对应的anchor的形状变化的转换,而自适应卷积首先学习一个中心的偏移,在这个基础上,再对每个点进行偏移变换,而此时的变化是由此时的anchor的尺寸决定的,即相当于进行了膨胀卷积的过程,只不过膨胀率是由anchor的尺寸决定,因此在anchor的取样过程中就能够保证anchor与其特征的对齐。
4、Cascade RPN
具体的Cascade RPN的结构图可以参见(2e)。Cascade RPN依赖于自适应卷积使得特征与anchor对齐,在第一个阶段,由于anchor的center偏移为0,此时的自适应卷积相当于膨胀卷积,因为特征的空间顺序能够被膨胀卷积保留下来,将第一阶段的特征桥接到下一个阶段中。

Cascade RPN的pipeline实现可根据上述算法得知,通过标黄的两行可以看出,最初的A被设置为最初的anchor,在每次迭代过程中,使用上一次迭代得到的经过偏移后的anchor进行运算,最终的结果使用NMS进行处理。

其多任务损失的计算主要是对迭代时候的bbox回归损失做了修正,每一次迭代使用不同的权重αт。
5、Experiment
1) 使用不同的候选区域提取方法在COCO 2017 val数据集中的实验对比,当然抛开backbone的因素,Cascade RPN还是表现出了很高的性能,几乎在每个AR上都能达到最好的效果。

2) 在Fast R-CNN与Faster R-CNN中使用文中提到的各种RPN相关的候选区域提取算法在COCO2017 test-dev数据集中的实验对比。结果显示,在整体上还是Cascade RPN占据优势,但在AP50上并没有表现出很好的性能。
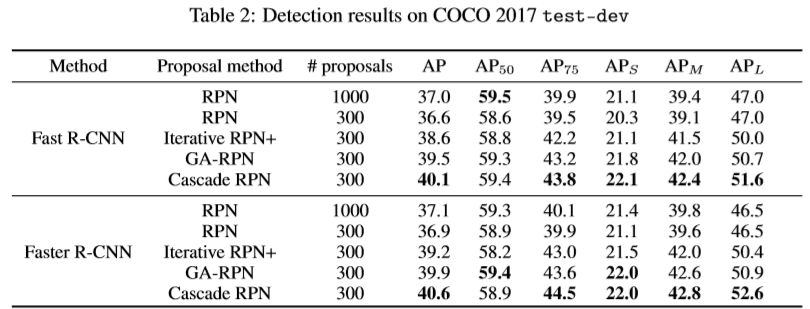
3) 消融实验1:分别测试了cascade RPN的各个部件对整体召回率的影响,从表格中可以明显看出在每增加一个使用策略,整体的AR都在增长,直到使用了所有的方法,最终AR比起baseline在每个proposal region的数量上都提升了10个百分点以上。

4) 消融实验2:测试alignment原则对整体AR的影响。从表中可以看出,使用了中心对齐以及形状对齐都对基础的AR有所增长,同时使用了两个对齐策略的结果AR比起最初增长了接近10个百分点。说明alignment在anchor-based方法中起到很大作用。

5) 消融实验3:使用不同的采样策略对结果的影响。从表中可以看出通过anchor-based方法的整体AR高于anchor-free,在同时使用两种方法在proposal region数量增多的时候效果会更好。

6) 消融实验4:在不同阶段上的整体AR对比。此时3阶段使用IoU=0.75,从表中可以看出,在Proposal region较多的情况下,更多的阶段会对AR产生正面影响,但对时间并不友好,折中时间以及AR的情况下,在使用1000proposals的情况下,选择2阶段会更好。

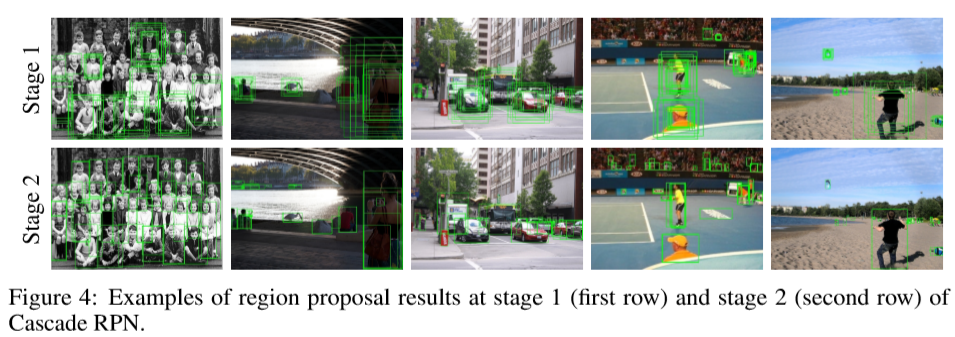
下面分别为2阶段Cascade RPN使用过程中生成的候选区域:
&遇到的问题
在这篇论文中遇到的问题,是之前没有补足的知识点,需要重温这些小知识。
1、关于R-CNN的问题,文中提到在R-CNN中是通过RoI Pool层来保证回归的bbox与输入的对齐,RoI Pool是为了使得每个RoI都归一到统一的尺度而已,如何实现对齐?
2、如何为每个点的像素计算objectness score?
&思考与启发
如果在计算oshp的时候不直接使用anchor的wight、height,而是直接作为超参数通过网络对其进行训练是不是能体现更好的性能,反向通过oshp来得到anchor?待我想想...

